Z tego artykułu dowiesz się na czym polega konfiguracja w .NET i jak odczytywać ustawienia na różne sposoby w swoich klasach (IOptions, IOptionsSnapshot, IOptionsMonitor), a także czym są opcje nazwane (named options).
Konfiguracja w .NET to nie tylko IConfigure, czy też IOptions. To naprawdę bardzo fajnie przemyślany mechanizm, który zdecydowanie warto poznać.
Na szybko (kliknij, by rozwinąć)
Jak odczytać ustawienia zagnieżdżone?
Posłuż się dwukropkiem, np. jeśli w plik appsettings.json masz konfigurację:
Na koniec możesz odczytać ich wartości w poszczególnych obiektach za pomocą IOptions<T>, IOptionsSnapshot<T> lub IOptionsMonitor<T> – szczegółowo to jest opisane niżej
Dlaczego .NET nie odczytuje zmiennych środowiskowych do konfiguracji?
Spokojnie, odczytuje. Jeśli uruchamiasz aplikację z wiersza poleceń przez dotnet run, to po zmianie zmiennych środowiskowych zrestartuj wiersz poleceń. Jeśli uruchamiasz z Visual Studio – to po zmianie zrestartuj Visual Studio. Szczegóły w treści artykułu.
appsettings, czy nie appsettings… – czyli dostawcy konfiguracji
Być może nie wiesz, ale w .NET nie musisz trzymać konfiguracji w pliku appsettings. Co więcej, NIE jest to zalecane miejsce dla danych wrażliwych – tak jak skrupulatnie przekonują Cię o tym tutoriale na YouTube.
Jest wiele miejsc, w których możesz trzymać swoją konfigurację (zwłaszcza wrażliwe dane) i sam nawet możesz dopisać własne mechanizmy (np. odczyt konfiguracji z rejestru przy aplikacji desktopowej).
Taki mechanizm odczytywania danych nazywa się configuration provider – czyli dostawca konfiguracji. W .NET masz do dyspozycji kilku takich dostawców, którzy są w stanie pobrać Twoją konfigurację z miejsc takich jak:
plik appsettings.json
zmienne środowiskowe
Azure Key Vault (polecam do trzymania danych wrażliwych)
argumenty linii poleceń
Odczytywanie konfiguracji
Tworząc aplikację poprzez WebApplication.CreateBuilder lub Host.CreateDefaultBuilder, dodajemy m.in. kilku domyślnych providerów, którzy odczytują konfigurację z różnych miejsc i wszystko umieszczają w jednym obiekcie IConfiguration (a konkretniej, to providerzy ze swoimi danymi siedzą w IConfiguration). Konfiguracja jest dostarczana w dwóch etapach (w kolejności):
Konfiguracja hosta, w której są odczytywane:
zmienne środowiskowe z prefixem DOTNET_
zmienne środowiskowe z prefixem DOTNET_ z pliku launchSettings.json
zmienne środowiskowe z prefixem ASPNETCORE_
zmienne środowiskowe z prefixem ASPNETCORE_ z pliku launchSettings.json (przy czym specjalna zmienna: ASPNETCORE_ENVIRONMENT wskazuje na aktualne środowisko (produkcja, development, staging -> to jest ładowane do HostingEnvironment. Jeśli tej zmiennej nie ma, to .NET traktuje to jako środowisko produkcyjne)
parametry z linii poleceń
Konfiguracja aplikacji – w tym momencie znamy już HostingEnvironment (czyli wiadomo, czy to produkcja, develop, staging…)
konfiguracja z pliku appsettings.json
konfiguracja z pliku appsettings.environment.json – gdzie „environment” to określenie aktualnego środowiska („Production”, „Development”, „Staging”…)
konfiguracja z secrets.json
wszystkie zmienne środowiskowe
Pamiętaj, żeby nigdy nie odczytywać aktualnego środowiska z konfiguracji: Configuration["ASPNETCORE_ENVIRONMENT"], bo może to być błędne. Środowisko jest trzymane w IHostingEnvironment i to tego powinieneś używać do odczytu.
Dlaczego możesz się na tym przejechać? Załóżmy, że ktoś z jakiegoś powodu wpisze ustawienie ASPNETCORE_ENVIRONMENT do pliku appsettings.json. I już będzie klops. Bo owszem, ustawienie w obiekcie IConfiguration zostanie „nadpisane”, jednak IHostingEnvironment będzie trzymał zupełnie inne dane.
Co z tymi zmiennymi środowiskowymi i co to launchSettings.json?
Dlaczego .NET nie odczytuje zmiennych środowiskowych?
Czasami możesz odnieść takie wrażenie, że to po prostu nie działa. Też tak miałem, dopóki nie zdałem sobie sprawy z tego, jak naprawdę działają zmienne środowiskowe.
Program odczytuje te zmienne w momencie swojego uruchamiania. I to jest najważniejsze zdanie w tym akapicie. Zmienne środowiskowe nie są „aktualizowane” w aplikacji. Jeśli uruchomisz swoją aplikację z wiersza poleceń (dotnet run), to Twój program otrzyma takie zmienne jakie otrzymał wiersz poleceń podczas swojego uruchamiania.
Jeśli uruchamiasz program z VisualStudio, to Twój program otrzyma takie zmienne, jakie dostał VisualStudio podczas swojego uruchamiania.
Dlatego, jeśli zmieniasz wartości zmiennych środowiskowych, pamiętaj żeby zrestartować wiersz poleceń / Visual Studio. Wtedy Twoja aplikacja dostanie aktualne zmienne.
Jeśli zmieniasz zmienne na poziomie IIS, zrestartuj IIS.
Jest to pewna upierdliwość. Dlatego mamy plik launchSettings.json, w którym możesz sobie poustawiać różne zmienne środowiskowe. Te zmienne będą odczytywane podczas każdego uruchamiania Twojego programu – nie musisz niczego restartować.
Oczywiście pamiętaj, że plik launchSettings.json służy tylko do developmentu. Więc jeśli poustawiasz tam jakieś zmienne, których używasz, pamiętaj żeby ustawić je też na środowisku produkcyjnym.
Nie zdradzaj tajemnicy, czyli secrets.json
Domyślne pliki z ustawieniami – appsettings.json i appsettings.Development.json są przesyłane do repozytorium kodu. Jeśli pracujesz w zamkniętym zespole, to nie ma to większego znaczenia – dopóki w programie nie używasz jakiś swoich prywatnych subskrypcji.
Jeśli w plikach appsettings trzymasz dane wrażliwe (connection stringi, hasła, klucze), to miej świadomość, że one będą widoczne w repozytorium kodu i KAŻDY z dostępem będzie mógł z nich skorzystać (w szczególności GitHub).
Dlatego też powstał plik secrets.json. Aby go utworzyć/otworzyć, kliknij w Visual Studio prawym klawiszem myszy na swój projekt i z menu wybierz Manage User Secrets:
Możesz też użyć .NetCli i wykonać polecenie dotnet user-secrets
Wywołanie w VisualStudio otworzy Ci edytor tekstu taki sam jak dla pliku appsettings. Zresztą secrets.json ma dokładnie taką samą budowę.
Różnica między secrets.json a appsettings.json jest taka, że secrets.json nie znajduje się ani w katalogu z kodem (leży gdzieś tam w AppData), ani w repozytorium. Więc możesz sobie w nim bezkarnie umieszczać wszystkie klucze, hasła itd, których używasz w programie.
Oczywiście możesz mieć różne pliki sekretów w różnych projektach.
Gdzie dokładnie leży plik secrets.json?
W takiej lokalizacji: AppData\Roaming\Microsoft\UserSecrets\{Id sekretów}\secrets.json
Id sekretów to GUID, który jest przechowywany w pliku (csproj) konkretnego projektu.
Kolejność konfiguracji
Jak już zapewne wiesz – .NET odczytuje konfigurację w konkretnej kolejności – opisanej wyżej. A co jeśli w różnych miejscach (np. appsettings.json i secrets.json) będą ustawienia, które tak samo się nazywają? Nico. Ustawienia, które odczytują się później będą tymi aktualnymi. Czyli jeśli w pliku appsetting.json umieścisz:
"tajne-haslo" : ""
I to samo umieścisz w pliku secrets.json, który jest odczytywany później:
"tajne-haslo" : "admin123"
To z konfiguracji odczytasz „admin123”.
Dla wścibskich
Tak naprawdę te wartości nie są nadpisywane i przy odrobinie kombinowania możesz odczytać konkretne wartości z konkretnych miejsc (jako że IConfiguration nie trzyma bezpośrednio tych wartości, tylko ma listę ConfigurationProviderów). Domyślnie .NET szuka klucza „od tyłu” – w odwrotnej kolejności niż były dodawane do IConfiguration, ale moim zdaniem może to być szczegół implementacyjny, który w przyszłości może ulec zmianie. Jednak nie czytałem dokumentacji projektowej.
Pobieranie danych z konfiguracji
Prawdopodobnie to wiesz. Do klasy Startup wstrzykiwany jest obiekt implementujący IConfiguration i wtedy z niego możemy pobrać sobie dane, które nas interesują:
To oczywiście podstawowe pobieranie danych z konfiguracji, przejdźmy teraz do fajniejszych rzeczy.
Tworzenie opcji dla programu
Dużo lepszym i fajniejszym rozwiązaniem jest tworzenie opcji dla komponentów Twojego programu. Załóżmy, że masz serwis do wysyłania e-maili. On może wyglądać tak:
public class EmailService
{
const string OPTION_SMTP_ADDRESS = "https://smtp.example.com";
const string OPTION_FROM = "Admin";
const string OPTION_FROM_EMAIL = "admin@example.com";
public void SendMail(string msg, string subject)
{
}
}
Tutaj najważniejsze jest to, jak masz nazwane poszczególne właściwości. Muszą być tak samo nazwane jak właściwości w Twojej klasie EmailOptions.
A w klasie EmailOptions to MUSZĄ być właściwości do publicznego odczytu i zapisu (nie mogą to być pola).
Jeśli już masz skonstruowaną klasę opcji (EmailOptions) i fragment konfiguracji (np. ten powyżej), możesz podczas konfiguracji serwisów dodatkowo skonfigurować te opcje:
Czyli mówisz: „Klasa EmailOptions ma trzymać dane odczytane z sekcji w konfiguracji o nazwie „EmailSettings”.
Od teraz możesz klasę EmailOptions z wypełnionymi wartościami wstrzykiwać do swoich obiektów na trzy sposoby… Każdy z nich ma swoje wady i zalety.
Interfejs IOptions<T>
To pierwszy sposób pobrania opcji i chyba najprostszy. Wystarczy, że wstrzykniesz IOptions<T> do obiektu, w którym chcesz mieć swoją konfigurację:
public class EmailService
{
EmailOptions options;
public EmailService(IOptions<EmailOptions> options)
{
this.options = options.Value; //pamiętaj, że opcje będziesz miał we właściwości Value
}
public void SendMail(string msg, string subject)
{
}
}
Zobacz jak sprytnie pozbyliśmy się tych brzydkich stałych z kodu na rzecz opcji trzymanych w odpowiednim obiekcie.
Plusy:
IOptions jest zarejestrowane jako singleton
Może być wstrzyknięte do każdego obiektu niezależnie od jego cyklu życia (Scoped, Singleton, czy Transient)
Minusy:
Odczytuje konfigurację TYLKO podczas uruchamiania systemu – to moim zdaniem jest najważniejsza kwestia. Przy niektórych opcjach to będzie wystarczające, przy innych nie.
Nie pozwala na „named options” (o tym za chwilę)
Interfejs IOptionsSnapshot<T>
Przykład wstrzyknięcia:
public EmailService(IOptionsSnapshot<EmailOptions> options)
{
this.options = options.Value;
}
Czyli dokładnie tak samo. Różnice natomiast są trzy.
Plusy:
daje Ci aktualne opcje – nawet jeśli zmienią się w pliku – bez konieczności restartu aplikacji
obsługuje „named options”, o czym później
Minusy:
zarejestrowane jako scoped – odczytuje opcje z każdym requestem, jednak nie wstrzykniesz tego do serwisów rejestrowanych jako singleton.
Interfejs IOptionsMonitor<T>
To wygląda trochę jak hybryda dwóch poprzednich interfejsów.
jest rejestrowany jako singleton, więc może być wstrzyknięty do serwisu niezależnie od jego cyklu życia
potrafi zaktualizować opcje, gdy się zmienią – bez restartu aplikacji
obsługuje „named options”
Użycie tego jest nieco bardziej skomplikowane. Oto przykład:
Pierwsza różnica jest taka, że nie trzymasz w swoim serwisie obiektu klasy EmailOptions tak jak to było do tej pory. Zamiast tego trzymasz cały monitor. A gdy potrzebujesz odczytać AKTUALNE opcje, posługujesz się właściwością CurrentValue tego monitora.
Teraz jeśli opcje fizycznie zostaną zmienione (np. w pliku appsettings.json), tutaj będziesz miał aktualne wartości – bez potrzeby restartowania aplikacji.
UWAGA! Zmiany zmiennych środowiskowych nie będą uwzględnione.
Masz tutaj różne ustawienia dla maili serwisowych i newslettera. Nie musisz tworzyć całej takiej struktury klas. Zwróć uwagę na to, że zarówno ServiceMailing jak i NewsletterMailing mają dokładnie takie same pola. Dokładnie też takie, jak klasa EmailOptions.
Możesz się tutaj posłużyć IOptionsSnapshot lub IOptionsMonitor, żeby wydobyć konkretne ustawienia (przypominam – IOptions nie obsługuje named options).
Najpierw trzeba jednak skonfigurować opcje, przekazując ich nazwy:
w pierwszym parametrze podajesz „nazwę zestawu opcji” – po tej nazwie będziesz później pobierał opcje do obiektu
w drugim pobierasz konkretną sekcję, w której są umieszczone te dane (tak jak do tej pory)
Teraz możesz odpowiednie opcje odczytać w taki sposób:
public class EmailService
{
EmailOptions serviceMailOptions;
EmailOptions newsletterMailOptions;
public EmailService(IOptionsSnapshot<EmailOptions> options)
{
serviceMailOptions = options.Get("ServiceMailing");
newsletterMailOptions = options.Get("NewsletterMailing");
}
}
Odłóż wczytywanie opcji na później
Odraczanie czytania opcji może być przydatne dla twórców bibliotek. Więc jeśli tego nie robisz, możesz śmiało opuścić ten akapit. Jeśli Cię to interesuje, to rozwiń go:
Kliknij tu, żeby rozwinąć ten akapit
Przedstawię trochę bezsensowny przykład, ale dzięki temu załapiesz jak wczytywać konfigurację później.
Pomyśl sobie, że tworzysz jakąś bibliotekę do wysyłania maili. Użytkownik może ją skonfigurować jak w powyższych przykładach:
Użytkownik może podać oczywiście dowolne dane. Ale Ty chcesz w swojej bibliotece mieć pewność, że jeśli FromEmail zawiera słowo „admin”, to pole From będzie zawierało „Admin”. Czyli konfiguracja taka jak poniżej będzie niepoprawna:
Wtedy EmailService otrzyma niepoprawne ustawienia (właściwość From znów będzie zawierała „John Rambo”).
Post konfiguracja
.NET przeprowadza konfigurację w dwóch etapach. Możesz posłużyć się metodą services.Configure lub services.PostConfigure.
.NET najpierw zbuduje CAŁĄ konfigurację, która została zarejestrowana metodą Configure (skrótowo powiedzmy, że „zbuduje wszystkie wywołania Configure”). A w drugim kroku zbuduje CAŁĄ konfigurację zarejestrowaną metodą PostConfigure. I teraz jeśli zmienisz kod swojej biblioteki:
w taki sposób, że zamiast Configure użyjesz PostConfigure, to wszystko zadziała. EmailService otrzyma poprawne dane.
Pewnie zapytasz teraz – „No dobrze, a czy użytkownik nie może użyć PostConfigure i znowu nadpisać mi opcje?” – pewnie, że może i nadpisze. Tak jak mówiłem na początku – to niezbyt udany przykład, ale chyba załapałeś o co chodzi z odroczoną konfiguracją 🙂 Walidację opcji tak naprawdę powinno się robić inaczej…
Jeśli spotkałeś się z przykładem z życia, gdzie PostConfigure jest lepsze albo pełni ważną rolę – daj znać w komentarzu.
Dobre praktyki
Jest kilka dobrych praktyk, które powinieneś stosować przy opcjach i naprawdę warto je stosować. Zdecydowanie mogą ułatwić Ci życie.
Twórz różne środowiska
Przede wszystkim, twórz w swoim projekcie różne środowiska. Development i Production to obowiązkowe minimum. Po prostu upewnij się, że masz takie pliki:
appsettings.json – ustawienia dla wersji produkcyjnej
appsettings.Development.json – ustawienia dla wersji developerskiej.
Tych plików możesz tworzyć znacznie więcej, np:
appsettings.Staging.json – ustawienia dla wersji przedprodukcyjnej (ostateczne testy przed wydaniem)
appsettings.Testing.json – jakieś ustawienia np. dla testów integracyjnych
appsettings.Local.json – jakieś typowe ustawienia dla środowiska lokalnego – Twojego komputera, na którym piszesz kod.
Pamiętaj, że o środowisku świadczy zmienna środowiskowa ASPNETCORE_ENVIRONMENT. Ona musi przyjąć jedną z nazw Twoich środowisk (Development, Production, Staging…). Jeśli tej zmiennej nie ma w systemie – uznaje się, że jest to wersja produkcyjna.
Pamiętaj, że pliki appsettings*.json lądują w repozytorium kodu. Chyba, że zignorujesz je w swoim systemie kontroli wersji. Jeśli tworzysz plik appsettings.Local.json – powinieneś automatycznie wyrzucać go z kontroli wersji.
Do trzymania wrażliwych danych używaj pliku secrets.json lub (w przypadku produkcji) – Azure KeyVault – jak to zrobić opiszę w osobnym artykule (zapisz się na newsletter lub polub stronę na fejsie, żeby go nie przegapić :)).
Nie używaj stringów (jako identyfikatorów) bezpośrednio
To chyba dotyczy wszystkiego – nie tylko opcji. Posługuj się w tym celu stałymi lub operatorem nameof. Np. zamiast wklepywać:
services.Configure<EmailOptions>(Configuration.GetSection("EmailSettings")); //nazwa sekcji na sztywno
wykorzystaj stałe:
public class EmailOptions
{
public const string EmailOptionsSectionName = "EmailSettings";
public string SmtpAddress { get; set; }
public string From { get; set; }
public string FromEmail { get; set; }
}
//
services.Configure<EmailOptions>(Configuration.GetSection(EmailOptions.EmailOptionsSectionName));
Sprawdzaj poprawność swoich opcji
Swoje opcje możesz walidować przez DataAnnotation (standard) lub FluentValidation (osobna biblioteka) i faktycznie powinieneś to robić, jeśli opcje mają jakieś ograniczenia lub z jakiegoś powodu mogą być niepoprawne.
To tyle, jeśli chodzi o zarządzanie opcjami w .NET. Jak pisałem wyżej – są jeszcze dwa aspekty, które na pewno będę chciał poruszyć w osobnych artykułach – walidajca opcji i odczytywanie opcji z Azure KeyVault. Być może napiszę też artykuł o tworzeniu własnego ConfigurationProvidera.
Jeśli znalazłeś w artykule jakiś błąd lub czegoś nie rozumiesz, koniecznie daj znać w komentarzu 🙂
Z tego tekstu dowiesz się czym jest middleware pipeline w .NET, jak go konfigurować i jak nim zarządzać. Większość blogów jakie widziałem, traktowały ten temat po macoszemu, ja postaram się go opisać dogłębnie. W końcu middleware pipeline to serce internetowych aplikacji w .NET.
Co to jest
Spójrzmy najpierw na middleware. Co to? To nic innego jak metoda (Action<HttpContext>), która w jakiś sposób przetwarza żądanie HTTP. Może je odczytywać, może zapisać coś w odpowiedzi na to żądanie, a także w jakiś sposób na nie zareagować. Więc – middleware to jest metoda, która przyjmuje w parametrze HttpContext (i dodatkowo kolejny middleware). Profesjonalnie nazywa się „oprogramowaniem pośredniczącym”, ale my będziemy mówić „komponent”. Bo w gruncie rzeczy tym właśnie jest.
To teraz czym jest pipeline? Po polsku nazywa się to „potokiem”… No i cześć… Można powiedzieć, że to taki „rurociąg” przez który przechodzi żądanie HTTP, a w rurociągu żyją sobie komponenty middleware.
Innymi słowy można powiedzieć, że to coś w rodzaju taśmy produkcyjnej.
Middleware pipeline jako taśma produkcyjna
Wyobraź sobie fabrykę, która produkuje różne surówki. W pewnym momencie dostaje żądanie wyprodukowania surówki z buraków.
Pierwsza osoba, która stoi przy taśmie produkcyjnej (komponent) przygotowuje buraki na podstawie tego żądania – obiera je i myje. Gdy wykona swoją robotę, przekazuje żądanie dalej – do kolejnej osoby.
Kolejna osoba ściera wcześniej przygotowane buraki na tarce. I żądanie przekazuje dalej. Kolejna osoba do tego wszystkiego dodaje przyprawy. Na koniec w odpowiedzi otrzymujemy smaczną surówkę z buraków.
Każda z tych osób (komponentów) przetworzyła na swój sposób żądanie i na koniec można było zwrócić odpowiedź (gotową surówkę, czy też stronę www – bez różnicy 🙂 ).
Zwróć uwagę na to, że każda z tych osób musi zadziałać w odpowiedniej kolejności. Gdybyśmy na początku postawili typa od tarcia buraków – co miałby zetrzeć, skoro jeszcze nie ma buraków? Albo gościa od przypraw przed starciem tych warzyw. Wynik byłby dziwny.
To teraz pogadajmy bardziej technicznie.
Jak działa pipeline w .NET
Komponenty w pipeline działają w określonej kolejności. W .NetCore pipeline był definiowany w metodzie Configure. Natomiast w .NET6 jest to analogicznie – po zarejestrowaniu serwisów. Zwyczajowo komponenty „wkłada się” do pipeline’a za pomocą metod Use, Map, czy Run:
Każdy z takich komponentów może zrobić coś z żądaniem i przekazać je dalej, ale wcale nie musi. Żądanie może być zatrzymane w każdym komponencie pipeline’a. Taki komponent, który nie przekazuje żądania dalej jest nazywany „końcowym” (terminal middleware) i powinien zwrócić odpowiedź.
Spójrz teraz na ten diagram ze strony Microsoftu:
Ten schemat przedstawia sposób działania Middleware Pipeline. Na początku przychodzi żądanie, które przechodzi przez różne middleware’y w odpowiedniej kolejności. Każdy z nich może wykonać jakąś pracę. Na koniec generowana jest odpowiedź.
Kolejność komponentów
Już kilka razy mówiłem o tym, że komponenty muszą występować w odpowiedniej kolejności. Na szczęście z domyślnymi nie musisz się… domyślać. Kolejność jest ustalona przez Microsoft w oficjalnej dokumentacji:
obsługa wyjątków – powinna być jak najwcześniej w potoku, żeby móc obsłużyć jak największą ilość błędów (również tych, które mogą wystąpić w innych middleware’ach)
HSTS
HttpsRedirection – analogicznie do HSTS – przekierowanie na HTTPS powinno odbyć się jak najszybciej
StaticFiles – obsługa statycznych plików takich jak html, js, css (domyślnie wszystko z katalogu wwwroot) – umożliwia wczytanie tych plików
Routing – dzięki temu .NetCore wie na rzecz jakiego kontrolera/strony wywołać żądanie
CORS
Authentication
Authorization – uwierzytelnianie i autoryzacja muszą występować właśnie w takiej kolejności. Żeby użytkownik mógł zostać autoryzowany (czy ma konkretne uprawnienia np. do wyświetlenia danej strony) musi zostać najpierw uwierzytelniony (utworzenie obiektu ClaimsPrincipal)
Twoje własne komponenty middleware
Endpoint
Trzymaj się tej kolejności, a wszystko będzie dobrze. Rzecz jasna może zdarzyć się taka sytuacja, że Twój własny komponent będzie musiał wystąpić w innym miejscu, np. przed routingiem. Nikt Ci nie zabroni go tam umieścić.
Niemniej jednak weź pod uwagę, że ta kolejność ma kluczowe znaczenie jeśli chodzi o bezpieczeństwo, wydajność i funkcjonalność. Więc komponenty musisz dodawać świadomie.
Kolejność standardowych komponentów
Spójrz teraz na fragment kodu Microsoftu, który prezentuje typową kolejność standardowych komponentów. Możesz sobie wydrukować ten fragment i używać jako ściągi:
if (app.Environment.IsDevelopment())
{
app.UseDeveloperExceptionPage(); //obsługa wyjątków w środowisku developerskim
app.UseDatabaseErrorPage();
}
else
{
app.UseExceptionHandler("/Error"); //obsługa wyjątków w środowisku produkcyjnym
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseCookiePolicy();
app.UseRouting();
app.UseRequestLocalization();
app.UseCors();
app.UseAuthentication();
app.UseAuthorization();
app.UseSession();
app.UseResponseCompression();
app.UseResponseCaching();
app.MapRazorPages();
Dla niektórych scenariuszy, możliwa jest zmiana pewnych kolejności. Np. Caching może być przed Compression. Ale UseCors, UseAuthentication i UseAuthorization muszą być dokładnie w takiej kolejności. Co więcej, UseCors (jeśli używane) musi być przed UseResponseCaching.
Forwarded headers
Jeśli używasz middleware’u do forwardowania nagłówków, koniecznie umieść go na pierwszym miejscu – możesz nawet przed obsługą wyjątków:
app.UseForwardedHeaders();
//app.UseCertificateForwarding();
if (app.Environment.IsDevelopment())
{
app.UseDeveloperExceptionPage(); //obsługa wyjątków w środowisku developerskim
app.UseDatabaseErrorPage();
}
//i tak dalej
Rozgałęzianie pipeline
Jeśli chcesz, możesz na podstawie warunków rozgałęzić pipeline, dzięki czemu dla pewnych warunków zostanie wykonana inna ścieżka. Można to zrobić na kilka sposobów:
Mapowanie ścieżki
Używając metody Map, możesz rozgałęzić swój pipeline na podstawie ścieżki, która się wykonuje.
Spójrz na ten kod:
var app = builder.Build();
//konfiguracja standardowego pipeline, a potem
app.Map("/daj-mi-google", GetGoogle);
app.MapControllerRoute(
name: "default",
pattern: "{controller=Home}/{action=Index}/{id?}");
app.Run();
static void GetGoogle(IApplicationBuilder app)
{
app.Run(async (context) =>
{
await Task.Run(() => context.Response.Redirect("https://www.google.pl")); //to jest końcowy middleware
});
}
MapControllerRoute mapuje standardowe ścieżki dla kontrolerów (MVC). Przed nim rozgałęziłem ścieżkę. Teraz, jeśli wywołasz adres: https://localhost/daj-mi-google, to właśnie ta alternatywna ścieżka zostanie uruchomiona. I w efekcie zostaniesz przekierowany na stronę Google. Standardowa ścieżka zostanie pominięta:
Przykład mapowania – pominięcie standardowej ścieżki
Przykład mapowania – standardowa ścieżka
Takich map możesz zrobić ile tylko chcesz. Możesz tworzyć też dłuższe ścieżki, np:
Używając metody MapWhen, możesz rozgałęzić ścieżkę na podstawie HttpContext. Załóżmy, że chcesz mieć inny pipeline dla przeglądarki Internet Explorer. Gdzie masz informacje o przeglądarce? W nagłówkach żądania:
Metoda MapWhen przyjmuje w parametrze obiekt Func<HttpContext, bool>. Jeśli taki delegat zwróci true, wtedy ruszy akcja z drugiego parametru. W tym przypadku po prostu sprawdzamy nazwę przeglądarki z nagłówka żądania. Ale to może być jakikolwiek warunek. Może to być sprawdzenie daty (np. gdy dzisiaj jest luty, to przekieruj na stronę z promocją -> albo dodaj middleware, który zarządza promocją)
Umożliwia Ci to również warunkowanie na podstawie query stringa (zapytań w adresie, np: https://localhost?akcja=logowanie). Generalnie wszystkiego, co możesz wyciągnąć z HttpContext.
Odpowiedź na żądanie
Wszystkie rozgałęzienia używające Map, kierują na końcowy middleware. Tak, to co zrobiliśmy wyżej, to pewna forma własnego middleware’u. O tym będzie więcej w innym artykule. Na razie wiedz, że w taki prosty sposób można napisać bardzo prosty middleware.
Nasze końcowe middlewar’y zawsze zwracały jakąś odpowiedź – albo przekierowanie, albo tekst. I nie wywoływały kolejnych. To znaczy, że rozgałęzienie używające Map lub MapWhen, rozgałęzia Middleware na dobre:
Map tworzy po prostu zupełnie oddzielną drogę. Każda z nich na końcu musi zwrócić jakąś odpowiedź. Każda z nich jest niezależna.
OK, a co jeśli chcielibyśmy tylko na chwilę rozdzielić ścieżkę? Do tego służy UseWhen.
Użyj i wróć, czyli UseWhen
UseWhen działa podobnie do MapWhen, z tą różnicą, że wraca do głównego pipeline:
UseWhen sprawdza warunek. Jeśli warunek się nie zgadza, idzie standardową drogą – pipeline 1. Jeśli jednak warunek jest prawdziwy, idzie alternatywną drogą – pipeline 2, następnie wraca do pipeline 1 (chyba że w pipeline 2 znajdzie się middleware końcowy).
Przykład – rabat na luty
Spróbuj zrobić teraz taki przykład za pomocą UseWhen i MapWhen. MapWhen zakończy się wyjątkiem.
Scenariusz jest taki – w lutym sklep ma super promocję. I w lutym wszystkie ceny są podmieniane. Na początek stwórzmy sobie prostą klasę przechowującą ceny:
public class PriceProvider
{
public bool IsPromoMode { get; set; } = false;
public decimal CurrentPrice { get { return IsPromoMode ? promoPrice : normalPrice; } }
decimal promoPrice;
decimal normalPrice;
public PriceProvider()
{
promoPrice = 10.0m;
normalPrice = 15.0m;
}
}
Mamy tutaj cenę promocyjną, normalną i aktualną. Mamy również jakąś flagę, która określa, czy jest promocja.
Teraz zarejestrujmy tę klasę w dependency injection (jeśli nie wiesz co to, koniecznie przeczytaj ten artykuł) jako scoped:
builder.Services.AddScoped<PriceProvider>();
A teraz napiszmy prosty middleware do promocji. UWAGA! Poniżej pokazuję „przypadkiem” jak tworzyć własny middleware, ale o tym będzie osobny artykuł:
public class PromoMiddleware
{
private readonly RequestDelegate next;
public PromoMiddleware(RequestDelegate next)
{
this.next = next;
}
public async Task Invoke(HttpContext ctx, PriceProvider prov)
{
prov.IsPromoMode = true;
await next(ctx);
}
}
Tutaj w metodzie Invoke wstrzykiwany jest serwis PriceProvider, flaga IsPromoMode jest ustawiana na true, a na koniec jest wywoływany kolejny middleware z pipeline (next).
Rozgałęzienie następuje na podstawie aktualnego miesiąca. Jeśli jest luty, to wtedy tworzymy rozgałęzienie (dodajemy do pipeline PromoMiddleware) i wracamy do głównego pipeline’a. Dzięki temu nie mamy dwóch całkowicie niezależnych ścieżek, ale warunkowo możemy zarejestrować middleware gdzieś w środku.
Teraz tylko wstrzyknij do swojej strony/widoku Index.cshtml PriceProvider:
Jeśli teraz uruchomisz tę aplikację i jest luty, zobaczysz:
A teraz zmień warunek w UseWhen tak, żeby zwrócił false. Zobaczysz normalną stronę bez promocji:
W ramach ćwiczeń zrób to samo, używając MapWhen. Zobaczysz wywałkę przy warunku z dostępną promocją, ponieważ w swoim rozgałęzieniu nie masz kończącego middleware, który zwraca odpowiedź.
Podsumowanie
To w zasadzie tyle jeśli chodzi o konfigurację middleware pipeline. Możesz mieć tylko jeden pipeline, ale możesz też go rozgałęzić za pomocą Map/MapWhen – tworząc dwie niezależne ścieżki. A możesz też go rozgałęzić za pomocą UseWhen – dodając warunkowo middlewary w środek pipeline lub wykonując jakąś inną pracę.
W tym artykule opiszę kilka bardziej zaawansowanych metod, które stosuje się właściwie na co dzień. Jednak nie bój się. Słowo „zaawansowane” w tym kontekście nie oznacza niczego trudnego…
Kod testowalny vs nietestowalny
Każdy system można napisać w taki sposób, że nie da się do niego zrobić testów lub zrobienie ich będzie zupełnie nieopłacalne. Taki projekt nazywamy nietestowalnym. Można system projektować też tak, żeby testy były całkowicie normalnym zjawiskiem. I do tego dążymy.
Jak zwykle kod powie więcej niż 1000 słów…
class UserData
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
class UserDataProvider
{
public UserData ReadData(int userId)
{
string fileName = $@"C:\dane\{userId}.txt";
if (!File.Exists(fileName))
return null;
UserData userData = new UserData();
userData.FirstName = data[0];
userData.LastName = data[1];
return userData;
}
}
Metoda ReadData sprawdza, czy plik o konkretnej nazwie istnieje (1), jeśli tak odczytuje go z dysku (2) i tworzy obiekt klasy UserData (3; metoda ma aż 3 odpowiedzialności)
Jak teraz przetestujesz jednostkowo metodę ReadData? Nie da się, bo jest silnie związana z klasą File, a problem klasy File polega na tym, że odnosi się do konkretnych zasobów, których po prostu podczas jednostkowego testowania nie będzie. Co więcej, jeśli chciałbyś zapisać dane użytkownika, klasa File zapisze plik na dysku – to jest tzw. „efekt uboczny”. Testy jednostkowe nie mogą mieć żadnych efektów ubocznych. Jest to bardzo niepożądane.
Dlatego też, żeby uczynić klasę UserDataProvider testowalną, musimy zaprojektować jakąś abstrakcję – zastosować DependencyInjection. Jeśli nie wiesz co to, przeczytaj artykuł, w który opisuję ten mechanizm.
Stosuj abstrakcje
Zamiast posługiwać się bezpośrednio klasą File, utworzymy interfejs, który zostanie wstrzyknięty do UserDataProvider. Jeśli nie rozumiesz pojęcia wstrzyknięcie, koniecznie przeczytaj ten artykuł.
Mając taką abstrakcję, możemy już zmienić klasę UserDataProvider i uczynić ją testowalną:
class UserDataProvider
{
IDataRepository repo;
public UserDataProvider(IDataRepository repo)
{
this.repo = repo;
}
public UserData ReadData(int userId)
{
string[] data = repo.GetData(userId);
UserData userData = new UserData();
userData.FirstName = data[0];
userData.LastName = data[1];
return userData;
}
}
Zobacz, co się przy okazji stało. Metoda ReadData robi już tylko jedną rzecz, a nie kilka jak to było na początku.
Ale jak teraz testować tę klasę? Musimy stworzyć JAKIŚ obiekt implementujący interfejs IDataRepository…
Co to jest Fake Object?
Fake Object to nic innego jak obiekt oszukany. Ma się zachować dokładnie tak, jak tego chcemy w danej sytuacji. Napiszmy więc sobie taki FakeObject, który implementuje IDataRepository:
class FakeRepository : IDataRepository
{
public string[] DataToReturn { get; set; } = null;
public string[] GetData(int id)
{
return DataToReturn;
}
}
Po prostu metoda GetData zwróci takie dane, jakie przekażemy wcześniej do właściwości DataToReturn. Teraz przyszedł czas na napisanie pierwszego testu z Fake’iem. Przygotuj zatem nowy projekt testowy (jeśli nie wiesz jak, to przeczytaj artykuł o podstawach testów jednostkowych).
Testy z użyciem Fake
Ja w swoim przykładzie będę stosował bibliotekę nUnit.
Tak jak mówiłem, testujemy klasę UserDataProvider i metodę ReadData. Przypomnę kod:
class UserDataProvider
{
IDataRepository repo;
public UserDataProvider(IDataRepository repo)
{
this.repo = repo;
}
public UserData ReadData(int userId)
{
string[] data = repo.GetData(userId);
UserData userData = new UserData();
userData.FirstName = data[0];
userData.LastName = data[1];
return userData;
}
}
Jakie chcemy przetestować przypadki?
nie ma użytkownika o takim id
odczytane dane są niepoprawne
odczytane dane są prawidłowe
Test – brak użytkownika
Napiszmy więc pierwszy test:
[Test]
public void ReadData_NoSuchUser_ReturnsNull()
{
FakeRepository repo = new FakeRepository();
repo.DataToReturn = null;
UserDataProvider udp = new UserDataProvider(repo);
UserData result = null;
Assert.DoesNotThrow(() => result = udp.ReadData(0));
Assert.IsNull(result);
}
Najpierw został utworzony obiekt fake’owy. Chcemy, żeby zwracał null – zakładamy, że tak będzie, gdy użytkownika nie będzie w systemie.
Następnie utworzyliśmy prawdziwy obiekt – UserDataProvider, korzystający z oszukanego FakeRepository.
I sprawdzamy, czy metoda się nie wywala (nie chcemy tego) i czy nie zwróciła żadnego użytkownika.
Po uruchomieniu testu okazuje się, że aplikacja się wykrzacza – jest rzucony wyjątek NullReferenceException. No oczywiście, że tak bo okazuje się, że w metodzie ReadData nigdzie nie sprawdzamy, co zostało zwrócone z repozytorium. Poprawmy to:
public class UserDataProvider
{
IDataRepository repo;
public UserDataProvider(IDataRepository repo)
{
this.repo = repo;
}
public UserData ReadData(int userId)
{
string[] data = repo.GetData(userId);
if(data == null)
return null;
UserData userData = new UserData();
userData.FirstName = data[0];
userData.LastName = data[1];
return userData;
}
}
Super, teraz działa. Sprawdźmy zatem drugi przypadek.
Test – poprawne dane
[Test]
public void ReadData_UserExists_ReturnsUser()
{
FakeRepository repo = new FakeRepository();
repo.DataToReturn = new string[]
{
"Adam",
"Jachocki"
};
UserDataProvider udp = new UserDataProvider(repo);
UserData user = null;
Assert.DoesNotThrow(() => user = udp.ReadData(0));
Assert.IsNotNull(user);
Assert.AreEqual("Adam", user.FirstName);
Assert.AreEqual("Jachocki", user.LastName);
}
Najpierw skonfigurowaliśmy obiekt fake’owy tak, żeby zwrócił tablicę z dwoma elementami – dokładnie w takiej formie dostaniemy dane z pliku tekstowego.
Na koniec sprawdziliśmy kilka rzeczy:
czy program się nie wysypał
czy user jest prawidłowym obiektem
czy user posiada odpowiednie wartości
Tym razem test zadziałał. No to został ostatni przypadek…
Test – nieprawidłowe dane
[Test]
public void ReadData_InvalidData_ThrowsException()
{
FakeRepository repo = new FakeRepository();
repo.DataToReturn = new string[]
{
"Adam",
};
UserDataProvider udp = new UserDataProvider(repo);
UserData user = null;
Assert.Throws<InvalidDataException>(() => user = udp.ReadData(0));
}
Przede wszystkim chcemy, żeby program się wygrzmocił, jeśli dane będą w niepoprawnym formacie (np. repo zwróci tablicę jednoelementową zamiast dwuelementową). To zdecydowanie jest sytuacja wyjątkowa, w której zastosowanie wyjątków ma jak najbardziej sens. Program ma się wywalić, więc nie stosujemy już innych sprawdzeń.
Po uruchomieniu tego testu dostajemy brzydki błąd na twarz z komunikatem:
Expected: <System.IO.InvalidDataException>
But was: <System.IndexOutOfRangeException
Oznacza to, że owszem został rzucony wyjątek, ale IndexOutOfRangeException zamiast tego, który chcemy – InvalidDataException. No racja. Jeśli spojrzysz na klasę UserDataProvider, zobaczysz że nigdzie nie rzucamy takiego wyjątku. Natomiast IndexOutOfRange jest rzucany przez system, ponieważ odwołujemy się do nieistniejącego elementu w tablicy. Naprawmy to:
public UserData ReadData(int userId)
{
string[] data = repo.GetData(userId);
if (data == null)
return null;
if (data.Length < 2)
throw new InvalidDataException("Dane w niepoprawnym formacie!");
UserData userData = new UserData();
userData.FirstName = data[0];
userData.LastName = data[1];
return userData;
}
Testy poszły, ale ja teraz mam duże zastrzeżenia do tego kodu. Metoda ReadData nie dość, że tworzy użytkownika, to jeszcze sprawdza poprawność danych. Czyli znów ma dwie odpowiedzialności. Powinniśmy teraz trochę ten kod wyczyścić i walidację danych zrobić w osobnej metodzie:
Trochę czyszczenia
public UserData ReadData(int userId)
{
string[] data = repo.GetData(userId);
if (!ValidateData(data))
return null;
UserData userData = new UserData();
userData.FirstName = data[0];
userData.LastName = data[1];
return userData;
}
bool ValidateData(string[] data)
{
if (data == null)
return false;
if(data.Length < 2)
throw new InvalidDataException("Dane w niepoprawnym formacie!");
return true;
}
Kod stał się bardziej czytelny i nadal działa. SUPER! Zwróć uwagę na dwie rzeczy:
to co właśnie zrobiliśmy (czyszczenie kodu, rozdzielanie go) nazywa się refactoring. Podczas refactoringu czasami dochodzi do błędów. Gdyby nie testy jednostkowe, moglibyśmy ich nie wychwycić, a przynajmniej nie tak szybko. Jest taka zasada, która mówi – nie refaktoruj kodu, do którego nie masz testów.
podczas poprawiania kodu może okazać się, że musisz pewne rzeczy przemyśleć lub przeprojektować
Wiesz już czym jest Fake Object i jak go używać w testach. Ale jest jeszcze jedno… Fajne…
Czym jest Mock?
Mock to imitacja (dosłowne tłumaczenie) jakiegoś obiektu. To jest alternatywa dla FakeObject. W niektórych językach programowania może być trudne lub niemożliwe stworzenie mocka. Na szczęście my jesteśmy w świecie .NET, gdzie z odpowiednią biblioteką jest to oczywiste i proste jak beknięcie po piwie.
Różnica między Mock a Fake
Główną różnicą jest to, że jeśli tworzysz FakeObject, musisz zaimplementować wszystkie metody z interfejsu. Gdy tworzysz Mock – implementujesz tylko to co chcesz i tak jak chcesz. I to ad hoc!
Jednak Mock nie jest złotym środkiem. Czasami lepiej się sprawdzi Mock, a w niektórych przypadkach lepiej będzie napisać FakeObject.
Teraz się pobawimy. Zmieńmy testy w taki sposób, żeby nie używać Fake, tylko Mock (będziemy „mokować”). Najpierw pierwszy przypadek:
[Test]
public void ReadData_NoSuchUser_ReturnsNull()
{
var mockRepository = new Mock<IDataRepository>();
mockRepository.Setup(m => m.GetData(It.IsAny<int>())).Returns<string[]>(null);
UserDataProvider udp = new UserDataProvider(mockRepository.Object);
UserData result = null;
Assert.DoesNotThrow(() => result = udp.ReadData(0));
Assert.IsNull(result);
}
Co tu się stało?
Utworzyliśmy obiekt Mock, mówiąc mu jaki interfejs ma imitować
Za pomocą metody Setup możemy skonfigurować Mocka w taki sposób, żeby powiedzieć mu:
jakie argumenty przyjmuje metoda (może to być konkretny argument albo tak jak tutaj – jakikolwiek int: It.IsAny<int>()
jaką wartość ma zwracać metoda – w związku z tym, że zwracamy null, musimy podać typ zwracanej wartości
W jednym Setupie konfigurujemy jedną metodę. Nic nie stoi na przeszkodzie, żeby skonfigurować ich więcej.
Nie pisząc żadnej nowej klasy otrzymaliśmy coś, co potrafi imitować działanie obiektu.
Klasa Mock ma właściwość Object, która jest żądanego typu (w naszym przypadku IDataRepository), dlatego też to tę właściwość wstrzykujemy do konstruktora.
A jaki jest kod? Nie ma to znaczenia. To jest zwykła imitacja – najbardziej Cię interesuje, co metoda zwraca (czasami, jaki argument przyjmuje). Co więcej, możesz skonfigurować tak, żeby mock zwracał różne wartości dla różnych parametrów, np:
W ramach ćwiczeń zachęcam Cię do przerobienia pozostałych testów z Fake’ów na Mocki.
Dokumentacja
Trochę mnie korci, żeby napisać coś więcej o bibliotece Moq, ale to nie jest o tym artykuł. Jeśli będzie jakaś prośba, na pewno to zrobię. Póki co odsyłam do:
Biblioteka Moq potrafi zrobić właściwie chyba wszystko, co sobie wymyślisz. Dlatego polecam poczytać o niej i potestować.
To właściwie wszystko jeśli chodzi o testy jednostkowe. Jeśli czegoś nie rozumiesz, coś pominąłem lub znalazłeś błąd, podziel się w komentarzu. Jeśli uważasz artykuł za przydatny, podziel się nim z innymi 🙂
Ten artykuł opisuje czym jest dependency injection. A także jak z tego korzystać w .NET i po co. Jeśli wiesz, znasz, stosujesz, to raczej niczego nowego się tutaj nie dowiesz 🙂 On jest kierowany głównie do młodych programistów lub programistów nie znających tych mechanizmów.
O co chodzi we wstrzykiwaniu zależności?
Przede wszystkim musimy zdefiniować sobie zależność. O zależności mówimy wtedy, kiedy jedna klasa zależy od drugiej. Weźmy sobie przykładową klasę Writer, która umie wypisywać komunikaty i klasę Worker, która wykonuje jakąś operację i posługuje się klasą Writer.
class Writer
{
public void Write(string message)
{
Console.WriteLine(message);
}
}
class Worker
{
Writer writer = new Writer();
public void Foo()
{
writer.Write("Rozpoczynam pracę...");
}
}
Jak widzisz, klasa Worker zależy od klasy Writer.
Co więcej, klasa Worker samodzielnie tworzy i używa obiekt klasy Writer. Takie coś nazywamy silnym związaniem (tight coupling). I chociaż tight coupling to pojęcie szersze, to jednak dobrze jest prezentowany przez ten przykład. Dwie klasy są mocno ze sobą związane.
Takie zakodowane na sztywno zależności (silne związania) są złe dla aplikacji i powinieneś ich unikać. Dlaczego?
jeśli chciałbyś aby komunikaty były wpisywane do pliku, a nie na konsolę, musiałbyś zmienić klasę Writer lub utworzyć nową i zmienić klasę Worker (sprzeczność z zasadą OpenClose).
jeśli klasa Writer miałaby inne zależności, te zależności musiałby także zostać utworzone (lub w jakiś sposób przekazane) przez klasę Worker. Lub utworzone w klasie Writer, co jeszcze bardziej zacieśnia kod. Ponadto daje nam już zbyt dużo odpowiedzialności (możliwa sprzeczność z zasadą Single Responsibility) i zdecydowanie zaciemnia obraz.
Te wszystkie problemy można rozwiązać stosując wstrzykiwanie zależności…
Siostro! Zastrzyk!
OK, teraz wyobraźmy sobie jak lepiej mogłaby wyglądać klasa Worker:
class Worker
{
Writer writer;
public Worker(Writer writer)
{
this.writer = writer;
}
public void Foo()
{
writer.Write("Rozpoczynam pracę...");
}
}
Spójrz, co się stało. Wstrzyknęliśmy obiekt klasy Writer do Worker za pomocą konstruktora. Obiekt Writer w tym momencie jest już poprawnie stworzony (ma utworzone swoje wszystkie zależności) i można go używać. Klasa Worker nie musi tworzyć już tego obiektu i nie daj Boże innych jego zależności.
Po prostu Worker używa Writer. A skąd go ma? To w zasadzie nie jest istotne. Czy Ciebie interesuje kto zrobił Ci przelew na konto? Czy ważne, że masz te pieniądze? 😉
Jednak cały czas nie rozwiązaliśmy jednego problemu. Silnego związania. Klasa Worker cały czas jest silnie związana z Writer. A gdyby tak posłużyć się interfejsem?
interface IWriter
{
void Write(string message);
}
class Writer: IWriter
{
public void Write(string message)
{
Console.WriteLine(message);
}
}
class Worker
{
IWriter writer;
public Worker(IWriter writer)
{
this.writer = writer;
}
public void Foo()
{
writer.Write("Rozpoczynam pracę...");
}
}
Na początku zdefiniowaliśmy sobie interfejs IWriter – z jedną metodą. Potem utworzyliśmy klasę Writer implementującą ten interfejs i na koniec do klasy Worker wstrzyknęliśmy interfejs.
W .NET można wstrzykiwać zależności przez konstruktor (najczęściej używane), właściwość (częściej używane w Blazor, gdzie to jest jedyna możliwość w komponencie będącym widokiem), a nawet przez parametr (stosowane raczej w kontrolerze webowej aplikacji)
To nam rozwiązuje ostatni problem. Dlaczego? Bo możemy sobie teraz rozszerzyć naszą aplikację, pisząc nieco inną implementację klasy Writer:
class FileWriter : IWriter
{
public void Write(string message)
{
File.AppendText(message);
}
}
Teraz klasa Worker może dostać obiekt Writer lub FileWriter. Nie ma już silnego związania z klasą Writer. Otrzymaliśmy luźne powiązanie (loose coupling). Daje to też możliwość napisania oszukanej klasy (Fake), którą można wykorzystać później w testach automatycznych:
class FakeWriter : IWriter
{
public void Write(string message)
{
//żadnego ciała albo Debug.WriteLine
}
}
Powyższy przykład pokazuje również wzorzec projektowy „Strategia”. Wzorzec ten jest poniekąd jednym z przykładów wstrzykiwania zależności.
Kontenery IoC
Zostaje jeszcze pytanie, jak tworzyć obiekty jak np. Writer? NAJPROSTSZYM przykładem Dependency Injection jest po prostu:
Worker worker = new Worker(new Writer());
To jest NAJPROSTSZY przykład, najbardziej banalny i całkowicie bezużyteczny w prawdziwym świecie (chociaż czasem nie da się inaczej). Co więcej, powoduje dużo problemów. Załóżmy, że masz taki kod rozsiany po całej aplikacji i nagle konstruktor klasy Writer potrzebuje jeszcze jednego obiektu… Musisz to zmieniać w wielu miejscach. Zupełna strata czasu.
Na szczęście powstało coś takiego jak kontenery DI.
Czym jest kontener DI
To specjalny kontener (pomyśl o tym jak o klasie Dictionary<Type, object> na mocnych sterydach), który konfigurujesz podczas inicjalizowania aplikacji. Np. w metodzie Main. Możesz spotkać się też z określeniem „kontener IoC” – IoC to „Inversion of Control” – wzorzec projektowy, którego jedną z implementacji jest wstrzykiwanie zależności.
Konfigurując taki kontener, rejestrujesz w nim klasy, interfejsy, długości życia, a także sposoby w jakie konkretne obiekty mają zostać tworzone. Kontenery dają też możliwość rejestrowania własnych metod do tworzenia obiektów. Na końcu to właśnie kontener tworzy dla Ciebie w pełni działający obiekt.
W C# mamy do dyspozycji różne kontenery IoC. Najbardziej znane to chyba Autofac i Microsoft.Extensions.DependencyInjection. Autofac był wcześniej, natomiast w .NetCore przyszły mechanizmy z Microsoftu. Jako, że Autofac jest dużo starszy, PRAWDOPODOBNIE ma więcej możliwości, ale Microsoftowy odpowiednik jest wystarczający. Moim zdaniem jest też prostszy w użyciu i dlatego to nim się zajmiemy.
Długość życia serwisu
W związku z tym, że mechanizm DI musi widzieć kiedy tworzyć i zwalniać obiekty, podczas konfiguracji podajemy długość życia. Czyli mówimy kontenerowi jak długo obiekt powinien żyć, czy też kiedy go tworzyć. To może wyglądać strasznie, ale w rzeczywistości jest bardzo proste.
Niezależnie od tego, czy używasz Autofaca, Microsoft Dependency Injection, czy jeszcze innego mechanizmu, długości życia będą analogiczne:
Transient
Obiekt zarejestrowany jako transient będzie tworzony za każdym razem, gdy będzie potrzebny. To znaczy, że każda klasa, do której wstrzykujesz obiekt transient, będzie miała własną niepowtarzalną instancję, np:
class Worker
{
IWriter writer;
public Worker(IWriter writer)
{
this.writer = writer;
}
}
class Manager
{
IWriter writer;
public Manager(IWriter writer)
{
this.writer = writer;
}
}
Jeśli klasa Writer zostanie zarejestrowana jako transient, to instancje Writera w Worker i Manager zawsze będą różne. Po prostu klasa Writer zostanie utworzona na nowo przy każdym takim wstrzyknięciu.
Można by to przyrównać do tego kodu:
Writer w1 = new Writer();
Worker worker = new Worker(w1);
Writer w2 = new Writer();
Manager manager = new Manager(w2);
Scoped
W przypadku aplikacji desktopowych i mobilnych nie różni się to od singleton niczym (chyba że sam tworzysz scope). W przypadku aplikacji webowych, powstanie tylko jedna instancja takiego obiektu na żądanie http. Tzn.:
class Worker
{
IWriter writer;
public Worker(IWriter writer)
{
this.writer = writer;
}
}
class Manager
{
IWriter writer;
public Manager(IWriter writer)
{
this.writer = writer;
}
}
Jeśli teraz Worker zostanie zarejestrowany jako scoped i jesteśmy w obrębie jednego żądania HTTP, wtedy w Worker i Manager będziemy mieli tę samą instancję klasy Writer. Po prostu obiekt Writer zostanie utworzony raz i wstrzyknięty do wszystkich innych obiektów w ramach jednego żądania. Obiekt umiera, gdy żądanie się kończy i nie jest już dłużej używany.
Można by to zademonstrować takim kodem:
Response ManageRequest()
{
Writer scopedWriter = new Writer();
Worker worker = new Worker(scopedWriter);
Manager manager = new Manager(scopedWriter);
//tutaj praca na żądaniu..., a na koniec
worker = null;
manager = null;
scopedWriter = null;
}
Singleton
Zostanie utworzona TYLKO JEDNA instancja takiej klasy w całej aplikacji. I ta jedna instancja będzie przekazywana innym obiektom przez cały okres działania aplikacji. Obiekt umiera wraz z aplikacją.
Można to porównać do takiego kodu:
if (mainWriter == null)
mainWriter = new Writer();
Worker worker = new Worker(mainWriter);
Manager manager = new Manager(mainWriter);
DI od Microsoftu
Jeśli tworzysz aplikację webową, to masz już to w standardzie. Natomiast aplikacja konsolowa, WPF, czy WinForms wymaga, żebyś zainstalował paczkę NuGet: Microsoft.Extensions.DependencyInjection
Następnie musisz dodać do usings:
using Microsoft.Extensions.DependencyInjection;
Kontenery
Zwróć teraz uwagę na dwie klasy: ServiceCollection i ServiceProvider. W klasie ServiceCollection dodajemy wszystkie nasze serwisy – konfigurujemy kontener DI. Klasa ServiceProvider tworzy i zwraca nam konkretny obiekt, który potrzebujemy w danej chwili.
Weźmy teraz prostą aplikację konsolową:
class MainClass
{
static void Main()
{
Console.Write("Podaj imię: ");
string name = Console.ReadLine();
Console.WriteLine($"Cześć {name}!");
Console.ReadKey();
}
}
Spróbujmy ją przerobić tak, żeby używała Dependency Injection. Standardowe podejście jest takie:
w metodzie main konfigurujemy dependency injection
pobieramy obiekt jakiejś głównej klasy (np. w WPF/WinForms byłoby to najpewniej MainForm, czy też MainWindow)
wywołujemy metodę z tej klasy
Ponieważ pracujemy na konsoli, musimy stworzyć główną klasę aplikacji. Klasa Main w tym wypadku służy tylko do konfiguracji:
class App
{
public void Run()
{
}
}
W metodzie Main utworzymy instancję klasy App, następnie wywołamy metodę Run, która zrobi dokładnie to samo, co Main po staremu. Moglibyśmy tutaj użyć klasy Console, ale żeby pobawić się dependency injection, zrobimy to inaczej.
Używaj abstrakcji
Zamiast posługiwać się bezpośrednio klasą Console, utworzymy interfejs i zaimplementujemy go:
interface IUserInteraction
{
void Print(string message);
string Read();
}
class ConsoleInteraction : IUserInteraction
{
public void Print(string message)
{
Console.Write(message);
}
public string Read()
{
return Console.ReadLine();
}
}
Konfiguracja
Teraz w metodzie Main skonfigurujemy nasze DI. Aby to zrobić, najpierw trzeba utworzyć obiekt klasy ServiceCollection (pamiętaj, że w aplikacjach webowych masz już to dostępne):
class MainClass
{
static void Main()
{
var serviceCollection = new ServiceCollection();
serviceCollection.AddTransient<IUserInteraction, ConsoleInteraction>();
serviceCollection.AddSingleton<App>();
using(var serviceProvider = serviceCollection.BuildServiceProvider())
{
var app = serviceProvider.GetService<App>();
app.Run();
}
}
}
W linijce 5 tworzymy ServiceCollection, a następnie rejestrujemy dwa serwisy:
ConsoleInteraction jako interfejs IUserInteraction – pamiętaj, że w Microsoft DI najpierw podajesz interfejs, a później klasę, która ten interfejs implementuje (jeśli zrobisz na odwrót, aplikacja się nie skompiluje). Teraz mechanizm DI wszędzie tam, gdzie zobaczy interfejs IUserInteraction, utworzy obiekt klasy ConsoleInteraction.
Klasę App jako singleton. Jak widzisz – nie jest wymagany interfejs żeby zarejestrować klasę. W przypadku klasy App interfejs nie ma większego sensu, bo to główna klasa aplikacji. Ale często interfejs ma sens (głównie tam, gdzie jest zależnością dla innej klasy), więc pamiętaj o tym.
Jeśli nie wiesz czym jest singleton to po prostu obiekt który jest utworzony raz w całej aplikacji i żyje przez cały cykl jej życia. Możesz się też spotkać z określeniem, że singleton jest antywzorcem, ale tu chodzi o inną sytuację – ręczne klasyczne tworzenie singletona. W naszym przypadku rejestrujemy klasę jako singleton w kontenerze DI i wszystko jest w porządku.
Teraz tak. Dlaczego klasę ConsoleInteraction zarejestrowaliśmy jako transient? W przypadku tej aplikacji nie ma to żadnego znaczenia, bo i tak użyjemy jej tylko w jednym miejscu. Chciałem po prostu pokazać, że tak to się robi. Zazwyczaj klasy logujące będziesz rejestrował jako singletony.
A dlaczego klasa App jest jako singleton? No przypomnij sobie czym jest singleton – jedna instancja klasy, która żyje przez cały czas życia aplikacji. Czyli idealny zakres dla klasy, która reprezentuje całą aplikację.
Pobieranie serwisów
W linijce 9 tworzymy ServiceProvider ze skonfigurowanego ServiceCollection. Od tego momentu ServiceProvider będzie dostarczał nam obiekty, których potrzebujemy. Nie można już niczego zmienić w service collection (oczywiście nikt Ci nie broni, żeby mieć kilka ServiceCollection i Providerów, ale jakoś nie widzę w tym sensu).
Na końcu używamy ServiceProvider, żeby otrzymać obiekt klasy App. Dosłownie –
– Ej Ty! ServiceProvider, dej mnie no w pełni działający obiekt klasy App!
To może nie jest niczym wyglądającym super. Po prostu nie musiałeś tworzyć obiektu przez new, tylko za pomocą ServiceProvidera. Ale pamiętasz IUserInteraction? Teraz dodajmy go do klasy App:
class App
{
readonly IUserInteraction ui;
public App(IUserInteraction ui)
{
this.ui = ui;
}
public void Run()
{
ui.Print("Podaj imię: ");
string name = ui.Read();
ui.Print($"Cześć {name}!");
Console.ReadKey();
}
}
W metodzie Main – już nic więcej nie musisz robić. Otrzymasz znowu w pełni działający obiekt klasy App! Klasa implementująca IUserInteraction zostanie automagicznie utworzona i wstrzyknięta do App.
ServiceProvider i zwalnianie zasobów
Pewnie chodzi Ci po głowie pytanie – co z klasami IDisposable? I czy są one zwalniane?
Zasadniczo tak. Spójrz, jak został utworzony ServiceProvider:
using (var serviceProvider = serviceCollection.BuildServiceProvider())
{
var app = serviceProvider.GetRequiredService<App>();
app.Run();
}
Teraz wszystkie obiekty zostaną zwolnione po zwolnieniu ServiceProvidera. Natomiast ServiceProvider może też utworzyć tzw. zakres:
using (var serviceProvider = serviceCollection.BuildServiceProvider())
{
using (var scope = serviceProvider.CreateScope())
{
var app = scope.ServiceProvider.GetRequiredService<App>();
app.Run();
}
}
W aplikacji możemy mieć wiele takich zakresów. Np. w aplikacji webowej taki zakres jest tworzony na całe żądanie HTTP. Obiekty zarejestrowanie jako scope i transient zostaną usunięcie po wyjściu z takiego zakresu, chyba że są zależnościami dla innych obiektów. Jeśli implementują interfejs IDisposable lub IAsyncDisposable, odpowiednie metody Dispose też zostaną automatycznie wywołane. Singletony zostaną zwolnione po zakończeniu życia ServiceProvidera.
Ale uwaga! Jeśli zarejestrowałeś singleton, który jest zależny od innych klas i np. taką zależność zarejestrowałeś jako transient (lub scoped), to zwróć uwagę na to, że te zależności zostaną zwolnione dopiero po śmierci singletona. Przecież singleton na nich polega, dlatego też musi mieć dostęp do nich przez cały czas. W niektórych bibliotekach (np. boost::di dla C++) musisz rejestrować zależności dla singletona jako singleton. W .NET tak nie jest (przynajmniej nie w chwili pisania artykułu), ale miej świadomość długości życia.
Więcej na ten temat w kolejnym artykule, opisujących typowo Microsoft Dependency Injection
Skąd ten ServiceProvider jest taki mądry?
W baaaardzo dużym skrócie można by opisać jego działanie tak:
Jaki chcesz typ? App? OK, sprawdźmy go
Typ App ma konstruktor z parametrami. Jaki jest pierwszy parametr? IUserInteraction
OK, muszę stworzyć teraz obiekt IUserInteraction. Co go implementuje? Z konfiguracji wynika, że ConsoleInteraction.
Jaki konstruktor ma ConsoleInteraction? Domyślny. No to tworzymy ConsoleInteraction
Skoro mam utworzone ConsoleInteraction, mogę teraz utworzyć App
ServiceProvider przeleci przez wszystkie zależności (i zależności tych zależności) i utworzy je (jeśli musi) w odpowiedniej kolejności. Na koniec zwróci Ci w pełni działający obiekt, o który prosiłeś.
Możesz teraz uruchomić aplikację i zobaczyć jak działa. Przedebuguj ją sobie linijka po linijce i sprawdź kiedy wywołują się poszczególne konstruktory.
Wydajność aplikacji
Oczywiście taki mechanizm musi wpływać na wydajność aplikacji. Jednak w dzisiejszych czasach nie ma się tym co przejmować. Raczej nie powinno być to zauważalne. Używaj tego i będzie git 🙂 Pamiętaj, żeby nie optymalizować programu jeśli faktycznie nie musisz. Jeśli jest to problem, pomyśl czy klas, które są tworzone najdłużej nie zarejestrować jako singletony.
To na tyle, jeśli chodzi o wstrzykiwanie zależności. W innym artykule opiszę niedługo co jeszcze bardziej zaawansowanego można osiągnąć tym mechanizmem. Więc koniecznie zapisz się do newslettera, żeby nie pominąć go.
Jeśli masz pytania lub znalazłeś błąd w artykule, daj znać w komentarzu. Jeśli spodobał Ci się, udostępnij go 🙂
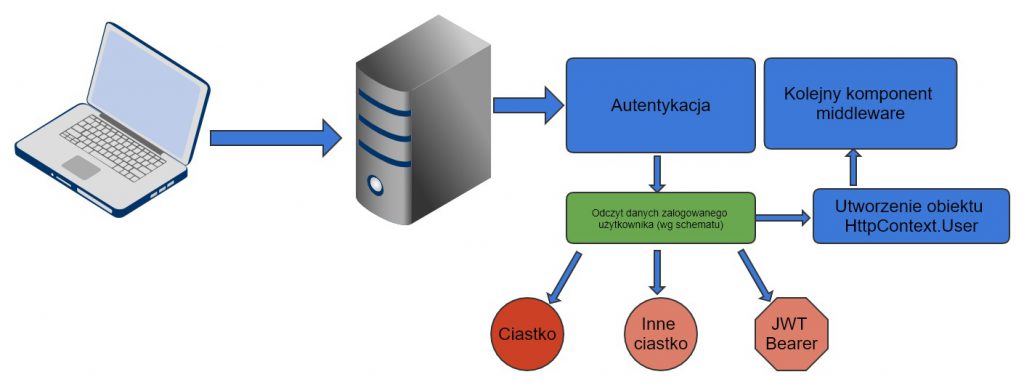
Teraz już możesz logować i wylogowywać użytkowników.
Logowanie
Zidentyfikuj użytkownika ręcznie – po prostu w jakiś sposób musisz sprawdzić, czy podał prawidłowe dane logowania (login i hasło)
Stwórz ClaimsPrincipal dla tego użytkownika
Wywołaj HttpContext.SignIn -> to utworzy ciastko logowania i użytkownik będzie już uwierzytelniony w kolejnych żądaniach (HttpContext.User będzie zawierało wartość utworzoną w kroku 2)
Wylogowanie
Wywołaj HttpContext.SignOutAsync -> to zniszczy ciastko logowania. W kolejnych żądaniach obiekt HttpContext.User będzie pusty.
Jeśli masz jakiś problem, przeczytaj pełny artykuł poniżej.
UWAGA
W słowniku języka polskiego NIE ISTNIEJE słowo autentykacja. W naszym języku ten proces nazywa się uwierzytelnianiem. Słowo autentykacja zostało zapożyczone z angielskiego authentication. Dlatego też w tym artykule posługuję się słowem uwierzytelnianie.
Po co komu uwierzytelnianie bez Identity?
Może się to wydawać dziwne, no bo przecież Identity robi całą robotę. Ale jeśli chcesz uwierzytelniać użytkowników za pośrednictwem np. własnego WebApi albo innego mechanizmu, który z Identity po prostu nie współpracuje, to nie ma innej możliwości.
Uwierzytelnianie vs Identity
Musisz zdać sobie sprawę, że mechanizm uwierzytelniania i Identity to dwie różne rzeczy. Identity korzysta z uwierzytelniania, żeby mechanizm był pełny. A jakie są różnice?
Co daje Identity
Od Identity dostajesz CAŁĄ obsługę użytkownika. Tzn:
przechowywanie użytkowników (np. tworzenie odpowiednich tabel w bazie danych lub obsługa innego sposobu przechowywania danych użytkowników)
zarządzanie rolami użytkowników
i generalnie wiele innych rzeczy, które mogą być potrzebne w standardowej aplikacji
Mechanizm Identity NIE JEST dostępny na „dzień dobry”. Aby go otrzymać, możesz utworzyć nową aplikację z opcją Authentication type ustawioną np. na Individual Accounts.
Możesz też doinstalować odpowiednie NuGety i samemu skonfigurować Identity.
Co daje uwierzytelnianie?
tworzenie i usuwanie ciasteczek logowania (lub innego mechanizmu uwierzytelniania użytkownika)
tworzenie obiektu User w HttpContext podczas żądania
przekierowania użytkowników na odpowiednie strony (np. logowania, gdy nie jest zalogowany)
Jak widzisz, Identity robi dużo więcej i pod spodem korzysta z mechanizmów uwierzytelniania. Podczas konfiguracji Identity konfigurujesz również uwierzytelnianie.
Konfiguracja uwierzytelniania
Najprościej będzie, jeśli utworzysz projekt BEZ żadnej identyfikacji. Po prostu podczas tworzenia nowego projektu upewnij się, że opcja Authentication type jest ustawiona na NONE:
Dzięki temu nie będziesz miał dodanego ani skonfigurowanego mechanizmu Identity. I dobrze, bo jeśli go nie potrzebujesz, to bez sensu, żeby zaciemniał i utrudniał sprawę. Mechanizm Identity możesz sobie dodać w każdym momencie, instalując odpowiednie NuGety.
A teraz jak wygląda konfiguracja uwierzytelniania? Składa się tak naprawdę z trzech etapów:
zarejestrowania serwisów dla uwierzytelniania
konfiguracji mechanizmu, który będzie używany do odczytywania (zapisywania) informacji o zalogowanym użytkowniku (schematu)
dodanie uwierzytelniania do middleware pipeline.
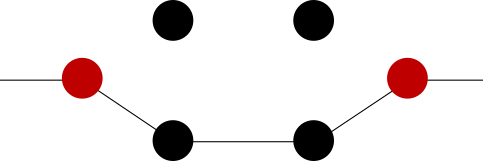
Schemat
Zanim pójdziemy dalej, wyjaśnię Ci czym jest schemat. To nic innego jak określenie sposobu w jaki użytkownicy będą uwierzytelniani. Różne scenariusze mogą wymagać różnych metod uwierzytelniania. Każda z tych metod może wymagać innych danych. To jest właśnie schemat. Pisząc uwierzytelniać mam na myśli taki flow (w skrócie):
Klient wysyła żądanie do serwera (np. żądanie wyświetlenia strony z kontem użytkownika)
Mechanizm uwierzytelniania (który jest w middleware pipeline) rusza do roboty. Sprawdza, czy użytkownik jest już zalogowany, odczytując jego dane wg odpowiedniego schematu (z ODPOWIEDNIEGO ciastka, bearer token’a, BasicAuth lub jakiegokolwiek innego mechanizmu)
Na podstawie informacji odczytanych w punkcie 2, tworzony jest HttpContext.User
Rusza kolejny komponent z middleware pipeline
Każdy schemat ma swoją własną nazwę, możesz tworzyć własne schematy o własnych nazwach jeśli czujesz taką potrzebę.
Rejestracja serwisów uwierzytelniania
W pliku Program.cs lub Startup.cs (w metodzie ConfigureServices) możesz zarejestrować wymagane serwisy w taki sposób:
builder.Services.AddAuthentication();
To po prostu zarejestruje standardowe serwisy potrzebne do obsługi uwierzytelniania. Jednak bardziej przydatną formą rejestracji jest ta ze wskazaniem domyślnych schematów:
Jak już wiesz, każdy schemat ma swoją nazwę. W .NET domyślne nazwy różnych schematów są zapisane w stałych. Np. domyślna nazwa schematu opartego na ciastkach (uwierzytelnianie ciastkami) ma nazwę zapisaną w CookieAuthenticationDefaults. Analogicznie domyślna nazwa schematu opartego na JWT Bearer Token – JwtBearerDefaults.
Oczywiście, jeśli masz taką potrzebę, możesz nadać swoją nazwę.
Konfiguracja ciasteczka logowania
To drugi krok, jaki trzeba wykonać. Konfiguracja takiego ciastka może wyglądać tak:
W pierwszym parametrze podajesz nazwę schematu dla tego ciastka. W drugim ustawiasz domyślne opcje. Jeśli nie wiesz co one oznaczają i dlaczego tak, a nie inaczej, przeczytaj artykuł o ciastkach, w którym to wyjaśniam.
Na koniec ustawiasz dwie ścieżki:
ścieżka do strony z informacją o zabronionym dostępie
ścieżka do strony logowania
a także parametr return_url – o nim za chwilę.
Po co te ścieżki? To ułatwienie – element mechanizmu uwierzytelniania. Jeśli niezalogowany użytkownik wejdzie na stronę, która wymaga uwierzytelnienia (np. „Napisz nowy post”), wtedy automatycznie zostanie przeniesiony na stronę, którą zdefiniowałeś w LoginPath.
Analogicznie z użytkownikiem, który jest zalogowany, ale nie ma praw dostępu do jakiejś strony (np. modyfikacja użytkowników, do czego dostęp powinien mieć tylko admin) – zostanie przekierowany automatycznie na stronę, którą zdefiniowałeś w AccessDeniedPath.
Dodanie uwierzytelniania do middleware pipeline
Skoro mechanizm uwierzytelniania jest już skonfigurowany, musimy dodać go do pipeline. Pamiętaj, że kolejność komponentów w pipeline jest istotna. Dodaj go tuż przed autoryzacją:
To jest zwykły formularz ze stylami bootstrapa. Mamy trzy pola:
nazwa użytkownika
hasło
checkbox – pamiętaj mnie, żeby użytkownik nie musiał logować się za każdym razem
Nie stosuję tutaj żadnych walidacji, żeby nie zaciemniać obrazu.
Obsługa logowania
Teraz trzeba obsłużyć to logowanie – czyli przesłanie formularza. Do modelu strony dodaj metodę OnPostAsync (fragment kodu):
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
}
ApplicationUser Authorize(string name, string pass)
{
if (name == "Admin" && pass == "Admin")
{
ApplicationUser result = new ApplicationUser();
result.UserName = "Admin";
result.Id = 1;
return result;
}
else
return null!;
}
W trzeciej linijce walidujemy przekazany w formularzu model. Chociaż w tym przypadku testowym nie ma czego walidować, to jednak pamiętaj o tym.
W linijce 6 następuje próba zalogowania użytkownika. Przykładowa metoda Authorize jest oczywiście beznadziejna, ale zwróć tylko uwagę na to, co robi. W jakiś sposób sprawdza, czy login i hasło są poprawne (np. wysyłając dane do WebAPI). I jeśli tak, zwraca konkretnego użytkownika. Jeśli nie można było takiego użytkownika zalogować, zwraca null.
Zawartość metody Authorize zależy całkowicie od Ciebie. W przeciwieństwie do mechanizmu Identity, tutaj sam musisz stwierdzić, czy dane logowania użytkownika są poprawne, czy nie.
W następnej linijce sprawdzam, czy udało się zalogować użytkownika. Jeśli nie, wtedy ustawiam jakiś komunikat błędu i przeładowuję tę stronę.
A co jeśli użytkownika udało się zalogować? Trzeba stworzyć dla niego ciastko logowania. Ale to wymaga utworzenia obiektu ClaimsPrincipal.
Czym jest ClaimsPrincipal?
Krótko mówiąc, jest to zbiór danych, który przechowuje informacje na temat zalogowanego użytkownika. Pewnie chcesz zadać pytanie – czy to nie może być moja super klasa User? Nie, nie może. ClaimsPrincipal to pewien standardowy sposób przechowywania i przesyłania danych.
Wyobraź sobie, że jesteś strażnikiem w dużej firmie. Teraz podchodzi do Ciebie gość, który mówi, że jest dyrektorem z innej firmy, przyszedł na spotkanie i nazywa się Jan Kowalski. Sprawdzasz jego dowód (uwierzytelniasz go) i stwierdzasz, że faktycznie nazywa się Jan Kowalski. Co więcej, możesz stwierdzić że zaiste jest dyrektorem i przyszedł na spotkanie. Wydajesz mu zatem swego rodzaju dowód tożsamości – to może być identyfikator, którym będzie się posługiwał w Twojej firmie.
Teraz tego gościa możemy przyrównać do ClaimsPrincipal, a identyfikator, który mu wydałeś to ClaimsIdentity (będące częścią ClaimsPrincipal).
Na potrzeby tego artykułu potraktuj to właśnie jako zbiór danych identyfikujących zalogowanego użytkownika.
Tworzenie tożsamości (ClaimsPrincipal)
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
ClaimsPrincipal principal = CreatePrincipal(loggedUser);
}
ClaimsPrincipal CreatePrincipal(ApplicationUser user)
{
ClaimsPrincipal result = new ClaimsPrincipal();
List<Claim> claims = new List<Claim>()
{
new Claim(ClaimTypes.NameIdentifier, user.Id.ToString()),
new Claim(ClaimTypes.Name, user.UserName)
};
ClaimsIdentity identity = new ClaimsIdentity(claims);
result.AddIdentity(identity);
return result;
}
Tutaj tworzymy tożsamość zalogowanego użytkownika i dajemy mu dwa „poświadczenia” – Id i nazwę użytkownika. Mając utworzony obiekt ClaimsPrincipal, możemy teraz utworzyć ciastko logowania. To ciastko będzie przechowywało dane z ClaimsPrincipal:
await HttpContext.SignInAsync(principal);
Pamiętaj, żeby dodać using: using Microsoft.AspNetCore.Authentication;
Teraz niepełny kod wygląda tak:
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
ClaimsPrincipal principal = CreatePrincipal(loggedUser);
await HttpContext.SignInAsync(principal);
}
Podsumujmy tę część:
Walidujesz model otrzymany z formularza
W jakiś sposób sprawdzasz, czy przekazany login i hasło są prawidłowe – „ręcznie” uwierzytelniasz użytkownika
Na podstawie uwierzytelnionego użytkownika tworzysz obiekt ClaimsPrincipal, który jest potrzebny do utworzenia ciastka logowania.
Tworzysz ciastko logowania. Od tego momentu, w każdym żądaniu, obiekt HttpContext.User będzie miał te wartości, które utworzyłeś w kroku 3. Wszystko dzięki ciastku logowania, które przy każdym żądaniu utworzy ten obiekt na podstawie swoich wartości.
Nie musisz tutaj podawać schematu uwierzytelniania, ponieważ zdefiniowałeś domyślny schemat podczas konfiguracji uwierzytelniania.
Pamiętaj mnie
W powyższym kodzie nie ma jeszcze użytej opcji „Pamiętaj mnie”. Ta opcja musi zostać dodana podczas tworzenia ciastka logowania. Wykorzystamy tutaj przeciążoną metodę SignInAsync, która przyjmuje dwa parametry:
Czyli do właściwości IsPersistent przekazałeś wartość pobraną od użytkownika, który powiedział, że chce być pamiętany w tej przeglądarce (true) lub nie (false). O tym właśnie mówi IsPersistent.
Ale ten kod wciąż nie jest pełny.
Przekierowanie po logowaniu
Po udanym (lub nieudanym) logowaniu trzeba gdzieś użytkownika przekierować. Najwygodniej dla niego – na stronę, na którą próbował się dostać przed logowaniem. Spójrz na taki przypadek:
niezalogowany użytkownik wchodzi na Twoją stronę, żeby zobaczyć informacje o swoim koncie: https://www.example.com/Account
System uwierzytelniania widzi, że ta strona wymaga poświadczeń (gdyż jest opatrzona atrybutem Authorize), a użytkownik nie jest zalogowany. Więc zostaje przekierowany na stronę logowania. A skąd wiadomo gdzie jest strona logowania? Ustawiłeś ją podczas konfiguracji ciastka do logowania.
Po poprawnym zalogowaniu użytkownik może zostać przekierowany np. na stronę domową: "/Index" albo lepiej – na ostatnią stronę, którą chciał odwiedzić, w tym przypadku: https://www.example.com/Account
Ale skąd masz wiedzieć, na jaką stronę go przekierować? Spójrz jeszcze raz na konfigurację ciastka logowania:
Jeśli mechanizm uwierzytelniania przekierowuje Cię na stronę logowania, dodaje do adresu parametr, który skonfigurowałeś w ReturnUrlParameter. A więc w tym przypadku "return_url". Ostatecznie niezalogowany użytkownik zostanie przekierowany na taki adres: https://example.com/Login?return_url=/Account
(w przeglądarce nie zauważysz znaku „/”, tylko jego kod URL: %2F)
To znaczy, że na stronie logowania możesz ten parametr pobrać:
public class LoginPageModel : PageModel
{
[BindProperty]
public string UserName { get; set; } = string.Empty;
[BindProperty]
public string Password { get; set; } = string.Empty;
[BindProperty]
public bool RememberMe { get; set; }
[FromQuery(Name = "return_url")]
public string? ReturnUrl { get; set; }
//
}
Pamiętaj, że parametru return_url nie będzie, jeśli użytkownik wchodzi bezpośrednio na stronę logowania. Dlatego też zwróć uwagę, żeby oznaczyć go jako opcjonalny – string?, a nie string
Następnie wykorzystaj go podczas logowania:
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
ClaimsPrincipal principal = CreatePrincipal(loggedUser);
AuthenticationProperties props = new AuthenticationProperties();
props.IsPersistent = RememberMe;
await HttpContext.SignInAsync(principal, props);
if (string.IsNullOrWhiteSpace(ReturnUrl))
ReturnUrl = "/Index";
return RedirectToPage(ReturnUrl);
}
UWAGA!
Pamiętaj, żeby w takim przypadku NIE STOSOWAĆ metody Redirect, tylko RedirectToPage (lub w RazorView – RedirectToAction). Metoda Redirect pozwala na przekierowanie do zewnętrznego serwisu, co w tym przypadku daje podatność na atak „Open Redirect”. Dlatego też stosuj RedirectToPage -> ta metoda nie pozwoli na przekierowanie zewnętrzne.
Wylogowanie
Kiedyś użytkownik być może będzie się chciał wylogować. Na czym polega wylogowanie? Na usunięciu ciastka logowania. Robi się to jedną metodą:
await HttpContext.SignOutAsync();
Ta metoda usunie ciastko logowania i w kolejnych żądaniach obiekt HttpContext.User będzie pusty.
To właściwie tyle jeśli chodzi o mechanizm uwierzytelniania. Jeśli czegoś nie rozumiesz lub znalazłeś błąd w artykule, daj znać w komentarzu. Jeśli uważasz ten artykuł za przydatny, również daj znać. Będzie mi miło 🙂 I koniecznie zapisz się na newsletter, żeby nic Cię nie ominęło.
W 2018 roku weszło RODO. Wszystkie strony działające na terenie Unii Europejskiej (to dotyczy też np. sklepów w USA, na których można kupować mieszkając w UE) muszą mieć odpowiednie mechanizmy zabezpieczające politykę prywatności i dane. O tych mechanizmach jest ten artykuł.
Jeśli masz małe pojęcie o ciasteczkach lub nie znasz ich do końca (nie znasz ich parametrów), przeczytaj ten artykuł.
Co z tym RODO?
Jakiś czas temu na terenie Unii Europejskiej weszło GDPR (po polsku RODO). W skrócie, jeśli chodzi o ciasteczka, użytkownik musi zostać poinformowany o polityce prywatności, a także musi zaakceptować niektóre ciasteczka. Poza tym RODO nakłada obowiązek odpowiedniego przetwarzania danych osobowych, co wiąże się z bezpieczeństwem tych danych, administracją itd. Ale nie o tym nie o tym.
.NET ma już gotowe mechanizmy, które wystarczy podpiąć. Pytanie tylko – czy tego potrzebujesz?
Zaznaczam, że nie jestem prawnikiem. Generalnie jeśli zbierasz jakiekolwiek informacje o użytkowniku za pomocą ciasteczek (chociażby listę rzeczy, które kupił w Twoim sklepie lub ostatnio zakupiony produkt albo też śledzisz jego ruchy na Twojej witrynie), to prawnie powinieneś go o tym poinformować, a on musi na to wyrazić zgodę. Jeśli tego nie zrobisz, to Ty możesz mieć później problemy prawne i płacić kary. Także nie lekceważ tego obowiązku. Większość użytkowników i tak zawsze klika „OK”, nie czytając nawet polityki prywatności. A gotowy mechanizm załatwia wszystko.
Google Analytics i inne aplikacje śledzące
Pamiętaj też, że jeśli używasz google analytics, czy też Smartlook (pokazuje dokładnie co użytkownik robi na Twojej stronie – jak na filmie – polecam), to też musisz o tym poinformować.
Polityka prywatności
Na pierwszy ogień idzie polityka prywatności, którą musisz mieć na swojej stronie. Na szczęście domyślny szablon WebApplication z VisualStudio ma już taką stronę – Privacy.cshtml. Powinieneś tam właśnie wpisać swoją politykę. Pewnie teraz pytanie – skąd to wziąć? Odpowiedź prawilna – skontaktuj się z prawnikiem; odpowiedź nieprawilna – skopiuj z podobnej strony. Ale na BOGA! Przeczytaj ją, zrozum i zmodyfikuj pod swoje potrzeby. I najlepiej daj ją na koniec do przeczytania prawnikowi, niech się wypowie. To Ty jesteś za to odpowiedzialny…
Teraz skonfigurujemy mechanizm wyrażania zgody na ciasteczka. Ta informacja (czy user wyraził zgodę, czy nie) jest zapisywana w… ciasteczku 😉 Ale to specjalne „ciasteczko zgody”, które na stronie MUSI być i jest niezbędne do prawidłowego działania aplikacji (esencjonalne).
W pliku Startup.cs w metodzie ConfigureServices dodaj taki kod:
CookiePolicyOptions ma jeszcze kilka ciekawych elementów:
OnDeleteCookie – akcja wywoływana podczas usuwania ciasteczka
ConsentCookie – parametry ciasteczka, które zapamiętuje zgodę użytkownika na ciasteczka 🙂
OnAppendCookie – akcja wywoływana podczas dodawania ciasteczka
Secure – czy ciasteczka muszą być bezpieczne (CookieOptions.Secure = true)
HttpOnly – czy ciasteczka muszą mieć atrybut HttpOnly
Dodanie polityki do middleware
Następnie w metodzie Configure musisz dodać tę politykę do middleware:
app.UseStaticFiles();
app.UseCookiePolicy();
Dodaj to za UseStaticFiles i przed UseRouting. Właściwie przed jakimkolwiek użyciem ciasteczek śledzących.
Konfiguracja w .NET6
Jeśli używasz .NET6, możesz nie mieć pliku Startup.cs i metod ConfigureServices i Configure. W takim przypadku dodajesz te elementy normalnie w pliku Program.cs analogicznie do innych, np:
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddControllersWithViews();
builder.Services.Configure<CookiePolicyOptions>(options =>
{
options.CheckConsentNeeded = context => true;
options.MinimumSameSitePolicy = SameSiteMode.None;
});
var app = builder.Build();
// Configure the HTTP request pipeline.
if (!app.Environment.IsDevelopment())
{
app.UseExceptionHandler("/Home/Error");
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseCookiePolicy();
UWAGA!
Pamiętaj, że mechanizm polityki zablokuje tworzenie ciasteczek, jeśli użytkownik nie wyrazi na nie zgody. Podczas tworzenia takiego ciastka, które nie jest oznaczone jako IsEssential zostanie wywołany cichy wyjątek i ciasteczko nie zostanie dołączone do odpowiedzi idącej do przeglądarki. Jeśli jednak masz na stronie ciastka, które niczego nie śledzą, ale są konieczne do poprawnego działania serwisu, oznacz je jako essential: CookieOptions.IsEssential = true. Takie ciastko zostanie zapisane nawet jeśli użytkownik nie wyrazi zgody na śledzenie. Pamiętaj tylko, że te ciastka nie mogą śledzić jego ruchów.
Dodanie informacji do widoku/strony
Teraz musisz dodać informację o ciasteczkach do swoich widoków. Po prostu zmodyfikuj _Layout.cshtml. Odszukaj div z klasą container i dodaj w nim partialview:
Teraz dodaj plik _CookieConsentPartial.cshtml do folderu Views/Shared lub Pages:
@using Microsoft.AspNetCore.Http.Features
@{
var consentFeature = Context.Features.Get<ITrackingConsentFeature>();
var showBanner = !consentFeature?.CanTrack ?? false;
var cookieString = consentFeature?.CreateConsentCookie();
}
@if (showBanner)
{
<div id="cookieConsent" class="alert alert-dark alert-dismissible fade show" role="alert">
Strona używa ciasteczek. <a asp-controller="Home" asp-action="Privacy">Przeczytaj naszą politykę prywatności</a>.
<button type="button" class="accept-policy close" data-dismiss="alert" aria-label="Close" data-cookie-string="@cookieString">
<span aria-hidden="true">Akceptuję</span>
</button>
</div>
<script>
(function () {
var button = document.querySelector("#cookieConsent button[data-cookie-string]");
button.addEventListener("click", function (event) {
document.cookie = button.dataset.cookieString;
}, false);
})();
</script>
}
W tym kodzie nie ma niczego dziwnego (pochodzi z oficjalnej dokumentacji Microsoftu i korzysta z Bootstrapa). Po prostu dopisz tutaj swój komunikat albo skonstruuj własnego diva. Ważne jest to, żeby pokazać tego diva jeśli użytkownik nie wyraził zgody na ciasteczka i nie pokazywać go, gdy wyraził.
Po wciśnięciu przycisku, JavaScript zapisze cookie przesłane w danych tego przycisku (atrybut data-cookie-string). Zauważ, że cały string tworzący cookie otrzymałeś z metody CreateConsentCookie().
Po wyrażeniu zgody w taki sposób (zapisaniu ciasteczka z CreateConsentCookie()), framework już normalnie obsłuży wszystkie Twoje ciastka.
I to właściwie tyle. Jeśli czegoś nie rozumiesz albo znalazłeś błąd w tekście, daj znać w komentarzu
Skoro tu jesteś to pewnie używałeś ciasteczek, być może nie do końca świadomie albo nie wiedząc o pewnych niuansach. W tym artykule wyjaśnię czym dokładnie są te ciasteczka i opiszę wszystkie zawiłości, na jakie kiedykolwiek trafiłem. Więc nawet jeśli używasz ciasteczek, ten artykuł może Ci trochę rozjaśnić i odpowiedzieć na kilka pytań, które bałeś się zadać.
Czym są ciasteczka
Ciasteczko to nic innego jak dane przechowywane na komputerze użytkownika. To string składający się z pary klucz=wartość i kilku atrybutów. Ciasteczko zazwyczaj (w zależności od przeglądarki) jest fizycznie reprezentowane jako plik. Każde ciasteczko ma swoją nazwę (klucz). Powoduje to, że do jego zawartości możemy się dobrać właśnie przez nazwę w taki sposób (pseudokod):
string dane = GetCookieByName("moje_ciastko");
SetCookieByName("moje_ciastko", "całkiem nowe dane");
Ciasteczko ma też kilka właściwości jak np. data ważności (expire date). Ale o tym później.
Ma też ograniczenie co do ilości danych – w zależności od przeglądarki, ale załóż, że maks to 4 kB.
Ciasteczka są przesyłane z klienta do serwera i na odwrót za pomocą nagłówków HTTP. Więc staraj się, żeby jednak były małe. I staraj się, żeby nie było ich zbyt dużo.
Teraz możesz zadać pytanie – „ale jak to przesyłane w nagłówku, skoro są na komputerze użytkownika?”
No tak, ale z każdym żądaniem (np. żądanie wyświetlenia strony) przeglądarka wysyła do serwera wszystkie ciastka dla danej strony. Serwer też może wysłać w odpowiedzi na żądanie specjalny nagłówek, który spowoduje, że przeglądarka zapisze ciastko. O tym wszystkim już za chwilę.
Po co ciasteczka?
Wszystko rozbija się o to, że HTTP jest protokołem bezstanowym. Oznacza to, że pomiędzy dwoma wyświetleniami strony nie zachowuje się żaden stan – nie można przechować zmiennych. One są niszczone za każdym razem. Nie można nawet sprawdzić, kto jest zalogowany. Trzeba było ogarnąć jakiś sposób na zarządzanie stanem w aplikacjach internetowych. Jednym z tych sposobów są ciasteczka.
Czym się różni sesja od ciasteczka?
W dużym skrócie sesje też są zbiorem danych. Działają podobnie do ciasteczek, tylko są zapisywane na serwerze. Ciasteczka natomiast zapisują się na komputerze użytkownika. Sesje mogą zależeć od ciasteczek (np. ciasteczko może przechowywać id sesji), ale nie na odwrót. Co więcej sesja kończy się w momencie wylogowania, natomiast ciasteczko – gdy skończy mu się okres ważności (może to być tak długie jak kilka lat albo tak krótkie jak otwarcie przeglądarki). Sesje nie mają też żadnego narzuconego ograniczenia co do ilości danych.
Ciasteczka trwałe i nietrwałe
Ciasteczka mogą być trwałe (persistent) lub nietrwałe (non-persistent). Trwałe ciasteczko jest zapisywane w pliku na dysku użytkownika lub w bazie przeglądarki. Nietrwałe ciasteczka istnieją tylko w pamięci przeglądarki. Nazywa się je również „ciasteczkami sesyjnymi”. Takie ciasteczka tworzy się nie nadając im daty ważności. Czyli ich życie kończy się wraz z zamknięciem przeglądarki.
Tworzenie ciasteczka
Ciasteczko może zostać utworzone przez klienta, jak również przez serwer (to pewien skrót myślowy). W tym drugim przypadku serwer w odpowiedzi na żądanie wysyła nagłówek (Set-Cookie) z ciasteczkiem, który jest odczytywany przez przeglądarkę i ona piecze takie ciasteczko.
W pierwszym przypadku ciasteczko jest zapisywane przez… ehhh… JavaScript.
Teraz będziemy robić kody. Stwórz sobie jakiś projekt testowy, niech to będzie domyślne Asp NetCore WebApp (MVC lub RazorPages) z VisualStudio.
Ciasteczko w JavaScript
Otwórz plik Index.cshtml. Dodaj tam przycisk, który zapisze ciasteczko:
Kod jest bardzo prosty – wciśnięcie przycisku odpala funkcję w JavaScript, która ustawia ciasteczko. Nazwa tego ciasteczka (klucz) to username, a wartość „Adam”. Równie dobrze mógłby tam być cały obiekt zapisany w JSON.
Uruchom teraz ten przykład, ale nie wciskaj jeszcze guzika. Uruchom narzędzia dla developerów w swojej przeglądarce. Ja używam FireFoxa i do tego jest skrót Ctrl + Shift + I. Jeśli nie używasz FireFoxa, w innych przeglądarkach te narzędzia są podobne, więc nie będziesz miał raczej problemu. Tutaj ciasteczka są na karcie DANE.
Spójrz na zawartość ciasteczek w tym oknie:
Widzisz tutaj jakieś 4 ciasteczka na „dzień dobry”. Pochodzą z .NET, nie zajmujmy się nimi teraz.
Wciśnij teraz przycisk, który dodałeś na stronie i zobacz, co się stanie. Powstało nowe ciasteczko o nazwie username:
To ciasteczko będzie żyło aż do zamknięcia przeglądarki. Możesz mu podać też expire date, który usunie konkretne ciasteczko (jeśli data będzie w przeszłości) lub nada mu konkretny czas życia. Wszystko to jest dokładnie opisane na w3schools więc nie będę się rozwodził na temat JavaScriptu więcej 😉
Ciasteczko w .NET
JavaScript jest o tyle miłe, że działa na kliencie. To znaczy, że może utworzyć ciasteczko bezpośrednio na Twoim komputerze. .NET jednak działa na serwerze, co nam daje trochę więcej komunikacji między klientem a serwerem. Czasem też nie da się inaczej:
klient musi wysłać żądanie do serwera (np. GET http://moja-strona.pl)
serwer musi odebrać to żądanie, przetworzyć je i odpowiedzieć na nie, wysyłając ciasteczko
przeglądarka odbierze ciasteczko i zapisze je na dysku lub w swojej bazie.
Zróbmy teraz te wszystkie kroki za pomocą małego formularza. W pliku index.cshtml stwórz prostą formatkę:
Następnie stwórz odpowiednią akcję w kontrolerze (analogicznie to będzie w Razor Pages). W pliku HomeController.cs dopisz metodę Index z metodą POST – to tutaj zostanie wysłany formularz:
Spójrz jak to teraz wygląda. Po kliknięciu przycisku, wysyłane jest żądanie z formularzem na serwer. Na serwerze odczytujemy wartość formularza i do response’a (czyli odpowiedzi, którą generujemy dla klienta) dodajemy nowe ciasteczko. Przeglądarka po otrzymaniu takiej odpowiedzi (z ciasteczkiem) tworzy je fizycznie.
Odczyt ciasteczka
Ciasteczko możemy odczytać też za pomocą JavaScript lub .NET. Jednak JavaScript dostaje wszystkie ciastka dla danej strony, więc sami sobie je musimy parsować. W .NET już to jest zrobione normalnie. Musimy tylko odczytać je na serwerze podczas żądania.
Pamiętaj, że otrzymujesz tylko swoje ciasteczka. Tzn. przeglądarka zwróci ciasteczka tylko dla konkretnej domeny – dla tej, która je utworzyła (z małym wyjątkiem – o tym później). Czyli jeśli wysyłasz żądanie do strony example.com, przeglądarka doda do nagłówków ciasteczka utworzone przez example.com.
Zmień zatem metodę Index (tę domyślną) w taki sposób, aby odczytać to ciasteczko:
public IActionResult Index()
{
var userName = HttpContext.Request.Cookies["username_fromnet"];
ViewData["userName"] = userName;
return View();
}
Zwróć uwagę, że tym razem odczytujemy ciastko z HttpContext.Request – czyli z żądania, które idzie od klienta do serwera. Zapisujemy ciasteczko w odpowiedzi na to żądanie, czyli w HttpContext.Response.
Gdy użytkownik uruchamia aplikację, idzie żądanie do serwera (wraz z wszystkimi ciasteczkami odczytanymi przez przeglądarkę) i wchodzi do metody Index. Stąd odczytujemy sobie konkretne ciasteczko i przekazujemy jego wartość do danych widoku. Na koniec pokazujemy widok, który lekko się zmienił:
Pobieramy dane z ViewData do zmiennej userName. Jeśli teraz ta zmienna nie ma żadnej wartości, to wyświetlamy formularz. Jeśli ma – wyświetlamy powitanie.
Parametry ciasteczka
Jak pisałem wyżej, ciasteczko może mieć swoje parametry. Klasą, która je opisuje jest CookieOptions:
CookieOptions.Expires
Określa czas życia ciasteczka. Zazwyczaj po prostu dodaje się jakąś datę do aktualnej, np. DateTime.Now.AddDays(30). Ciasteczko zostanie usunięte po tej dacie. Co jednocześnie powoduje, że jeśli podasz datę wcześniejszą niż aktualna, ciasteczko zostanie usunięte natychmiast. Pamiętaj, że na serwerze możesz mieć inną datę niż na komputerze użytkownika. Więc ostrożnie z tym.
CookieOptions.MaxAge
Działa podobnie do Expires. Też określa czas życia ciasteczka z tą różnicą, że nie podajesz daty zakończenia życia, tylko jego czas, np: MaxAge = TimeSpan.FromDays(30) – takie ciasteczko po 30 dniach od utworzenia zostanie usunięte. Jest to nowsza, lepsza i bardziej wygodna opcja niż Expires.
CookieOptions.Domain
Domyślnie ciasteczko należy do domeny, która je utworzyła. Czyli jeśli utworzysz ciasteczko z domeny example.com, zostanie ono odczytane zarówno dla domeny example.com, jak i SUBDOMENY www – www.example.com. Jeśli jednak ciasteczko zostanie utworzone z subdomeny www – www.example.com, nie będzie widoczne z domeny example.com. Dlatego też powinieneś skonfigurować domenę na domenę główną, np: CookieOptions.Domain = ".example.com" (kropka na początku) To spowoduje, że ciasteczko będzie dostępne zarówno z domeny głównej jak i z wszystkich subdomen (w szczególności „www”). Jeśli więc masz problem, bo raz ciasteczko działa a raz nie, to pewnie dlatego, że raz Twoja strona jest uruchamiana z subdomeny (www.example.com), a raz nie. Przyjrzyj się temu.
Pamiętaj, że „www” jest subdomeną. Takich subdomen możesz mieć wiele, np: mail.example.com, dev.example.com, git.example.com… Ale chciałbyś, żeby ciasteczka działały tylko na subdomenie www i domenie głównej. Jak to zrobić?
Nie znalazłem na to odpowiedzi, a wszystkie moje testy się nie powiodły. Jeśli masz pomysł, koniecznie podziel się w komentarzu. Z mojej wiedzy wynika, że można mieć ciasteczko albo dla wszystkich subdomen i domeny głównej, albo dla jednej subdomeny, albo dla domeny głównej.
CookieOptions.Path
Podobnie do Domain. Z tą różnicą, że tutaj chodzi o ścieżkę w adresie. Domyślnie Path jest ustawiane na „/”, co oznacza, że ciasteczko będzie dostępne dla wszystkich podstron/routów z Twojego serwisu. Jeśli jednak ustawisz np. na "/login/" oznacza to, że ciasteczko będzie dostępne tylko ze ściezki "login" i dalszych, np: www.example.com/login, www.example.com/login/facebook
CookieOptions.HttpOnly
To specjalny rodzaj ciastka mający na celu zapobieganie pewnym atakom (np. XSS – Cross site scripting). Oczywiście nie polegaj na tym w 100%. Generalnie chodzi o to, że ciastka z takim atrybutem nie mogą (nie powinny) być odczytywane przez JavaScript. Po prostu document.cookies nie zwróci takiego ciastka. Możesz jedynie odczytać je na serwerze – HttpContext.Request.Cookies.
CookieOptions.Secure
Jeśli ustawione na true, ciasteczko zostanie wysłane z przeglądarki do serwera tylko wtedy, jeśli komunikacja odbywa się po HTTPS.
CookieOptions.SameSite
Ten parametr odpowiada za bezpieczeństwo ciasteczek. Ciastka są z natury podatne na pewne ataki. Atrybut SameSite ma tą podatność zmniejszyć. Jak?
Wyobraź sobie dwie strony. Twoja – www.example.com i jakaś inna – www.abc.com.
Na stronie www.abc.com znajduje się ramka (iframe), do której ładowana jest Twoja strona. A więc ze strony www.abc.com idzie żądanie do Twojej. W tym momencie przeglądarka odczytuje Twoje ciasteczka i wysyła je do strony www.abc.com.
Możesz teraz zrobić prosty test. Poniżej masz przycisk i ramkę. Otwórz narzędzia deweloperskie (Shift + Ctrl + I) i przejdź na zakładkę „Sieć” (Network). Teraz wciśnij poniższy przycisk (Załaduj Google do ramki) i zobacz, co się dzieje w „sieci”. Poszło żądanie do Google wraz z odpowiedziami – co więcej niektóre odpowiedzi zawierają ciasteczka (to nagłówki „Set-Cookie”)
Wyobraź sobie teraz taką sytuację, że masz stronę, na której ktoś jest zalogowany. Id sesji znajduje się w zwykłym ciasteczku. Teraz, jeśli taki zalogowany użytkownik otworzy tak spreparowaną stronę, ta strona dostanie to właśnie ciasteczko z id jego sesji. Dzięki temu strona www.abc.com będzie mogła dobrać się do sesji zalogowanego użytkownika w Twoim serwisie i w jego imieniu wykonywać operacje. To tak z grubsza. Taki atak nazywa się CSRF (Cross site request forgery).
Przeglądarki nie rozróżniają kto wysłał żądanie – użytkownik, czy inny skrypt. Teraz z pomocą przychodzi atrybut SameSite.
SameSite w .NET może przyjąć 4 wartości:
Unspecified
None
Lax
Strict
Wartość STRICT
Ustawienie SameSite na strict spowoduje, że jeśli żądanie przyjdzie z innej domeny niż ta ustawiona w ciasteczku, ciastko nie zostanie dołączone do odpowiedzi.
Wartość LAX
Jeśli żądanie idzie „bezpieczną” metodą (np. GET) i dodatkowo zmieni się adres w przeglądarce, to wtedy ciasteczka zostaną wysłane.
Wartość NONE
Pozwala na przekazywanie ciasteczek pomiędzy stronami bez żadnych restrykcji.
Wartość UNSPECIFIED
Atrybut w ogóle nie zostanie dołączony do ciasteczka, co spowoduje domyślne zachowanie przeglądarki.
Domyślnie wszystkie ciasteczka w .NET są ustawione na SameSite = Lax.
Oznacza dane ciastko jako niezbędne do funkcjonowania strony. Takie ciastko nie może śledzić poczynań użytkowników.
To właściwie tyle jeśli chodzi o ciastka. Będziesz ich jeszcze używał do automatycznego logowania użytkownika, ale to już temat na inny artykuł, który napiszę wkrótce. Także zapisz się na newsletter, żeby go nie pominąć 🙂
Jest to druga część większego artykułu, więc jeśli jesteś faktycznie zainteresowany pisaniem aplikacji wielojęzycznych, przeczytaj najpierw o globalizacji.
Wstęp
Zanim zabierzemy się za tłumaczenie naszej aplikacji, dobrze jest zrobić coś w rodzaju przeglądu lokalizacji. Coś jak code-review, tylko skupiamy się na elementach globalizacyjnych. To znaczy, że w pierwszym etapie trzeba sprawdzić, czy wszystkie wytyczne z artykułu o globalizacji są spełnione. Jeśli nie – poprawiamy. O tym jest ten artykuł.
Adresy, telefony, nazwiska…
Sprawdź też wszystkie adresy, telefony itd. Te elementy różnie wyglądają w różnych państwach. Niestety czasami wymusza to stosowanie różnych typów modeli lub jakiegoś super modelu. Elementy, na które musisz popatrzeć, to np:
adresy
numery telefonów
rozmiary papieru (!)
jednostki miar (!)
Z niewielką pomocą przychodzi tutaj klasa RegionInfo z namespace System.Globalization. Daje ona kilka przydatnych informacji. Spójrz na jej właściwości:
CurrencyEnglishName – angielska nazwa waluty (np. „polish zloty”)
CurrencyNativeName – lokalna nazwa waluty (np. „złoty polski”)
CurrencySymbol – no to chyba wiadomo 😉
ISOCurrencySymbol – określenie nazwy waluty. Np. CurrencySymbol będzie „€”, a ISO to „EUR”. Dla polski to będzie PLN.
IsMetric – zwraca true, jeśli dany region posługuje się jednostkami metrycznymi. Jeśli ma imperialne, wtedy jest false.
UWAGA! Wiele osób jest przekonanych, że Wielka Brytania posługuje się jednostkami imperialnymi. Nie jest to do końca prawda. Jakiś czas temu zmieniono to oficjalnie na jednostki metryczne, jednak duża część ludzi z przyzwyczajenia używa jeszcze jednostek imperialnych.
Klasa RegionInfo posiada jeszcze kilka innych właściwości, jednak nie uważam ich jako super przydatnych podczas lokalizacji. Można je wyciągnąć innymi metodami.
Aplikacje, które mocno polegają na jednostkach miar (np. AutoCAD) dają swoim użytkownikom możliwość wyboru, czy stosować imperialne jednostki, czy metryczne. I myślę, że to jest dobry pomysł. Pod tym względem traktowałbym klasę RegionInfo jako pomocniczą, a nie jak ostateczny wyznacznik (chociażby ze względu na Anglików).
Przetestuj aplikację
W tym momencie powinieneś zacząć testować aplikację na różnych komputerach, różnych wersjach językowych systemu operacyjnego, posługując się globalnymi danymi. Pomoże Ci to wychwycić pozostałe potencjalne problemy, jak np:
serializacja danych (w szczególności dat i liczb zmiennoprzecinkowych)
wyświetlanie danych zgodnie z regułami
problemy z sortowaniem i porównywaniem stringów
I teraz pewnie powiesz – „Gościu, to ile ja mam mieć komputerów, żeby to wszystko przetestować? Przecież nie będę swojego brudził”. Zgadza się. Jeśli chodzi o testowanie desktopa, wystarczy Ci jeden komputer i wirtualne maszyny na nim. Do tego możesz użyć HyperV lub Oracle Virtual Box. Wszystkie te rozwiązania są darmowe.
Jeśli chodzi o testowanie aplikacji internetowych, to jest prościej. Wystarczy zmienić język w przeglądarce.
Chociaż polecam Ci tak, czy inaczej testy na wirtualnej maszynie ze względu na to, że można pozmieniać ustawienia regionalne w samym systemie. Wtedy dokładnie zobaczysz, co się dzieje z Twoją aplikacją.
Jeśli wszystko jest już gotowe, zapraszam do ostatniego artykułu z serii – lokalizacja.
Pozwolisz, że w artykule będę posługiwał się anglojęzyczną nazwą „tag helper” zamiast „tag pomocniczy”, bo to po prostu brzmi jakby ktoś zajeżdżał tablicę paznokciem.
Czym jest tag helper?
Patrząc od strony Razor (niezależnie czy to RazorPages, czy RazorViews, robi się to identycznie), tag helper to nic innego jak tag w HTML. Ale nie byle jaki. Stworzony przez Ciebie. Kojarzysz z HTML tagi takie jak a, img, p, div itd? No więc tag helper od strony Razor to taki dokładnie tag, który sam napisałeś. Co więcej, tag helpery pozwalają na zmianę zachowania istniejących tagów (np. <a>). Innymi słowy, tag helpery pomagają w tworzeniu wyjściowego HTMLa po stronie serwera.
To jest nowsza i lepsza wersja HTML Helpers znanych jeszcze z czasów ASP.
Na co komu tag helper?
Porównaj te dwa kody z Razor:
<div>
@Html.Label("FirstName", "Imię:", new {@class="caption"})
</div>
Który Ci się bardziej podoba? caption-label to właśnie tag helper. Jego zadaniem jest właściwie to samo, co metody Label z klasy Html. Czyli odpowiednie wyrenderowanie kodu HTML. Jednak… no musisz się zgodzić, że kod z tag helperami wygląda duuuużo lepiej.
(tag helper caption-label nie istnieje; nazwa została zmyślona na potrzeby artykułu)
Tworzenie Tag Helper’ów
Tworzenie nowego projektu
Utwórz najpierw nowy projekt WebApplication w Visual Studio. Jeśli nie wiesz, jak to zrobić, przeczytaj ten artykuł.
Nowy Tag Helper
GitHub i NuGet są pełne customowych (kolejne nieprzetłumaczalne słowo) tag helperów. W samym .NetCore też jest ich całkiem sporo. Nic nie stoi na przeszkodzie, żebyś stworzył własny. Zacznijmy od bardzo prostego przykładu.
Stwórzmy tag helper, który wyśle maila po kliknięciu. Czyli wyrenderuje dokładnie taki kod HTML:
Przede wszystkim musisz zacząć od napisania klasy dziedziczącej po abstrakcyjnej klasie… TagHelper. Chociaż tak naprawdę mógłbyś po prostu napisać klasę implementującą interfejs ITagHelper. Jednak to Ci utrudni pewne rzeczy. Zatem dziedziczymy po klasie TagHelper:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
}
UWAGA! Nazwa Twojej klasy nie musi zawierać sufiksu TagHelper. Jednak jest to dobrą praktyką (tak samo jak tworzenie tag helperów w osobnym folderze TagHelpers lub projekcie). Stąd klasa nazywa się MailTagHelper, ale w kodzie HTML będziemy używać już tagu mail. Takie połączenie zachodzi automagicznie.
Super, teraz musimy zrobić coś, żeby nasz tag helper <mail> zamienił się na HTMLowy tag <a>. Służą do tego dwie metody:
Process – metoda, która zostanie wywołana SYNCHRONICZNIE, gdy serwer napotka na Twój tag helper
ProcessAsync – dokładnie tak jak wyżej, z tą różnicą, że to jest jej ASYNCHRONICZNA wersja
Wynika z tego, że musimy przesłonić albo jedną, albo drugą. Przesłanianie obu nie miałoby raczej sensu. Oczywiście będziemy posługiwać się asynchroniczną wersją, zatem przesłońmy tę metodę najprościej jak się da:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
}
}
Teraz zastanówmy się, jakie parametry chcemy przekazać do helpera. Ja tu widzę dwa:
adres e-mail odbiorcy
tytuł maila
Dodajmy więc te parametry do naszej klasy w formie właściwości:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public string Address { get; set; }
public string Subject { get; set; }
}
Rejestracja Tag Helper’ów
Rejestracja to w tym wypadku to bardzo duże słowo. Niemniej jednak, żeby nasz tag helper był w ogóle widoczny, musimy zrobić jeszcze jedną małą rzecz.
Odnajdź w projekcie plik _ViewImports.cshtml i zmień go tak:
Jeśli Twój tag helper znajduje się w innym namespace (np. umieściłeś go w katalogu TagHelpers), „zaimportuj” ten namespace na początku (moja aplikacja nazywa się WebApplication1): @using WebApplication1.TagHelpers
Następnie „zarejestruj” swoje tag helpery w projekcie, dodając na końcu pliku linijkę: @addTagHelper *, WebApplication1
Ostatecznie mój plik _ViewImports.cshtml wygląda tak:
A teraz małe wyjaśnienie. Nie musisz tego czytać, ale powinieneś.
Plik _ViewImports jest specjalnym plikiem w .NetCore. Wszystkie „usingi” tutaj umieszczone mają wpływ na cały Twój projekt. To znaczy, że usingi z tego pliku będą w pewien sposób „automatycznie” dodawane do każdego Twojego pliku cshtml.
To znaczy, że jeśli tu je umieścisz, to nie musisz już tego robić w innych plikach cshtml. Oczywiście nigdy nie rób tego „na pałę”, bo posiadanie 100 nieużywanych usingów w jakimś pliku jeszcze nigdy nikomu niczego dobrego nie przyniosło 🙂
Zatem w tej linijce @using WebApplication1.TagHelpers powiedziałeś: „Chcę używać namespace’a WebApplication1.TagHelpers na wszystkich stronach w tym projekcie”.
A co do @addTagHelper. To jest właśnie ta „rejestracja” tag helpera. Zwróć najpierw uwagę na to, co dostałeś domyślnie od kreatora projektu: @addTagHelper *, Microsoft.AspNetCore.Mvc.TagHelpers. Zarejestrował on wszystkie domyślne tag helpery.
A teraz spójrz na tę linijkę, którą napisaliśmy: @addTagHelper *, WebApplication1. Jeśli coś Ci tu nie pasuje, to gratuluję spostrzegawczości. A jeśli masz pewność, że to jest ok, to gratuluję wiedzy 🙂
Można łatwo odnieść wrażenie, że rejestrujesz tutaj wszystkie (*) tag helpery z namespace WebApplication1. Jednak @addTagHelper wymaga podania nazwy projektu, a nie namespace’a. Akurat Bill tak chciał, że domyślne tag helpery znajdują się w projekcie o nazwie Microsoft.AspNetCore.Mvc.TagHelpers. Nasz projekt (a przynajmniej mój) nazywa się WebApplication1.
Przypominam i postaraj się zapamiętać:
Klauzula @addTagHelper wymaga podania nazwy projektu, w którym znajdują się tag helpery, a nie namespace’a.
Pierwsze użycie tag helper’a
OK, skoro już tyle popisaliśmy, to teraz użyjemy naszego tag helpera. On jeszcze w zasadzie niczego nie robi, ale jest piękny, czyż nie?
Przejdź do pliku Index.cshtml i dodaj tam naszego tag helpera. Zanim to jednak zrobisz, zbuduj projekt. Może to być konieczne, żeby VisualStudio wszystko zobaczył i zaktualizował Intellisense.
Specjalnie użyłem obrazka zamiast kodu, żeby Ci pokazać, jak Visual Studio rozpoznaje tag helpery. Pokazuje je na zielono (to zielony, prawda?) i lekko pogrubia. Jeśli u siebie też to widzisz, to znaczy, że wszystko zrobiłeś dobrze.
OK, to teraz możesz postawić breakpointa w metodzie ProcessAsync i uruchomić projekt.
Jeśli breakpoint zadziałał, to wszystko jest ok. Jeśli nie, coś musiało pójść nie tak. Upewnij się, że używasz odpowiedniego namespace i nazwy projektu w pliku _ViewImports.cshtml.
Niech się stanie anchor!
OK, mamy taki kod w tag helperze:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public string Address { get; set; }
public string Subject { get; set; }
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
}
}
Teraz trzeba coś zrobić, żeby zadziałała magia.
Popatrz co masz w parametrze metody ProcessAsync. Masz tam jakiś output. Jak już mówiłem wcześniej, tag helper RENDERUJE odpowiedni kod HTML. Za ten rendering jest odpowiedzialny właśnie parametr output. Spróbujmy go wreszcie wykorzystać. Spójrz na kod metody poniżej:
TagHelperOutput ma taką właściwość jak TagName. Ta właściwość mówi dokładnie: „Jaki tag html ma mieć Twój tag helper?”. Uruchom teraz aplikację i podejrzyj wygenerowany kod html:
<a>Test</a>
Twój tag <mail> zmienił się na <a>.
I o to mniej więcej chodzi w tych helperach. Ale teraz dodajmy resztę rzeczy. Musimy jakoś dodać atrybut href. Robi się to bardzo prosto:
Jak widzisz wszystko załatwiliśmy outputem. Myślę, że ta linijka sama się tłumaczy. Po prostu dodajesz atrybut o nazwie href i wartości mailto:.... itd. Uruchom teraz aplikację i popatrz na magię.
Wszystko byłoby ok, gdybyśmy gdzieś przekazali te parametry Address i Subject. Przekażemy je oczywiście w pliku cshtml:
Zwróć tylko uwagę, że wg konwencji klasy w C# nazywamy tzw. PascalCase. Natomiast w tag helperach używasz już tylko małych liter. Tak to zostało zrobione. Jeśli masz kilka wyrazów w nazwie klasy, np. ContentLabelTagHelper, w pliku cshtml te wyrazy oddzielasz myślnikiem: <content-label>. Dotyczy to również atrybutów.
Oczywiście możesz z takim tag helperem zrobić wszystko. Np. zapisać na sztywno mail i temat, np:
Przeanalizuj ten kod. Po prostu, jeśli nie podasz adresu e-mail lub tematu wiadomości, zostaną one wzięte z wartości domyślnych. Oczywiście te wartości domyślne mogą być wszędzie. W stałych – jak tutaj – w bazie danych, w pliku… I teraz wystarczy, że w pliku cshtml napiszesz:
<mail>Test</mail>
Fajnie? Dla mnie bomba!
Atrybuty dla Tag Helper
Tag helpery mogą zawierać pewne atrybuty, które nieco zmieniają ich działanie:
HtmlTargetElement
Możemy tu określić nazwę taga, jaką będziemy używać w cshtml, rodzica dla tego taga, a także jego strukturę, np:
[HtmlTargetElement("email")]
public class MailTagHelper: TagHelper
{
}
Od tej pory w kodzie cshtml nie będziemy się już posługiwać tagiem <mail>, tylko <email>. Możemy też podać nazwę tagu rodzica, ale o tym w drugiej części artykułu. Możemy też określić strukturę tagu. Może on wymagać tagu zamknięcia (domyślnie) lub być bez niego, np:
[HtmlTargetElement("email", TagStructure = TagStructure.NormalOrSelfClosing)]
public class MailTagHelper: TagHelper
{
}
W przypadku tak skonstruowanego tagu email nie ma to sensu, ale moglibyśmy to przeprojektować i wtedy tag można zapisać tak: <email text="Napisz do mnie" /> lub tak: <email text="Napisz do mnie"></email>
TagStructure może mieć takie wartości:
TagStructure.NormalOrSelfClosing – tag z tagiem zamknięcia, bądź samozamykający się – jak widziałeś wyżej. Czyli możesz napisać zarówno tak: <mail address="a@b.c"></mail> jak i tak: <mail address="a@b.c" />
TagStructure.Unspecified – jeśli żaden inny tag helper nie odnosi się do tego elementu, używana jest wartość NormalOrSelfClosing
TagStructure.WithoutEndTag – niekonieczny jest tag zamknięcia. Możesz napisać tak: <mail address="a@b.c"> jak i tak: <mail address="a@b.c" />
HtmlTargetElement ma jeszcze jeden ciekawy parametr służący do ustalenia dodatkowych kryteriów. Spójrz na ten kod:
[HtmlTargetElement("email", Attributes = "send")]
public class MailTagHelper: TagHelper
{
//tutaj bez zmian
}
Aby teraz taki tag helper został dobrze dopasowany, musi być wywołany z atrybutem send:
<email send>Napisz do mnie</email>
Ten kod zadziała i tag zostanie uruchomiony. Ale taki kod już nie zadziała:
<email>Napisz do mnie</email>
Ponieważ ten tag nie ma atrybutu send.
Przy pisaniu własnych tagów raczej nie ma to zbyt wiele sensu, ale popatrz na coś takiego:
<p red>UWAGA! Oni nadchodzą!</p>
I tag helper do tego:
[HtmlTargetElement("p", Attributes = "red")]
public class PRedTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
output.Attributes.Add("style", "color: red");
}
}
Teraz każdy tekst w paragrafie z atrybutem red będzie napisany czerwonym kolorem. To daje nam naprawdę ogromne możliwości.
HtmlAttributeNotBound
Do tej pory widziałeś, że wszystkie właściwości publiczne tag helpera mogą być używane w plikach cshtml. No więc nadchodzi atrybut, który to zmienia. HtmlAttributeNotBound niejako ukrywa publiczną właściwość dla cshtml.
Stosujemy to, gdy jakaś właściwość (atrybut) nie ma sensu od strony HTML lub jest niepożądana, ale z jakiegoś powodu musi być publiczna. Spójrz na ten kod:
public class MailTagHelper: TagHelper
{
[HtmlAttributeNotBound]
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Teraz właściwość Address nie będzie widoczna w cshtml. Oczywiście tego atrybutu używamy na właściwościach, a nie na klasie.
HtmlAttributeName
Ten atrybut z kolei umożliwia zmianę nazwy właściwości tag helpera w cshtml. Nadpisuje nazwę atrybutu:
public class MailTagHelper: TagHelper
{
[HtmlAttributeName("Tralala")]
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Teraz w pliku cshtml możesz napisać tak:
<email tralala="a@b.c" />
Ale ten atrybut ma jeszcze jedno przeciążenie i potrafi ostro zagrać. Może zwali Cię to z nóg. Dzięki niemu możesz w pliku cshtml napisać co Ci się podoba, a Twój tag helper to ogarnie. Możesz popisać atrybuty, które nie są właściwościami Twojego tag helpera! Spójrz na ten przykład:
public class MailTagHelper: TagHelper
{
[HtmlAttributeName(DictionaryAttributePrefix = "mb_")]
public Dictionary<string, string> Prompts { get; set; } = new Dictionary<string, string>();
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Co tu zaszło? Spójrz, co podałeś w parametrze atrybutu HtmlAttributeName. Jest to jakiś prefix. A teraz zauważ, że w kodzie html użyłeś tego prefixu do określenia nowych atrybutów.
Po takiej zabawie, słownik Prompts będzie wyglądał tak:
adr: „a@b.c”
subject: „Temat”
Zauważ, że prefix został w słowniku automatycznie obcięty i trafiły do niego już konkretne atrybuty.
Oczywiście to przeciążenie może być użyte tylko na właściwości, która implementuje IDictionary. Kluczem musi być string, natomiast wartością może być string, int itd.
To tyle, jeśli chodzi o podstawy tworzenia tag helperów. O bardziej zaawansowanych możliwościach mówię w drugiej części artykułu. Najpierw upewnij się, że dobrze zrozumiałeś wszystko co tu zawarte.
Jeśli masz jakiś problem albo znalazłeś w artykule błąd, podziel się w komentarzu.
Pokażę Ci jak zrobić własną walidację na bardzo użytecznym przykładzie. Zrobimy mechanizm sprawdzenia, czy użytkownik wyraził zgodę na regulamin. Jeśli nie wiesz, jak działa walidacja w .NetCore, sprawdź najpierw ten artykuł.
Stworzenie własnej walidacji składa się z dwóch kroków.
utworzenie własnego atrybutu
dodanie sprawdzenia po stronie JavaScript.
Zasadniczo jest to dość proste, ale trzeba pamiętać o pewnej rzeczy… o tym później
Walidacja po stronie klienta
Required nie wystarczy
W .NET można tworzyć własne atrybuty. To wiadomo. Atrybut to po prostu klasa, która dziedziczy po specyficznej klasie i zawiera… konkretne atrybuty 🙂
Z jakiegoś powodu w .NetCore nie ma domyślnie możliwości sprawdzenia, czy checkbox został zaznaczony. Wydawać by się mogło, że wystarczy:
class RegisterUserViewModel
{
[Required]
public bool TermsAndConditions { get; set; }
}
Widziałem też takie przykłady:
class RegisterUserViewModel
{
[Range(typeof(bool), "true", "true")]
public bool TermsAndConditions { get; set; }
}
niestety z checkboxem i jego wartością jest nieco inaczej. I powinien zostać do tego stworzony nowy atrybut. Rozwiązanie, które tutaj podaję zaproponowałem do Microsoftu. Być może w kolejnych wersjach wdrożą coś analogicznego.
Dopisane: W Blazor można walidować checkbox za pomocą atrybutu Required
Tworzenie własnego atrybutu
Zatem stwórzmy własny atrybut walidacyjny. Takie atrybuty powinny dziedziczyć po klasie ValidationAttribute. Jest to klasa abstrakcyjna, która zawiera pewną wspólną logikę dla wszystkich walidacji.
ValidationAttribute zapewnia walidację po stronie serwera. Jeśli chcesz mieć zapewnioną dodatkowo walidację po stronie klienta, musisz zaimplementować interfejs IClientModelValidator.
IClientModelValidator
Tutaj na chwilę się zatrzymamy. Walidacja po stronie klienta zawsze odbywa się za pomocą JavaScript (lub podobnych). .NetCore to znacznie ułatwia, gdyż wprowadza własny prosty mechanizm. Spójrz na ten prosty formularz:
Widzisz tutaj pomocnicze tagi: asp-for i asp-validation-for. W wynikowym HTMLu będzie to wyglądało mniej-więcej tak:
<div class="form-group">
<label for="email">Podaj swój email:</label>
<input class="form-control" type="email" data-val="true" data-val-email="The Email field is not a valid e-mail address." data-val-required="The UserName field is required." id="UserName" name="UserName" value="">
<span class="text-danger field-validation-valid" data-valmsg-for="UserName" data-valmsg-replace="true"></span>
</div>
Jak widzisz, tagi pomocnicze trochę tutaj nagrzebały w kodzie. Nagrzebały pod kątem Microsoftowej biblioteki jQuery Unobtrusive Validation. Ta biblioteka, można powiedzieć, „szuka” atrybutów data-val (skrót od „data validation”), których wartość jest ustawiona na true. Oznacza to, że takie pole podlega walidacji. Następnie tworzone są odpowiednie komunikaty, gdy walidacja się nie powiedzie:
data-val-email – komunikat dla atrybutu [EmailAddress]
data-val-required – komunikat dla atrybutu [Required]
Te komunikaty są później umieszczane w elemencie, który ma data-valmsg-for i data-valmsg-replace (true).
To się dzieje automatycznie – Microsoft porobił takie mechanizmy. Tutaj wchodzi interfejs IClientModelValidator. Zajmijmy się najpierw nim:
Implementacja IClientModelValidator
[AttributeUsage(AttributeTargets.Property | AttributeTargets.Field, AllowMultiple = false)]
public class CheckBoxCheckedAttribute : ValidationAttribute, IClientModelValidator
{
public void AddValidation(ClientModelValidationContext context)
{
if (context == null)
{
throw new ArgumentNullException(nameof(context));
}
MergeAttribute(context.Attributes, "data-val", "true");
MergeAttribute(context.Attributes, "data-val-chboxreq", "Nie zaznaczyłeś checkboxa!");
}
private static void MergeAttribute(IDictionary<string, string> attributes, string key, string value)
{
if (!attributes.ContainsKey(key))
{
attributes.Add(key, value);
}
}
}
context.Attributes to słownik, który zawiera atrybuty dodane już do pola
Użycie atrybutu
Utworzyliśmy klasę CheckBoxCheckedAttribute, implementując interfejs IClientModelValidator. Teraz tak. Tag pomocniczy asp-for sprawdza wszystkie walidacje na danym polu, czyli jeśli mamy model:
class RegisterUserViewModel
{
[CheckBoxChecked]
public bool TermsAndConditions { get; set; }
}
wtedy asp-for weźmie wszystkie klasy atrybutów dla danego pola, które implementują interfejs IClientModelValidator i uruchomi metodę AddValidation.
To, co „zwróci” ta metoda, będzie dopisane do pola . Jak widzisz, zadaniem metody AddValidation jest właściwie tylko odpowiednie dodanie atrybutów do polainput, a więc:
data-val usatwione na true
data-val-chboxreq – którego wartością jest odpowiedni komunikat. Czyli teraz dopiszemy checkboxa w formularzu:
Zauważ, że klasa CheckBoxCheckedAttribute dodała w metodzie AddValidation te dwa atrybuty (data-val i data-val-chboxreq), które są wymagane do poprawnego działania walidacji po stronie klienta.
Oczywiście nie musisz pisać nazywać tego data-val-chboxreq. Ważne, żeby było data-val- i w miarę unikalna, jednoznaczna końcówka. Równie dobrze mógłbyś napisać: data-val-checkbox-zaznaczony i sprawdzać później wartość tego atrybutu.
Czyli podsumowując tę część:
Tag asp-for powoduje wywołanie metody AddValidationz interfejsu IClientModelValidator, która jest odpowiedzialna za dodanie atrybutów walidacyjnych do pola . Oczywiście nic nie stoi na przeszkodzie, żebyś dodał tam jeszcze inne atrybuty. Pamiętaj, że musisz atrybut implementujący IClientModelValidator dodać do odpowiedniego pola w swoim modelu (viewmodelu).
OK, skoro już wiesz do czego służy IClientModelValidator, to teraz polecimy dalej. Pierwsza część walidacji jest zrobiona. Teraz druga. JavaScript.
Walidacja w JavaScript
Jak już mówiłem, Microsoft ma tą swoją bibliotekę jQuery Unobtrusive Validation, która działa razem z jQuery Validation.
Ten fragment kodu możesz dodać albo tylko na stronie z formularzem, albo lepiej – w widoku _ValidationScriptsPartial. Wtedy będzie dostępny zawsze, gdy dodajesz jakąś walidację:
<script>
$.validator.addMethod("chboxreq", function (value, element, param) {
if (element.type != "checkbox")
return false;
return element.checked;
});
$.validator.unobtrusive.adapters.addBool("chboxreq");
</script>
najpierw dodajemy metodę do walidatora jQuery.
metoda ma zostać uruchomiona, gdy trafi na atrybut data-val-chboxreq. Zauważ, że w parametrze podajemy tylko tę ostatnią część – chboxreq.
funkcja przyjmuje 3 parametry – wartość (atrybut value elementu HTML), element – czyli element HTML i param – dodatkowy parametr.
Jak widzisz funkcja walidująca jest bardzo prosta – najpierw jest sprawdzenie, czy element jest checkboxem, potem funkcja sprawdza, czy checkbox jest zaznaczony.
Aby to wszystko zadziałało, trzeba jeszcze dodać ten „adapter”, używając $.validator.unobtrusive.adapters Nie będę tutaj opisywał walidatorów w jQuery, bo:
Mógłbym zaciemnić obraz
Nie znam się na nich
Możesz sam wyszukać w dokumentacjach, jeśli będziesz chciał robić jakieś dziwne rzeczy.
I teraz pewna uwaga, o której pisałem na początku. Ten cały kod nie chciał mi kiedyś zadziałać i męczyłem się chyba 2 godziny zanim wpadłem dlaczego (oczywiście nie byłbym sobą, gdybym nie zgłosił tego do Microsoftu :)). Ten kod nie zadziała z poziomu TypeScript. Nie wiem, czemu. Po prostu MUSI być bezpośrednio w JavaScript.
Walidacja po stronie serwera
Aby wszystko zadziałało poprawnie, musimy dodać jeszcze walidację po stronie serwera. Zauważ, że walidacja kliencka została zrobiona w JavaScript. Walidacja po stronie serwera odbywa się już bezpośrednio w klasie CheckBoxCheckedAttribute. Wystarczy przesłonić metodę IsValid:
public override bool IsValid(object value)
{
return (value is bool && (bool)value);
}
To tyle.
Komunikaty o błędach
Teraz mała uwaga na koniec. Klasa ValidationAttribute zawiera już pewne mechanizmy, które pomagają. Jak już wiesz, każdy atrybut walidacyjny z .NET ma pewne właściwości: ErrorMessage, ErrorMessageResourceName, ErrorMessageResourceType… Bierze się to właśnie z klasy ValidationAttribute. Zatem klasa CheckBoxCheckedAttribute też ma te właściwości. Więc możesz napisać:
class RegisterUserViewModel
{
[CheckBoxChecked(ErrorMessage = "Musisz zaakceptować warunki")]
public bool TermsAndConditions { get; set; }
}
lub (w aplikacji wielojęzycznej):
class RegisterUserViewModel
{
[CheckBoxChecked(ErrorMessageResourceName = nameof(LangRes.ValidationError_AcceptTerms), ErrorMessageResourceType = typeof(LangRes))]
public bool TermsAndConditions { get; set; }
}
Jeśli nie wiesz, jak zrobić lokalizację do swojego programu, sprawdź ten artykuł
wOczywiście musisz pamiętać, żeby w metodzie AddValidation zwrócić poprawny komunikat. I teraz uwaga. Niezależnie od tego, czy posłużysz się ErrorMessage, czy ErrorMessageResourceName i ErrorMessageResourceType, klasa ValidationAttribute przechowa już dla Ciebie konkretny komunikat. Trzyma to we właściwości ErrorMessageString, a więc zamiast komunikatu bezpośrednio w kodzie powinieneś się posłużyć tą właściwością:
public void AddValidation(ClientModelValidationContext context)
{
if (context == null)
{
throw new ArgumentNullException(nameof(context));
}
MergeAttribute(context.Attributes, "data-val", "true");
MergeAttribute(context.Attributes, "data-val-chboxreq", ErrorMessageString);
}
Przejdźmy na kolejny poziom
Jeśli nie do końca rozumiesz ten artykuł albo chcesz czegoś więcej, przy okazji napisałem jak zrobić walidator do sprawdzania rozmiaru przesyłanego pliku. Zachęcam do zapoznania się z tym artykułem o przesyłaniu plików w Razor, Blazor i WebApi.
To tyle. Jeśli masz jakieś wątpliwości lub znalazłeś błąd w artykule, podziel się w komentarzu.
Obsługujemy pliki cookies. Jeśli uważasz, że to jest ok, po prostu kliknij "Akceptuj wszystko". Możesz też wybrać, jakie chcesz ciasteczka, klikając "Ustawienia".
Przeczytaj naszą politykę cookie