Gdy łączymy aplikację frontową (typu SPA) z jakąś formą autoryzacji, np. OAuth, bardzo chętnie trzymamy sobie tokeny autoryzacyjne gdzieś na froncie. Spora ilość odpowiedzi na pytanie „gdzie trzymać tokeny” sugeruje, że to powinien być local storage. A niektóre, że ciastko. Ale odpowiedź jest jedna:
Nigdy nie trzymaj tokenów autoryzacyjnych na froncie.
W tym artykule pokażę jak to zrobić poprawnie – i będziemy mimo wszystko robić tylko backend. Artykuł nie ma nic wspólnego z OAuth, jest bardziej ogólny, ale to co tutaj zrobimy bez problemu nadaje się do zaadaptowania w systemie, w którym dostajemy jakiś token autoryzacyjny.
Przygotowałem też na GitHub prostą implementację tego, co tu robimy. Uwaga! Potraktuj ten kod jako wyznacznik, a nie jako gotową implementację. Ten kod raczej obrazuje jak takie BFF zrobić i należy go dostosować do własnych wymagań. Pobierz go stąd.
NuGet gotowy do użytku
Jeśli chcesz użyć gotowego NuGeta, który zapewnia Ci funkcjonalność BFF, to stworzyłem coś specjalnie na tą okazję. Do pobrania:
To jest jednocześnie mój pierwszy taki OpenSource, więc zachęcam do współpracy 🙂
Dlaczego nie mogę trzymać tokenu na froncie?
Odpowiedź na to pytanie jest szalenie prosta. Nigdy nie wiesz, jaki kod działa na froncie. I to właściwie tyle. Token autoryzacyjny może zostać wykradziony. Wtedy dupa zbita. Konto może zostać przejęte.
I już widzę te słowa oburzenia: „Jak to nie wiem, jaki kod działa na froncie? W końcu sam go pisałem!”.
Jesteś pewien, że jeśli tworzysz front to sam piszesz kod? 🙂
Przy Blazor jest trochę lepiej, ale jeśli piszesz w JavaScript, używasz różnych bibliotek, które też mają swoje zależności, a te zależności mają inne zależności. Niestety mało kto zwraca uwagę na bezpieczeństwo na etapie zależności bibliotek, chociaż npm ma do tego jakieś narzędzia.
I co w związku z tym? Na jakimś etapie możesz niejawnie wykorzystywać bibliotekę, która jest podatna na różne ataki.
Ale ok, załóżmy że masz super restrykcyjną politykę bezpieczeństwa i każda zależność każdej zależności dla każdej biblioteki którą używasz jest sprawdzana i walidowana. I tu wchodzi rola użytkownika 😉
Użytkownik może mieć zainstalowany w przeglądarce złośliwy lub podatny dodatek. No i sorry – na to już żadnego wpływu nie masz.
Czyli – nigdy nie wiesz, jaki kod jest wykonywany na froncie. A jeśli kod Twojej aplikacji ma dostęp do tokenu, to każdy kod, który działa na Twoim froncie też ma do niego dostęp.
No to gdzie mam trzymać tokeny?
Nigdzie. Jeśli tworzysz aplikację typu SPA nigdy nie trzymaj tokenu. Istnieją dwie inne opcje, którymi możesz się posłużyć.
Service Worker
Service Worker to stosunkowo młody byt. To w gruncie rzeczy jakiś fragment funkcjonalności, który pełni rolę reverse proxy. Ale jeśli chciałbyś prawilnie i bezpiecznie używać np. OAuth (albo innego systemu autoryzacji), to musiałbyś całą funkcjonalność z tym związaną przenieść do Service Workera, co jednak nie jest tak prostym i trywialnym zadaniem.
No i teraz dochodzimy do sedna. BFF to zwykła aplikacja backendowa, która w całym systemie pełni rolę prostego reverse proxy. Zasada jest taka, że to BFF otrzymuje tokeny autoryzacyjne. Co więcej, to BFF komunikuje się z WebApi, które gdzieś tam jest pod spodem, a nie aplikacja frontowa. Podsumowując:
BFF to proste reverse proxy
Front komunikuje się TYLKO z BFF
BFF komunikuje się z serwerem autoryzacyjnym i WebApi
BFF przechowuje i/lub szyfruje tokeny
Front NIGDY nie komunikuje się z WebApi bezpośrednio
Jeśli weźmiemy sobie pod uwagę autoryzację OAuth, to uwzględniając BFF będzie to wyglądało tak:
Oczywiście istotne jest, że jeśli używamy OAuth, to musimy w tym momencie przestać używać przestarzałego Implicit flow, a zamiast tego użyć prawilnego Authorization Code flow i nasze BFF wtedy przejmuje rolę klienta, a nie apka frontowa.
Po lewej stronie mamy aplikację SPA, po środku nasze BFF, na górze „fabryka” reprezentuje serwer autoryzacyjny, a na niebiesko po prawej stronie przedstawione jest nasze API, do którego dobijamy się tokenem.
I teraz tak:
Aplikacja SPA strzela do serwera autoryzacyjnego po Authorization Code
Aplikacja SPA przekazuje Authorization Code do BFF i BFF rozpoczyna już prawilną sesję logowania
BFF otrzymuje w końcu od serwera autoryzacyjnego Access Token i opcjonalny Refresh Token
BFF albo to sobie gdzieś zapisuje albo szyfruje i następnie tą informację wysyła do frontu jako HTTP Only, Secure cookie.
Aplikacja z każdym żądaniem do BFF dołącza to cookie
BFF odczytuje sobie dane z cookie i pobiera / odszyfrowuje tokeny
BFF dołącza tokeny do requestu wysyłanego do WebApi
BFF wysyła request do WebApi
Jak niby aplikacja SPA ma dołączyć ciastko, które jest HttpOnly?
No to tak. Ciastko HttpOnly to takie ciastko, którego żaden JavaScript nie będzie w stanie odczytać. To jasne – tu jesteśmy bezpieczni. Nie dość, że jeśli access token jest w ciastku, to jest też tak zaszyfrowany, że tylko BFF potrafi go odszyfrować. No i fajnie, bo Access Tokeny nie są przewidziane do używania na froncie. Czyli jesteśmy podwójnie chronieni nawet jeśli ten token jest zapisany w ciastku.
Ale, ale. Na froncie są metody, żeby dołączyć takie ciastko do wysyłanego żądania. Niezależnie od tego, czy używasz fetcha, axiosa, czy czegoś innego, każda z tych bibliotek ma (albo mieć powinna) taką opcję jak credentials, withCredentials, includeCredentials itp. W zależności od biblioteki. Przy takim ustawieniu HttpOnly cookie zostanie dołączone do requesta.
Jedziemy z implementacją
Implementacja tego cuda jest zasadniczo prosta. Istnieją jakieś biblioteki, które nam w tym pomagają (np. Duende coś ma, no i oczywiście moja darmowa wyżej wspomniana: https://github.com/Nerdolando/Nerdolando.Bff), ale polecam napisać własny fragment kodu, który będzie stosowany tylko w naszej apce. Dzięki temu możesz poznać mechanizm bardzo głęboko. Niemniej jednak będziemy posługiwać się biblioteką Yarp.ReverseProxy. (w moim NuGet nie stosujemy całego Yarpa, tylko jakąś jego część).
A więc w pierwszej kolejności utwórz sobie nowy projekt WebApi, z którego zrobimy BFF i zainstaluj ReverseProxy:
dotnet add package Yarp.ReverseProxy
Jeśli nie posługiwałeś się wcześniej tą biblioteką, możesz sobie poczytać więcej w dokumentacji.
W każdym razie takie ReverseProxy trzeba wstępnie skonfigurować, można to zrobić albo przez appsettings albo w kodzie. Ja Ci pokażę to na przykładzie appsettings, żeby nie zaciemniać obrazu.
Konfiguracja proxy
Zrobimy podstawową konfigurację w pliku appsettings.json. Można oczywiście zrobić konfigurację w odpowiednich klasach w runtime, ale na potrzeby prostego BFF taka konfiguracja jest wystarczająca.
To najprostsza chyba konfiguracja Reverse Proxy. Czyli: „gdy przyjdzie żądanie na Route o danym adresie (Match/Path), prześlij je na Cluster o danym Id (ClusterId)”.
U nas wszystkie żądania jakie przyjdą do BFF na adres /api/* zostaną przesłane dalej na adres odpowiedniego klastra, czyli w tym przypadku – klaster o Id ApiCluster, który ma zdefiniowany adres: https://localhost:7034. W rzeczywistej aplikacji to będzie adres Twojego WebApi.
Teraz trzeba dodać sobie Proxy do naszej apki. Po zainstalowaniu pakietu Yarp.ReverseProxy, nasz plik Program.cs może wyglądać tak:
public class Program
{
public static void Main(string[] args)
{
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddReverseProxy()
.LoadFromConfig(builder.Configuration.GetSection("ProxyConfig"));
var app = builder.Build();
// Configure the HTTP request pipeline.
app.UseHttpsRedirection();
app.MapReverseProxy();
app.Run();
}
}
Dodajemy sobie serwisy odpowiedzialne za działanie Reverse Proxy (linia 7) wraz z konfiguracją (linia 8) i wpinamy proxy do pipeline (linia 16) – bo tak trzeba.
W tym momencie mamy już działające proxy. Ale to jeszcze nie jest BFF, to jest samo właściwie proxy, które nie robi niczego poza przekazywaniem żądania dalej.
Dodajemy CORSy
Kolejny krokiem jest obsługa CORS. Jeśli nie wiesz, czym jest CORS, miałem o tym artykuł: Ten cholerny CORS dogłębnie.
Teraz metoda Main może wyglądać tak:
public static void Main(string[] args)
{
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddReverseProxy()
.LoadFromConfig(builder.Configuration.GetSection("ProxyConfig"));
var corsOrigins = builder.Configuration.GetSection("CorsOrigins").Get<string[]>()!;
var corsExposedHeaders = builder.Configuration.GetSection("CorsExposedHeaders").Get<string[]>()!;
builder.Services.AddCors(o =>
{
o.AddDefaultPolicy(builder =>
{
builder.AllowAnyMethod()
.AllowAnyHeader()
.WithOrigins(corsOrigins)
.AllowCredentials()
.WithExposedHeaders(corsExposedHeaders);
});
});
var app = builder.Build();
// Configure the HTTP request pipeline.
app.UseHttpsRedirection();
app.UseCors();
app.MapReverseProxy();
app.Run();
}
ZAKŁADAJĄC, że w konfiguracji mamy dozwolone originy, z których przychodzą żądania (sekcja CorsOrigins), musimy je dodać do metody WithOrigins (linia 18). Analogicznie z nagłówkami. Jeśli nasze PROXY może emitować niestandardowe nagłówki, musimy je dodać do WithExposedHeaders.
Tutaj cholernie ważna jest metoda AllowCredentials. Bez tego nie otrzymamy z frontu ciastka HttpOnly. A właściwie żądanie z takim ciastkiem zostanie zablokowane przez politykę CORS, więc zakończy się failem. Dlatego AllowCredentials musi tutaj być.
Przypominam – nie wiesz dokładnie co to CORS? To przeczytaj tutaj.
Transformacje – czyli serce BFF
Ok, mamy już reverse proxy, mamy politykę CORS, ale brakuje nam ostatniej rzeczy.
Jakoś tokeny autoryzacyjne musimy zapisać i jakoś je musimy odczytać. Do tego służą transformacje, które są częścią Yarp.ReverseProxy.
Czym jest transformacja? Generalnie możemy w jakiś sposób zmienić request, który do nas przychodzi (np. z frontu) przed przesłaniem go do WebApi, ale też możemy zmienić odpowiedź, która do nas przychodzi np. z WebApi zanim zostanie przekazana na front.
W związku z tym mamy jakby dwa rodzaje transformacji:
RequestTransform
ResponseTransform
Weźmy się najpierw za RequestTransform, czyli transformacja, gdzie działamy na danych pochodzących z frontu.
Request Transform
Najpierw musimy stworzyć sobie klasę dziedziczącą po RequestTransform. Pusta wygląda tak:
internal class AccessTokenRequestTransform : RequestTransform
{
public override async ValueTask ApplyAsync(RequestTransformContext context)
{
}
}
Metoda ApplyAsync zostanie wywołana, gdy przyjdzie do nas żądanie z frontu, zanim zostanie przekazane dalej. W parametrze context mamy wszystko, co potrzebujemy, żeby bawić się żądaniem.
I w gruncie rzeczy to, jak powinna wyglądać ta metoda dokładnie, to już zależy od konkretnego systemu. Ja Ci podam tylko przykład, który wydaje się być w miarę uniwersalny.
UWAGA! W moim przykładzie trzymam zaszyfrowane tokeny w ciastku. Można też to zrobić inaczej. W ciastku trzymać jakieś Id (zaszyfrowane najlepiej), które doprowadzi do tokenu zapisanego w jakiejś bazie danych (chociażby Redis).
Tutaj scenariusz jest taki, że BFF po otrzymaniu tokenów szyfruje je, wrzuca w ciastko i wysyła na front.
Gdy front chce wysłać żądanie do API, przesyła z nim to ciastko (oczywiście HttpOnly, Secure) i BFF je odczytuje, a więc bardzo abstrakcyjnie:
internal class AccessTokenRequestTransform(IAuthCookieService _authCookieService,
IAccessTokenEncoder _tokenEncoder) : RequestTransform
{
public override async ValueTask ApplyAsync(RequestTransformContext context)
{
var cookieValue = _authCookieService.ReadFromRequest(context);
if (string.IsNullOrEmpty(cookieValue))
return;
var tokens = _tokenEncoder.DecodeTokens(cookieValue!);
if (tokens != null)
tokens = await RefreshTokensIfNeeded(context, tokens);
if (tokens != null)
AddAuthHeader(context, tokens.AccessToken);
_authCookieService.RemoveAuthenticationCookie(context);
}
private Task<AuthTokenModel> RefreshTokensIfNeeded(RequestTransformContext context, AuthTokenModel tokens)
{
tokens.ValidTo = tokens.ValidTo.AddMinutes(15); //duży skrót myślowy, tu powinno być prawilne odświeżenie
return Task.FromResult(tokens);
}
private void AddAuthHeader(RequestTransformContext context, string accessToken)
{
context.ProxyRequest.Headers.Add("Authorization", $"Bearer {accessToken}");
}
}
Zadziało się sporo, ale już wszystko tłumaczę.
Na początku wstrzykujemy sobie dwa HIPOTETYCZNE serwisy, których zadaniem jest:
IAuthCookieService – odczyt danych z konkretnego ciasteczka
IAccessTokenEncoder – szyfrowanie i deszyfrowanie tokenów
Podstawowa implementacja tych serwisów jest zrobiona na GitHub. Nie ma tam niczego ciekawego, więc się tym nie zajmujemy.
I teraz metoda ApplyAsync:
Pobieramy wartość z otrzymanego ciasteczka (powinien tam być zaszyfrowany token).
Jeśli wartości nie ma (nie ma ciasteczka) nie robimy transformacji. Request jest po prostu przekazywany dalej bez żadnych zmian.
Jeśli wartość była, to ją odszyfrowujemy. Po odszyfrowaniu powinniśmy otrzymać jakiś obiekt, który przechowuje token i informacje o nim.
Sprawdzamy, czy token należy odświeżyć. W tym przykładowym systemie token powinniśmy odświeżyć jeśli wygaśnie w ciągu 5 minut. Pamiętaj, że to jest tylko przykład. W Twoim systemie wymaganie może być zupełnie inne. Zwróć też uwagę na metodę RefreshTokensIfNeeded – gdzie pokazałem zupełnie niepoprawne odświeżanie tokenów. Jednak przykładowy kod nie ma żadnego miejsca, które tokeny wydaje, więc potraktuj metodę RefreshTokensIfNeeded jako duży skrót myślowy.
Dalej mamy metodę AddAuthHeader, która dodaje AccessToken do nagłówka autoryzacyjnego. Tutaj to też jest tylko przykład. Ale w prawdziwym systemie tokeny będą pewnie dodawane do jakiegoś nagłówka.
No i na koniec USUWAMY ciasteczko z requestu, bo nie chcemy go przesyłać do WebApi.
Response Transform
W znakomitej większości przypadków nie będziesz potrzebował tej transformacji. Tutaj wchodzi żądanie z WebApi i przekazywane jest na front.
Jednak tokeny autoryzacyjne przeważnie będziesz otrzymywał z innego źródła. Jednak jeśli Twoje WebApi wystawia taki token, w takim przypadku powinieneś utworzyć taką transformację. Tutaj też tylko zarys, bo zasada jest dokładnie taka sama jak wyżej:
internal class AccessTokenResponseTransform(IAccessTokenEncoder _tokenEncoder,
IAuthCookieService _authCookieService) : ResponseTransform
{
public override async ValueTask ApplyAsync(ResponseTransformContext context)
{
var tokenModel = await ReadTokenModelFromBody(context) ?? context.HttpContext.GetTokens();
if (tokenModel == null)
return;
var cookieValue = _tokenEncoder.EncodeTokens(tokenModel);
_authCookieService.AddAuthCookieToResponse(context, cookieValue);
}
private async Task<AuthTokenModel?> ReadTokenModelFromBody(ResponseTransformContext context)
{
if (context.ProxyResponse == null)
return null;
if (!context.ProxyResponse.Headers.HasAuthToken())
return null;
var result = await context.ProxyResponse.Content.ReadFromJsonAsync<AuthTokenModel>();
context.SuppressResponseBody = true;
return result;
}
}
Przyjrzyjmy się od razu metodzie ApplyAsync.
Ona w jakiś sposób pobiera sobie token, wygenerowany przez WebApi. Taki token może siedzieć albo w BODY, albo w jakimś nagłówku. Stąd najpierw jest próba pobrania go z BODY, a potem z nagłówka.
To teraz spójrz na metodę ReadTokenModelFromBody. Tu się dzieje jedna istotna rzecz.
Odczytujemy dane z BODY. To jest ważne – ODCZYTUJEMY DANE Z BODY. Po takim odczycie koniecznie trzeba przypisać TRUE do SupressResponseBody w kontekście. Jeśli to jest ustawione na TRUE, proxy podczas przesyłania requestu dalej, nie bierze pod uwagę zawartości BODY.
Niestety odczytujemy tutaj całe body, czyli niejako pobieramy je z oryginalnego żądania. Kradniemy je z niego. W oryginalnym żądaniu nie ma już tego body po naszym odczycie, jednak cały czas jest ustawiony nagłówek Content-Length, który mówi o tym, jak długie jest Body. W efekcie wszystko wybuchnie 🙂
To jest pewna pułapka biblioteki Yarp.ReverseProxy. Jeśli musisz odczytać body, żeby przykładowo pobrać jakąś wartość, ale chcesz żeby body było później przesłane dalej, to musisz je na nowo zapisać.
W przypadku tego kodu nie ma takiej potrzeby. Odczytujemy Body i jesteśmy z tym ok, że dalej nie pójdzie. Bo w MOIM systemie ja wiem, że jeśli metoda z linii 26: context.ProxyResponse.Headers.HasAuthToken() zwróci mi TRUE, to znaczy, że w body mam TYLKO tokeny autoryzacyjne.
Oczywiście to jest domena TYLKO I WYŁĄCZNIE mojej aplikacji i moich założeń. A czym jest metoda HasAuthToken? To jakieś rozszerzenie, które może sprawdzać, czy istnieje jakiś nagłówek w żądaniu. Czyli coś w stylu: „Jeśli w żądaniu występuje nagłówek MOJA-APKA-MAM-TOKEN, to znaczy, że w body znajduje się token autoryzacyjny. Chcę, żeby to dobrze wybrzmiało.
To teraz wróćmy do głównej metody – ApplyAsync:
public override async ValueTask ApplyAsync(ResponseTransformContext context)
{
var tokenModel = await ReadTokenModelFromBody(context) ?? context.HttpContext.GetTokens();
if (tokenModel == null)
return;
var cookieValue = _tokenEncoder.EncodeTokens(tokenModel);
_authCookieService.AddAuthCookieToResponse(context, cookieValue);
}
Co tu się konkretnie dzieje?
Pobieramy sobie token z body lub jakiegoś nagłówka.
Jeśli istnieje, to szyfrujemy go.
Tworzymy ciasteczko z tym zaszyfrowanym tokenem i dodajemy je do żądania, które jest dalej przesyłane na front.
I to w zasadzie tyle.
Rejestracja transformacji
Rejestracja transformacji nie jest taka oczywista w Yarp.ReverseProxy. Można to zrobić na kilka sposobów. Ale jeśli używamy dependency injection w naszych transformacjach, powinniśmy stworzyć sobie jeszcze jedną klasę: TransformProvider:
internal class TransformProvider : ITransformProvider
{
public void Apply(TransformBuilderContext context)
{
var requestTransform = context.Services.GetRequiredService<AccessTokenRequestTransform>();
var responseTransform = context.Services.GetRequiredService<AccessTokenResponseTransform>();
context.RequestTransforms.Add(requestTransform);
context.ResponseTransforms.Add(responseTransform);
}
public void ValidateCluster(TransformClusterValidationContext context)
{
}
public void ValidateRoute(TransformRouteValidationContext context)
{
}
}
Wystarczy zaimplementować interfejs ITransformProvider i wypełnić metodę Apply. Potem tworzymy nasze transformacje (w tym przypadku pobieramy z dependency injection) i dodajemy je do odpowiednich kolekcji. Bo transformacji możemy mieć wiele – zarówno dla requestu jak i dla responsu.
W przykładowej solucji na GitHub są dwa projekty, które muszą zostać uruchomione razem – BFF i WebApi. W projekcie BFF w pliku BFF.http jest napisane podstawowe żądanie, które możesz uruchomić, żeby zobaczyć sobie jak to wszystko działa.
Zachęcam Cię do pobrania sobie tego „szkieletu” i pobawienie się trochę nim.
Jeśli pracujesz (albo jesteś częścią teamu) nad aplikacją SPA i jest tam jakaś forma autoryzacji z tokenami, to BFF jest poprawną drogą. Jest to również oficjalne zalecenie w OAuth, żeby używać BFF przy aplikacji typu SPA.
Dzięki za przeczytanie tego artykułu. Jeśli czegoś nie zrozumiałeś lub zauważyłeś gdzieś błąd, koniecznie daj znać w komentarzu 🙂
Jeśli masz dodatkowe pytania – też napisz. Z chęcią odpowiem.
Pewnie nie raz spotkałeś się z sytuacją, gdzie próba wywołania API z Blazor albo JavaScript zakończyła się radosnym błędem
XMLHttpRequest cannot load http://…. No ‘Access-Control-Allow-Origin’ header is present on the requested resource. Origin ‘http://…’ is therefore not allowed access.
Czym jest CORS, dlaczego jest potrzebne i jak się z nim zaprzyjaźnić? O tym dzisiaj.
Co to CORS
Cross Origin Request Sharing to mechanizm bezpieczeństwa wspierający politykę same-origin. Same-origin polega na tym, że JavaScript z jednej domeny (a konkretnie origin) nie może komunikować się z serwerem z innej domeny (origin).
Innymi słowy, jeśli masz stronę pod adresem: https://example.com i chciałbyś z niej wywołać za pomocą JavaScript coś ze strony https://mysite.com, to musisz mieć na to specjalne pozwolenie wydane przez mysite.com.
Czyli jeśli u siebie lokalnie z końcówki https://localhost:3000 będziesz chciał zawołać jakieś API z końcówki: https://localhost:5001, to też się to nie uda bez specjalnego pozwolenia. Tym wszystkim zarządza przeglądarka.
Czym jest ORIGIN
Już wiemy, że żeby nie było problemów, obydwie strony żądania muszą należeć do tego samego originu. Czym jest zatem origin?
To połączenie: protocol + host + port, czyli np:
https://example.com i https://example.com:443 – należą do tego samego originu. Pomimo, że w pierwszym przypadku nie podaliśmy jawnie portu, to jednak protokół https domyślnie działa na porcie 443. A więc został tam dodany niejawnie.
http://example.com i https://example.com – nie należą już do tego samego originu. Różnią się protokołem i portem (przypominam, że https działa domyślnie na porcie 443, a http na 80).
https://example.com:5000 i https://example.com:5001 – też nie należą do tego samego originiu, ponieważ różnią się portem.
https://api.example.com i https://example.com – też nie należą do tego samego originu, bo różnią się hostem. Zasadniczo origin definiuje aplikację internetową.
Polityka same-origin
Jak już pisałem wcześniej, polityka same-origin zakazuje jednej aplikacji korzystać z elementów innej aplikacji. Skryptów js, arkuszy css i innych… Ale…
No, ale jak to? A CDN? A linkowanie bootstrapa itd?
No właśnie. Przede wszystkim przeglądarki nie są zbyt rygorystyczne pod tym względem. Głównie ze względu na kompatybilność wsteczną. Pół Internetu przestałoby działać. Jednak to „rozluźnienie” niesie za sobą pewne zagrożenia. Np. może dawać podatność na atak XSS lub CSRF (pisałem o Cross Site Request Forgery w książce o podstawach zabezpieczania aplikacji internetowych).
Wyjątki polityki same-origin
Skoro przeglądarki niezbyt rygorystycznie podchodzą do polityki same-origin, to znaczy że są pewne luźniejsze jej elementy. Oczywiście, że tak. Przeglądarki pozwalają ogólnie na:
zamieszczanie obrazków z innych originów
wysyłanie formularzy do innych originów
zamieszczanie skryptów z innych originów – choć tutaj są już pewne ograniczenia
Na co same-origin nie pozwoli
Przede wszystkim nie pozwoli Ci na dostęp do innych originów w nowych technologiach takich jak chociażby AJAX. Czyli strzały HTTP za pomocą JavaScriptu. Co to oznacza? Zacznijmy od najmniejszego problemu – jeśli piszesz aplikację typu SPA w JavaScript lub Blazor, to chcesz się odwoływać do jakiegoś API. W momencie tworzenia aplikacji prawdopodobnie serwer stoi na innym originie niż front. Na produkcji może być podobnie. W takiej sytuacji bez obsługi CORS po stronie serwera, nie połączysz się z API.
Idąc dalej, jeśli chcesz na swojej stronie udostępnić dane pobierane z innego źródła – np. pobierasz AJAXem kursy walut – to też może nie zadziałać. W prawdzie użyłem tych kursów walut jako być może nieszczęśliwy przykład. Jeśli to działa to tylko ze względu na luźną politykę CORS. W przeciwnym razie musiałbyś się kontaktować z dostawcą danych, żeby pozwolił Ci na ich pobieranie. I tak też często się dzieje. I on może to zrobić właśnie dzięki CORS.
Więc jak działa ten CORS?
Pobierz sobie przykładową solucję, którą przygotowałem na GitHub. Jest kam kilka projektów:
WebApiWithoutCors – api, które w żaden sposób nie reaguje na CORS – domyślnie uniemożliwi wszystko
WebApiWithCors – api z obsługą CORS
ClientApiConfig – podstawowy klient, który chciałby pobrać dane i zrobić POST
DeletableClient – klient, któremu polityka CORS pozwala jedynie na zrobienie DELETE
BadClient – klient, któremu żadne API na nic nie pozwala
Każdy projekt pracuje w HTTP (nie ma SSL/TLS) specjalnie, żeby umożliwić w łatwy sposób podsłuchiwanie pakietów w snifferze.
Przede wszystkim działanie CORS (Cross Origin Request Sharing) jest domeną przeglądarki. Jeśli uruchomisz teraz przykładowe projekty: ClientApp (aplikacja SPA pisana w Blazor) i WebApiWithoutCors i wciśniesz guzik Pobierz dane, to zobaczysz taki komunikat:
A teraz wywołaj tę samą końcówkę z PostMan, to zobaczysz że dane zostały pobrane:
Co więcej, jeśli posłużysz się snifferem, np. WireShark, zobaczysz że te dane do przeglądarki przyszły:
To znaczy, że to ta małpa przeglądarka Ci ich nie dała. Co więcej, wywaliła się wyjątkiem HttpRequestException przy pobieraniu danych:
var client = HttpClientFactory.CreateClient("api");
try
{
var response = await client.GetAsync("weatherforecast");
if (!response.IsSuccessStatusCode)
ErrorMsg = $"Nie można było pobrać danych, błąd: {response.StatusCode}";
else
{
var data = await response.Content.ReadAsStringAsync();
WeatherData = new(JsonSerializer.Deserialize<WeatherForecast[]>(data));
}
}catch(HttpRequestException ex)
{
ErrorMsg = $"Nie można było pobrać danych, błąd: {ex.Message}";
}
Co z tą przeglądarką nie tak?
Przeglądarka odebrała odpowiedź z serwera, ale Ci jej nie pokazała. Dlaczego? Ponieważ nie dostała z serwera odpowiedniej informacji. A konkretnie nagłówka Access-Control-Allow-Origin, o czym informuje w konsoli:
XMLHttpRequest cannot load http://.... No ‘Access-Control-Allow-Origin’ header is present on the requested resource. Origin ‘http://...’ is therefore not allowed access.
To poniekąd serwer zdecydował, że nie chce klientowi danych pokazywać. A dokładniej – serwer nie zrobił niczego, żeby te dane pokazać. Po prostu na dzień dobry obsługa CORS na serwerze jest wyłączona. Można powiedzieć, że jest zaimplementowana jedynie w przeglądarce.
Niemniej jednak przeglądarka wysłała do serwera zapytanie GET, które odpowiednie dane pobrało i zwróciło. Czyli jakaś operacja na serwerze się wykonała. Pamiętaj, że zapytanie GET nie powinno mieć żadnych skutków ubocznych. Czyli nie powinno zmieniać żadnych danych. Powinno dane jedynie pobierać. A więc teoretycznie nic złego nie może się stać.
A gdyby tak przeglądarka wysłała POST? Zadziała czy nie? No właśnie nie w każdej sytuacji.
Jeśli teraz w przykładowej aplikacji uruchomisz narzędzia dewelopera (Shift + Ctrl + i) i wciśniesz guzik Wywołaj POST, to zobaczysz coś takiego:
Zanim przeglądarka wyśle to żądanie, najpierw wykona specjalne zapytanie, tzw. preflight. Czyli niejako zapyta się serwera: „Hej serwer, jestem z takiego originu i chciałbym wysłać do Ciebie POST z takimi nagłówkami. Mogę?”
To specjalne żądanie wysyłane jest na adres, na który chcesz rzucić POSTem. Z tym że tutaj metodą jest OPTIONS. Poza tym w nagłówkach są zaszyte informacje:
Access-Control-Request-Headers – lista nagłówków z jakimi chcesz wysłać POST
Access-Control-Request-Method – metoda, jaką chcesz wywołać (POST, DELETE itd)
Origin – origin, z którego żądanie będzie wysłane
Możesz to podejrzeć zarówno w narzędziach dewelopera jak i w Wireshark:
A co zrobił serwer? Zwrócił błąd: 405 - Method not allowed. Co znaczy, że pod takim endpointem serwer nie obsługuje zapytań typu OPTIONS. Co dla przeglądarki daje jasny komunikat: „Nie wysyłaj mi tego, nie obsługuję CORS”. Przeglądarka więc zaniecha i nie wyśle takiego zapytania.
Wyjątkowe formularze
Jak już pisałem wcześniej, formularze są pewnym wyjątkiem. Przeglądarka i tak je wyśle. To kwestia kompatybilności wstecznej. Jeśli będziesz chciał wysłać metodę POST z Content-Type ustawionym na multipart/form-data, to takie zapytanie zostanie wykonane bez żadnego preflight'u. Takich wyjątków jest więcej i są bardzo dobrze opisane na stronie Sekuraka, więc nie będę tego powielał. Jeśli masz ochotę zgłębić temat, to polecam.
Obsługa CORS w .NET
Skoro już wiesz z grubsza czym jest CORS i, że to serwer ostatecznie musi dać jawnie znać, że zgadza się na konkretne zapytanie, to teraz zaimplementujmy ten mechanizm po jego stronie. Spójrz na projekt WebApiWithCors z załączonej solucji.
Jeśli pracujesz na .NET < 6, to pewnie będziesz musiał dorzucić Nugeta: Microsoft.AspNetCore.Cors.
Przede wszystkim musisz dodać serwisy obsługujące CORS podczas rejestracji serwisów:
builder.Services.AddCors();
a także wpiąć obsługę CORS w middleware pipeline. Jeśli nie wiesz, czym jest middleware pipeline, przeczytaj ten artykuł.
Pamiętaj, że UseCors musi zostać wpięte po UseRouting, ale przed UseAuthorization.
Takie dodanie jednak niczego nie załatwi. CORS do odpowiedniego funkcjonowania potrzebuje polityki. I musimy mu tę politykę ustawić.
Polityka CORS
CORS Policy mówi jakich dokładnie klientów i żądania możesz obsłużyć. Składa się z trzech części:
origin – obsługuj klientów z tych originów
method – obsługuj takie metody (POST, GET, DELETE itd…)
header – obsługuj takie nagłówki
To znaczy, że klient aby się dobić do serwera musi spełnić wszystkie trzy warunki – pochodzić ze wskazanego originu, wywołać wskazaną metodę i posiadać wskazany nagłówek.
Wyjątkiem jest tu POST. Co wynika z wyjątkowości formularzy. Jeśli będziesz chciał wysłać POST, przeglądarka zapyta się o to jedynie w przypadku, gdy Content-Type jest odpowiedni (np. nie wskazuje na formularz). Co to dalej oznacza? Jeśli stworzysz na serwerze politykę, która nie dopuszcza POST, ale dopuszcza wszystkie nagłówki (AllowAnyHeader), to ten POST i tak zostanie wysłany. Kwestia kompatybilności wstecznej.
Ona zezwala na połączenia z dowolnego originu, wykonanie dowolnej metody z dowolnymi nagłówkami. Czy to dobrze? To zależy od projektu.
Co więcej, metoda AddDefaultPolicy doda domyślną politykę. Wpięty w pipeline UseCors będzie używał tej domyślnej polityki do sprawdzenia, czy żądanie od klienta może pójść dalej.
Za pomocą metody AddPolicy możesz dodać politykę z jakąś nazwą. Tylko wtedy do UseCors musisz przekazać w parametrze nazwę polityki, której chcesz używać domyślnie. UseCors wywołany bez parametrów będzie używał polityki dodanej przez AddDefaultPolicy. Jeśli jej nie dodasz, wtedy CORS nie będzie obsługiwany.
Konkretna polityka
Oczywiście możesz w polityce wskazać konkretne wartości, np.:
To spowoduje, że polityka dopuści strzały tylko z originu http://localhost:5001 z jakąkolwiek metodą i dozwolonym nagłówkiem X-API-KEY.
I tutaj dwie uwagi. Po pierwsze – pamiętaj, żeby originu nie kończyć slashem: / . Jeśli tak wpiszesz http://localhost:5001/, wtedy origin się nie zgodzi i mechanizm CORS nie dopuści połączeń. Czyli – brak slasha na końcu originu. Idąc dalej, nie podawaj pełnych adresów w stylu: https://localhost:5001/myapp – to nie jest origin.
A teraz pytanie za milion punktów. Co się stanie, gdy mając taką politykę z poprawnego originu wywołasz:
var data = new WeatherForecast
{
Date = DateTime.Now,
Summary = "Cold",
TemperatureC = 5
};
var client = HttpClientFactory.CreateClient("api");
client.DefaultRequestHeaders.Add("X-API-KEY", "abc");
var response = await client.PostAsJsonAsync("weatherforecast", data);
Dodałeś nagłówek X-API-KEY do żądania i wysyłasz JSONa za pomocą post (dowolna metoda).
Zadziała?
Przemyśl to.
Jeśli powiedziałeś „nie”, to zgadza się. Gratulacje 🙂 A teraz pytanie dlaczego to nie zadziała. Spójrz jaki przeglądarka wysyła preflight:
O co pyta przeglądarka w tym żądaniu?
„Hej serwer, czy mogę ci wysłać POST z nagłówkami contenty-type i x-api-key? A co odpowiada serwer?
„Ja się mogę zgodzić co najwyżej na metodę POST i nagłówek X-API-KEY„.
Przeglądarka teraz patrzy na swoje żądanie i mówi: „Ojoj, to nie mogę ci wysłać content-type. Więc nie wysyłam”. To teraz pytanie skąd się wzięło to content type? Spójrz jeszcze raz na kod:
var response = await client.PostAsJsonAsync("weatherforecast", data);
Wysyłasz JSONa. A to znaczy, że gdzieś w metodzie PostAsJsonAsync został dodany nagłówek: Content-Type=application/json. Ponieważ w zawartości żądania (content) masz json (czyli typ application/json).
Uważaj na takie rzeczy, bo mogą doprowadzić do problemów, z którymi będziesz walczył przez kilka godzin. Ale w tym wypadku już powinieneś wiedzieć, jak zaktualizować politykę CORS:
Jeśli wydaje Ci się, że CORS powinien zadziałać, a nie działa, w pierwszej kolejności zawsze zobacz jaki preflight jest wysyłany, jakie nagłówki idą w żądaniu i czy są zgodne z polityką.
Pamiętaj też, że w żądaniu nie muszą znaleźć się wszystkie nagłówki. Jeśli nie będzie w tej sytuacji X-API-KEY nic złego się nie stanie. Analogicznie jak przy polityce dotyczącej metod. Możesz wysłać albo GET, albo POST, albo DELETE… Nie możesz wysłać kilku metod jednocześnie, prawda? 🙂
CORS tylko dla jednego endpointu
Corsy możesz włączyć tylko dla konkretnych endpointów. Możesz to zrobić za pomocą atrybutów. I to na dwa sposoby. Jeśli chcesz umożliwić większość operacji, możesz niektóre endpointy wyłączyć spod opieki CORS. Spójrz na kod kontrolera:
[HttpGet]
public IEnumerable<WeatherForecast> Get()
{
return Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = DateTime.Now.AddDays(index),
TemperatureC = Random.Shared.Next(-20, 55),
Summary = Summaries[Random.Shared.Next(Summaries.Length)]
})
.ToArray();
}
[HttpPost]
[DisableCors]
public IActionResult PostTest([FromBody]WeatherForecast data)
{
return Ok();
}
Atrybut DisableCors spowoduje, że mechanizm CORSów uniemożliwi wywołanie tej końcówki. Jeśli przeglądarka użyje preflight, wtedy serwer odpowie, ale nie pozwalając na nic.
Kilka polityk CORS
Skoro można zablokować CORS na pewnych końcówkach, to pewnie można też odblokować na innych. No i tak. Zgadza się. Zróbmy sobie takie dwie polityki:
Zwróć uwagę na to, że nie dodajemy teraz żadnej domyślnej polityki (AddDefaultPolicy), tylko dwie, które jakoś nazwaliśmy. Teraz każdy endpoint może mieć swoją własną politykę:
[HttpGet]
[EnableCors("get-policy")]
public IEnumerable<WeatherForecast> Get()
{
return Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = DateTime.Now.AddDays(index),
TemperatureC = Random.Shared.Next(-20, 55),
Summary = Summaries[Random.Shared.Next(Summaries.Length)]
})
.ToArray();
}
[HttpPost]
[EnableCors("set-policy")]
public IActionResult PostTest([FromBody]WeatherForecast data)
{
return Ok();
}
Każdy endpoint dostał swoją własną politykę za pomocą atrybutu EnableCors. Jako parametr przekazujemy nazwę polityki. Jeśli w takim przypadku nie podasz atrybutu EnableCors, to końcówka będzie zablokowana. Dlaczego? Spójrz na middleware:
app.UseCors();
Taki middleware po prostu będzie chciał użyć domyślnej polityki (AddDefaultPolicy), której jednak nie ma. Dlatego też zablokuje wszystko. Oczywiście możesz w tym momencie podać konkretną politykę, jaka ma być używana przez middleware:
app.UseCors("get-policy");
Wtedy każdy endpoint bez atrybutu [EnableCors] będzie używał tej polityki.
Dynamiczna polityka CORS
Czasem możesz potrzebować bardziej płynnej polityki, która może zależeć od konkretnego originu. Możesz chcieć wpuszczać tylko te originy, które są zarejestrowane w bazie albo dla różnych originów mieć różne polityki.
Wtedy sam musisz zadbać o to, żeby mechanizm CORS dostał odpowiednią politykę. Na szczęście w .NET6 jest to banalnie proste. Wystarczy zaimplementować interfejs ICorsPolicyProvider, np. w taki sposób:
public class OriginCorsPolicyProvider : ICorsPolicyProvider
{
private readonly CorsOptions _corsOptions;
public OriginCorsPolicyProvider(IOptions<CorsOptions> corsOptions)
{
_corsOptions = corsOptions.Value;
}
public Task<CorsPolicy?> GetPolicyAsync(HttpContext context, string? policyName)
{
var origin = context.Request.Headers.Origin;
var policy = _corsOptions.GetPolicy(origin);
if (policy == null)
policy = _corsOptions.GetPolicy(policyName ?? _corsOptions.DefaultPolicyName);
return Task.FromResult(policy);
}
}
Interfejs wymaga tylko jednej metody – GetPolicyAsync. Najpierw jednak zobacz w jaki sposób zarejestrowałem odpowiednie polityki podczas rejestracji serwisów CORS:
Nazwa polityki to po prostu origin, dla którego ta polityka jest utworzona. A teraz wróćmy do providera. Spójrz najpierw na metodę GetPolicyAsync.
Najpierw pobieram origin z requestu, następnie pobieram odpowiednią politykę. Metoda GetPolicy z obiektu _corsOptions zwraca politykę po nazwie. Te polityki są tam dodawane przez setup.AddPolicy. Gdzieś tam pod spodem są tworzone jako dodatkowe opcje, co widzisz w konstruktorze – w taki sposób możesz pobrać zarejestrowane polityki.
Oczywiście nic nie stoi na przeszkodzie, żebyś w swoim providerze połączył się z bazą danych i na podstawie jakiś wpisów sam utworzył odpowiednią politykę dynamicznie i ją zwrócił.
Teraz jeszcze tylko musimy zarejestrować tego providera:
Słowem zakończenia, pamiętaj żeby nie podawać w middleware kilka razy UseCors, bo to nie ma sensu. Pierwszy UseCors albo przepuści żądanie dalej w middleware albo je sterminuje.
To tyle jeśli chodzi o CORSy. Dzięki za przeczytanie artykułu. Mam nadzieję, że teraz będziesz się poruszał po tym świecie z większą pewnością. Jeśli znalazłeś błąd w artykule albo czegoś nie rozumiesz, koniecznie daj znać w komentarzu.
Osoby niezdające sobie sprawy, jak pod kapeluszem działa HttpClient, często używają go źle. Ja sam, zaczynając używać go kilka lat temu, robiłem to źle – traktowałem go jako typową klasę IDisposable. Skoro utworzyłem, to muszę usunąć. W końcu ma metodę Dispose, a więc trzeba jej użyć. Jednak HttpClient jest nieco wyjątkowy pod tym względem i należy do niego podjeść troszkę inaczej.
Raz a dobrze!
HttpClient powinieneś stworzyć tylko raz na cały system. No, jeśli strzelasz do różnych serwerów, możesz utworzyć kilka klientów – po jednym na serwer. Oczywiście przy założeniu, że nie komunikujesz się z kilkuset różnymi serwerami, bo to zupełnie inna sprawa 😉
Przeglądając tutoriale, zbyt często widać taki kod:
using var client = new HttpClient();
To jest ZŁY sposób utworzenia HttpClient, a autorzy takich tutoriali nigdy (albo bardzo rzadko) o tym nie wspominają albo po prostu sami nie wiedzą.
Dlaczego nie mogę ciągle tworzyć i usuwać?
To jest akapit głównie dla ciekawskich.
Każdy request powoduje otwarcie nowego socketu. Spójrz na ten kod:
for(int i = 0; i < 10; i++)
{
using var httpClient = new HttpClient();
//puszczenie requestu
}
On utworzy 10 obiektów HttpClient, każdy z tych obiektów otworzy własny socket. Jednak, gdy zwolnimy obiekt HttpClient, socket nie zostanie od razu zamknięty. On będzie sobie czekał na jakieś zagubione pakiety (czas oczekiwania na zamknięcie socketu ustawia się w systemie). W końcu zostanie zwolniony, ale w efekcie możesz uzyskać coś, co nazywa się socket exhaustion (wyczerpanie socketów). Ilość socketów w systemie jest ograniczona i jeśli wciąż otwierasz nowe, to w końcu – jak to mawiał klasyk – nie będzie niczego.
Z drugiej strony, jeśli masz tylko jeden HttpClient (singleton), to tutaj pojawia się inny problem. Odświeżania DNSów. Raz utworzony HttpClient po prostu nie będzie widział odświeżenia DNSów.
Te problemy właściwie nie istnieją jeśli masz aplikację desktopową, którą użytkownik włącza na chwilę. Wtedy hulaj dusza, piekła nie ma. Ale nikt nie zagwarantuje Ci takiego używania Twojej apki. Poza tym, coraz więcej rzeczy przenosi się do Internetu. Wyobraź sobie teraz kontroler, który tworzy HttpClient przy żądaniu i pobiera jakieś dane z innego API. Tutaj katastrofa jest murowana.
Poprawne tworzenie HttpClient
Zarówno użytkownicy jak i Microsoft zorientowali się w pewnym momencie, że ten HttpClient nie jest idealny. Od jakiegoś czasu mamy dostęp do HttpClientFactory. Jak nazwa wskazuje jest to fabryka dla HttpClienta. I to przez nią powinniśmy sobie tego klienta tworzyć.
Ta fabryka naprawia oba opisane problemy. Robi to przez odpowiednie zarządzanie cyklem życia HttpMessageHandler, który to bezpośrednio jest odpowiedzialny za całe zamieszanie i jest składnikiem HttpClient.
Jest kilka możliwości utworzenia HttpClient za pomocą fabryki i wszystkie działają z Dependency Injection. Teraz je sobie omówimy. Zakładam, że wiesz czym jest dependency injection i jak z niego korzystać w .Net.
Podstawowe użycie
Podczas rejestracji serwisów, zarejestruj HttpClient w taki sposób:
services.AddHttpClient();
Następnie, w swoim serwisie, możesz pobrać HttpClient w taki sposób:
class MyService
{
IHttpClientFactory factory;
public MyService(IHttpClientFactory factory)
{
this.factory = factory;
}
public void Foo()
{
var httpClient = factory.CreateClient();
}
}
Przy wywołaniu CreateClient powstanie wprawdzie nowy HttpClient, ale może korzystać z istniejącego HttpMessageHandler’a, który odpowiada za wszystkie problemy. Fabryka jest na tyle mądra, że wie czy powinna stworzyć nowego handlera, czy posłużyć się już istniejącym.
Takie użycie świetnie nadaje się do refaktoru starego kodu, gdzie tworzenie HttpClient’a zastępujemy eleganckim CreateClient z fabryki.
Klient nazwany (named client)
Taki sposób tworzenia klienta wydaje się być dobrym pomysłem w momencie, gdy używasz różnych HttpClientów na różnych serwerach z różną konfiguracją. Możesz wtedy rozróżnić poszczególne „klasy” HttpClient po nazwie. Rejestracja może wyglądać tak:
services.AddHttpClient("GitHub", httpClient =>
{
httpClient.BaseAddress = new Uri("https://api.github.com/");
// The GitHub API requires two headers.
httpClient.DefaultRequestHeaders.Add(
HeaderNames.Accept, "application/vnd.github.v3+json");
httpClient.DefaultRequestHeaders.Add(
HeaderNames.UserAgent, "HttpRequestsSample");
});
services.AddHttpClient("MyWebApi", httpClient =>
{
httpClient.BaseAddress = new Uri("https://example.com/api");
httpClient.RequestHeaders.Add("x-login-data", config["ApiKey"]);
});
Zarejestrowaliśmy tutaj dwóch klientów. Jeden, który będzie używany do połączenia z GitHubem i drugi do jakiegoś własnego API, które wymaga klucza do logowania.
A jak to pobrać?
class MyService
{
IHttpClientFactory factory;
public MyService(IHttpClientFactory factory)
{
this.factory = factory;
}
public void Foo()
{
var gitHubClient = factory.CreateClient("GitHub");
}
}
Analogicznie jak przy podstawowym użyciu. W metodzie CreateClient podajesz tylko nazwę klienta, którego chcesz utworzyć. Z każdym wywołaniem CreateClient idzie też kod z Twoją konfiguracją.
Klient typowany (typed client)
Jeśli Twoja aplikacja jest zorientowana serwisowo, możesz wstrzyknąć klienta bezpośrednio do serwisu. Skonfigurować go możesz zarówno w serwisie jak i podczas rejestracji.
Kod powie więcej. Rejestracja:
services.AddHttpClient<MyService>(client =>
{
client.BaseAddress = new Uri("https://api.services.com");
});
Taki klient zostanie wstrzyknięty do Twojego serwisu:
class MyService
{
private readonly HttpClient _client;
public MyService(HttpClient client)
{
_client = client;
}
}
Tutaj możesz dodatkowo klienta skonfigurować. HttpClient używany w taki sposób jest rejestrowany jako Transient.
Zabij tego HttpMessageHandler’a!
Jak już pisałem wcześniej, to właśnie HttpMessageHandler jest odpowiedzialny za całe zamieszanie. I to fabryka decyduje o tym, kiedy utworzyć nowego handlera, a kiedy wykorzystać istniejącego.
Jednak domyślna długość życia handlera jest określona na dwie minuty. Po tym czasie handler jest usuwany.
Jeśli pobierasz dane lub pliki większe niż 50 MB powinieneś sam je buforować zamiast korzystać z domyślnych mechanizmów. One mogę mocno obniżyć wydajność Twojej aplikacji. I wydawać by się mogło, że poniższy kod jest super:
Niestety nie jest. Przede wszystkim zajmuje taką ilość RAMu, jak wielki jest plik. RAM jest zajmowany na cały czas pobierania. Ponadto przy pliku testowym (około 1,7 GB) nie działa. Task, w którym wykonywał się ten kod w pewnym momencie po prostu rzucił wyjątek TaskCancelledException.
Co więcej w żaden sposób nie możesz wznowić takiego pobierania, czy też pokazać progressu. Jak więc pobierać duże pliki HttpClientem? W taki sposób (to nie jest jedyna słuszna koncepcja, ale powinieneś iść w tę stronę):
httpClient.DefaultRequestHeaders.UserAgent.Add(new ProductInfoHeaderValue("Test", "1.0"));
var httpRequestMessage = new HttpRequestMessage
{
Method = HttpMethod.Get,
RequestUri = uri
};
using var httpResponseMessage = await httpClient.SendAsync(httpRequestMessage, HttpCompletionOption.ResponseHeadersRead);
if (!httpResponseMessage.IsSuccessStatusCode)
return;
var fileSize = httpResponseMessage.Content.Headers.ContentLength;
using Stream sourceStream = await httpResponseMessage.Content.ReadAsStreamAsync();
using Stream destStream = File.Open("D:\\test.avi", FileMode.Create);
var buffer = new byte[8192];
ulong bytesRead = 0;
int bytesInBuffer = 0;
while((bytesInBuffer = await sourceStream.ReadAsync(buffer, 0, buffer.Length)) != 0)
{
bytesRead += (ulong)bytesInBuffer;
Downloaded = bytesRead;
await destStream.WriteAsync(buffer);
await Dispatcher.InvokeAsync(() =>
{
NotifyPropertyChanged(nameof(Progress));
NotifyPropertyChanged(nameof(Division));
});
}
W pierwszej linijce ustawiam przykładową nazwę UserAgenta. Na niektórych serwerach przy połączeniach SSL jest to wymagane.
Następnie wołam GET na adresie pliku (uri to dokładny adres pliku, np: https://example.com/files/big.avi).
Potem już czytam w pętli poszczególne bajty. To mi umożliwia pokazanie progressu pobierania pliku, a także wznowienie tego pobierania.
Możesz poeksperymentować z wielkością bufora. Jednak z moich testów wynika, że 8192 jest ok. Z jednej strony jego wielkość ma wpływ na szybkość pobierania danych. Z drugiej strony, jeśli bufor będzie zbyt duży, to może nie zdążyć się zapełnić w jednej iteracji i nie zyskasz na prędkości.
Koniec
No, to tyle co chciałem powiedzieć o HttpClient. To są bardzo ważne rzeczy, o których trzeba pamiętać. W głowie mam jeszcze jeden artykuł, ale to będą nieco bardziej… może nie tyle zaawansowane, co wysublimowane techniki korzystania z klienta.
Dzięki za przeczytanie artykułu. Jeśli znalazłeś w nim błąd lub czegoś nie zrozumiałeś, koniecznie podziel się w komentarzu.
Teraz już możesz logować i wylogowywać użytkowników.
Logowanie
Zidentyfikuj użytkownika ręcznie – po prostu w jakiś sposób musisz sprawdzić, czy podał prawidłowe dane logowania (login i hasło)
Stwórz ClaimsPrincipal dla tego użytkownika
Wywołaj HttpContext.SignIn -> to utworzy ciastko logowania i użytkownik będzie już uwierzytelniony w kolejnych żądaniach (HttpContext.User będzie zawierało wartość utworzoną w kroku 2)
Wylogowanie
Wywołaj HttpContext.SignOutAsync -> to zniszczy ciastko logowania. W kolejnych żądaniach obiekt HttpContext.User będzie pusty.
Jeśli masz jakiś problem, przeczytaj pełny artykuł poniżej.
UWAGA
W słowniku języka polskiego NIE ISTNIEJE słowo autentykacja. W naszym języku ten proces nazywa się uwierzytelnianiem. Słowo autentykacja zostało zapożyczone z angielskiego authentication. Dlatego też w tym artykule posługuję się słowem uwierzytelnianie.
Po co komu uwierzytelnianie bez Identity?
Może się to wydawać dziwne, no bo przecież Identity robi całą robotę. Ale jeśli chcesz uwierzytelniać użytkowników za pośrednictwem np. własnego WebApi albo innego mechanizmu, który z Identity po prostu nie współpracuje, to nie ma innej możliwości.
Uwierzytelnianie vs Identity
Musisz zdać sobie sprawę, że mechanizm uwierzytelniania i Identity to dwie różne rzeczy. Identity korzysta z uwierzytelniania, żeby mechanizm był pełny. A jakie są różnice?
Co daje Identity
Od Identity dostajesz CAŁĄ obsługę użytkownika. Tzn:
przechowywanie użytkowników (np. tworzenie odpowiednich tabel w bazie danych lub obsługa innego sposobu przechowywania danych użytkowników)
zarządzanie rolami użytkowników
i generalnie wiele innych rzeczy, które mogą być potrzebne w standardowej aplikacji
Mechanizm Identity NIE JEST dostępny na „dzień dobry”. Aby go otrzymać, możesz utworzyć nową aplikację z opcją Authentication type ustawioną np. na Individual Accounts.
Możesz też doinstalować odpowiednie NuGety i samemu skonfigurować Identity.
Co daje uwierzytelnianie?
tworzenie i usuwanie ciasteczek logowania (lub innego mechanizmu uwierzytelniania użytkownika)
tworzenie obiektu User w HttpContext podczas żądania
przekierowania użytkowników na odpowiednie strony (np. logowania, gdy nie jest zalogowany)
Jak widzisz, Identity robi dużo więcej i pod spodem korzysta z mechanizmów uwierzytelniania. Podczas konfiguracji Identity konfigurujesz również uwierzytelnianie.
Konfiguracja uwierzytelniania
Najprościej będzie, jeśli utworzysz projekt BEZ żadnej identyfikacji. Po prostu podczas tworzenia nowego projektu upewnij się, że opcja Authentication type jest ustawiona na NONE:
Dzięki temu nie będziesz miał dodanego ani skonfigurowanego mechanizmu Identity. I dobrze, bo jeśli go nie potrzebujesz, to bez sensu, żeby zaciemniał i utrudniał sprawę. Mechanizm Identity możesz sobie dodać w każdym momencie, instalując odpowiednie NuGety.
A teraz jak wygląda konfiguracja uwierzytelniania? Składa się tak naprawdę z trzech etapów:
zarejestrowania serwisów dla uwierzytelniania
konfiguracji mechanizmu, który będzie używany do odczytywania (zapisywania) informacji o zalogowanym użytkowniku (schematu)
dodanie uwierzytelniania do middleware pipeline.
Schemat
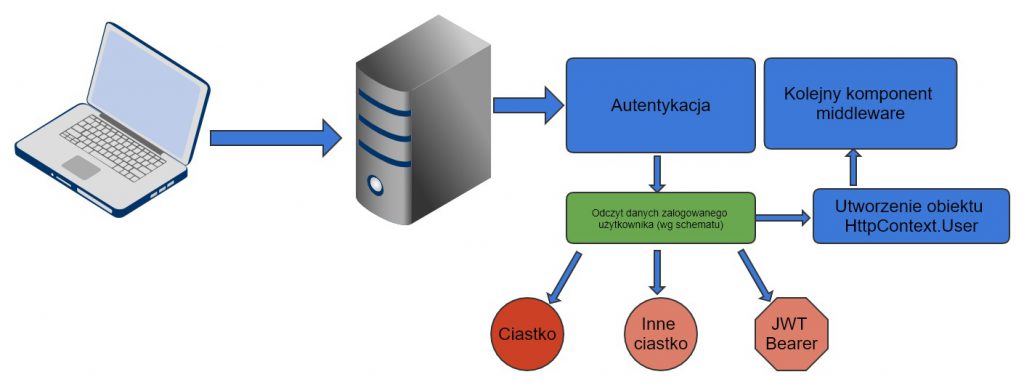
Zanim pójdziemy dalej, wyjaśnię Ci czym jest schemat. To nic innego jak określenie sposobu w jaki użytkownicy będą uwierzytelniani. Różne scenariusze mogą wymagać różnych metod uwierzytelniania. Każda z tych metod może wymagać innych danych. To jest właśnie schemat. Pisząc uwierzytelniać mam na myśli taki flow (w skrócie):
Klient wysyła żądanie do serwera (np. żądanie wyświetlenia strony z kontem użytkownika)
Mechanizm uwierzytelniania (który jest w middleware pipeline) rusza do roboty. Sprawdza, czy użytkownik jest już zalogowany, odczytując jego dane wg odpowiedniego schematu (z ODPOWIEDNIEGO ciastka, bearer token’a, BasicAuth lub jakiegokolwiek innego mechanizmu)
Na podstawie informacji odczytanych w punkcie 2, tworzony jest HttpContext.User
Rusza kolejny komponent z middleware pipeline
Każdy schemat ma swoją własną nazwę, możesz tworzyć własne schematy o własnych nazwach jeśli czujesz taką potrzebę.
Rejestracja serwisów uwierzytelniania
W pliku Program.cs lub Startup.cs (w metodzie ConfigureServices) możesz zarejestrować wymagane serwisy w taki sposób:
builder.Services.AddAuthentication();
To po prostu zarejestruje standardowe serwisy potrzebne do obsługi uwierzytelniania. Jednak bardziej przydatną formą rejestracji jest ta ze wskazaniem domyślnych schematów:
Jak już wiesz, każdy schemat ma swoją nazwę. W .NET domyślne nazwy różnych schematów są zapisane w stałych. Np. domyślna nazwa schematu opartego na ciastkach (uwierzytelnianie ciastkami) ma nazwę zapisaną w CookieAuthenticationDefaults. Analogicznie domyślna nazwa schematu opartego na JWT Bearer Token – JwtBearerDefaults.
Oczywiście, jeśli masz taką potrzebę, możesz nadać swoją nazwę.
Konfiguracja ciasteczka logowania
To drugi krok, jaki trzeba wykonać. Konfiguracja takiego ciastka może wyglądać tak:
W pierwszym parametrze podajesz nazwę schematu dla tego ciastka. W drugim ustawiasz domyślne opcje. Jeśli nie wiesz co one oznaczają i dlaczego tak, a nie inaczej, przeczytaj artykuł o ciastkach, w którym to wyjaśniam.
Na koniec ustawiasz dwie ścieżki:
ścieżka do strony z informacją o zabronionym dostępie
ścieżka do strony logowania
a także parametr return_url – o nim za chwilę.
Po co te ścieżki? To ułatwienie – element mechanizmu uwierzytelniania. Jeśli niezalogowany użytkownik wejdzie na stronę, która wymaga uwierzytelnienia (np. „Napisz nowy post”), wtedy automatycznie zostanie przeniesiony na stronę, którą zdefiniowałeś w LoginPath.
Analogicznie z użytkownikiem, który jest zalogowany, ale nie ma praw dostępu do jakiejś strony (np. modyfikacja użytkowników, do czego dostęp powinien mieć tylko admin) – zostanie przekierowany automatycznie na stronę, którą zdefiniowałeś w AccessDeniedPath.
Dodanie uwierzytelniania do middleware pipeline
Skoro mechanizm uwierzytelniania jest już skonfigurowany, musimy dodać go do pipeline. Pamiętaj, że kolejność komponentów w pipeline jest istotna. Dodaj go tuż przed autoryzacją:
To jest zwykły formularz ze stylami bootstrapa. Mamy trzy pola:
nazwa użytkownika
hasło
checkbox – pamiętaj mnie, żeby użytkownik nie musiał logować się za każdym razem
Nie stosuję tutaj żadnych walidacji, żeby nie zaciemniać obrazu.
Obsługa logowania
Teraz trzeba obsłużyć to logowanie – czyli przesłanie formularza. Do modelu strony dodaj metodę OnPostAsync (fragment kodu):
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
}
ApplicationUser Authorize(string name, string pass)
{
if (name == "Admin" && pass == "Admin")
{
ApplicationUser result = new ApplicationUser();
result.UserName = "Admin";
result.Id = 1;
return result;
}
else
return null!;
}
W trzeciej linijce walidujemy przekazany w formularzu model. Chociaż w tym przypadku testowym nie ma czego walidować, to jednak pamiętaj o tym.
W linijce 6 następuje próba zalogowania użytkownika. Przykładowa metoda Authorize jest oczywiście beznadziejna, ale zwróć tylko uwagę na to, co robi. W jakiś sposób sprawdza, czy login i hasło są poprawne (np. wysyłając dane do WebAPI). I jeśli tak, zwraca konkretnego użytkownika. Jeśli nie można było takiego użytkownika zalogować, zwraca null.
Zawartość metody Authorize zależy całkowicie od Ciebie. W przeciwieństwie do mechanizmu Identity, tutaj sam musisz stwierdzić, czy dane logowania użytkownika są poprawne, czy nie.
W następnej linijce sprawdzam, czy udało się zalogować użytkownika. Jeśli nie, wtedy ustawiam jakiś komunikat błędu i przeładowuję tę stronę.
A co jeśli użytkownika udało się zalogować? Trzeba stworzyć dla niego ciastko logowania. Ale to wymaga utworzenia obiektu ClaimsPrincipal.
Czym jest ClaimsPrincipal?
Krótko mówiąc, jest to zbiór danych, który przechowuje informacje na temat zalogowanego użytkownika. Pewnie chcesz zadać pytanie – czy to nie może być moja super klasa User? Nie, nie może. ClaimsPrincipal to pewien standardowy sposób przechowywania i przesyłania danych.
Wyobraź sobie, że jesteś strażnikiem w dużej firmie. Teraz podchodzi do Ciebie gość, który mówi, że jest dyrektorem z innej firmy, przyszedł na spotkanie i nazywa się Jan Kowalski. Sprawdzasz jego dowód (uwierzytelniasz go) i stwierdzasz, że faktycznie nazywa się Jan Kowalski. Co więcej, możesz stwierdzić że zaiste jest dyrektorem i przyszedł na spotkanie. Wydajesz mu zatem swego rodzaju dowód tożsamości – to może być identyfikator, którym będzie się posługiwał w Twojej firmie.
Teraz tego gościa możemy przyrównać do ClaimsPrincipal, a identyfikator, który mu wydałeś to ClaimsIdentity (będące częścią ClaimsPrincipal).
Na potrzeby tego artykułu potraktuj to właśnie jako zbiór danych identyfikujących zalogowanego użytkownika.
Tworzenie tożsamości (ClaimsPrincipal)
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
ClaimsPrincipal principal = CreatePrincipal(loggedUser);
}
ClaimsPrincipal CreatePrincipal(ApplicationUser user)
{
ClaimsPrincipal result = new ClaimsPrincipal();
List<Claim> claims = new List<Claim>()
{
new Claim(ClaimTypes.NameIdentifier, user.Id.ToString()),
new Claim(ClaimTypes.Name, user.UserName)
};
ClaimsIdentity identity = new ClaimsIdentity(claims);
result.AddIdentity(identity);
return result;
}
Tutaj tworzymy tożsamość zalogowanego użytkownika i dajemy mu dwa „poświadczenia” – Id i nazwę użytkownika. Mając utworzony obiekt ClaimsPrincipal, możemy teraz utworzyć ciastko logowania. To ciastko będzie przechowywało dane z ClaimsPrincipal:
await HttpContext.SignInAsync(principal);
Pamiętaj, żeby dodać using: using Microsoft.AspNetCore.Authentication;
Teraz niepełny kod wygląda tak:
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
ClaimsPrincipal principal = CreatePrincipal(loggedUser);
await HttpContext.SignInAsync(principal);
}
Podsumujmy tę część:
Walidujesz model otrzymany z formularza
W jakiś sposób sprawdzasz, czy przekazany login i hasło są prawidłowe – „ręcznie” uwierzytelniasz użytkownika
Na podstawie uwierzytelnionego użytkownika tworzysz obiekt ClaimsPrincipal, który jest potrzebny do utworzenia ciastka logowania.
Tworzysz ciastko logowania. Od tego momentu, w każdym żądaniu, obiekt HttpContext.User będzie miał te wartości, które utworzyłeś w kroku 3. Wszystko dzięki ciastku logowania, które przy każdym żądaniu utworzy ten obiekt na podstawie swoich wartości.
Nie musisz tutaj podawać schematu uwierzytelniania, ponieważ zdefiniowałeś domyślny schemat podczas konfiguracji uwierzytelniania.
Pamiętaj mnie
W powyższym kodzie nie ma jeszcze użytej opcji „Pamiętaj mnie”. Ta opcja musi zostać dodana podczas tworzenia ciastka logowania. Wykorzystamy tutaj przeciążoną metodę SignInAsync, która przyjmuje dwa parametry:
Czyli do właściwości IsPersistent przekazałeś wartość pobraną od użytkownika, który powiedział, że chce być pamiętany w tej przeglądarce (true) lub nie (false). O tym właśnie mówi IsPersistent.
Ale ten kod wciąż nie jest pełny.
Przekierowanie po logowaniu
Po udanym (lub nieudanym) logowaniu trzeba gdzieś użytkownika przekierować. Najwygodniej dla niego – na stronę, na którą próbował się dostać przed logowaniem. Spójrz na taki przypadek:
niezalogowany użytkownik wchodzi na Twoją stronę, żeby zobaczyć informacje o swoim koncie: https://www.example.com/Account
System uwierzytelniania widzi, że ta strona wymaga poświadczeń (gdyż jest opatrzona atrybutem Authorize), a użytkownik nie jest zalogowany. Więc zostaje przekierowany na stronę logowania. A skąd wiadomo gdzie jest strona logowania? Ustawiłeś ją podczas konfiguracji ciastka do logowania.
Po poprawnym zalogowaniu użytkownik może zostać przekierowany np. na stronę domową: "/Index" albo lepiej – na ostatnią stronę, którą chciał odwiedzić, w tym przypadku: https://www.example.com/Account
Ale skąd masz wiedzieć, na jaką stronę go przekierować? Spójrz jeszcze raz na konfigurację ciastka logowania:
Jeśli mechanizm uwierzytelniania przekierowuje Cię na stronę logowania, dodaje do adresu parametr, który skonfigurowałeś w ReturnUrlParameter. A więc w tym przypadku "return_url". Ostatecznie niezalogowany użytkownik zostanie przekierowany na taki adres: https://example.com/Login?return_url=/Account
(w przeglądarce nie zauważysz znaku „/”, tylko jego kod URL: %2F)
To znaczy, że na stronie logowania możesz ten parametr pobrać:
public class LoginPageModel : PageModel
{
[BindProperty]
public string UserName { get; set; } = string.Empty;
[BindProperty]
public string Password { get; set; } = string.Empty;
[BindProperty]
public bool RememberMe { get; set; }
[FromQuery(Name = "return_url")]
public string? ReturnUrl { get; set; }
//
}
Pamiętaj, że parametru return_url nie będzie, jeśli użytkownik wchodzi bezpośrednio na stronę logowania. Dlatego też zwróć uwagę, żeby oznaczyć go jako opcjonalny – string?, a nie string
Następnie wykorzystaj go podczas logowania:
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return Page();
ApplicationUser loggedUser = Authorize(UserName, Password);
if(loggedUser == null)
{
TempData["Error"] = "Niepoprawne dane logowania!";
return RedirectToPage();
}
ClaimsPrincipal principal = CreatePrincipal(loggedUser);
AuthenticationProperties props = new AuthenticationProperties();
props.IsPersistent = RememberMe;
await HttpContext.SignInAsync(principal, props);
if (string.IsNullOrWhiteSpace(ReturnUrl))
ReturnUrl = "/Index";
return RedirectToPage(ReturnUrl);
}
UWAGA!
Pamiętaj, żeby w takim przypadku NIE STOSOWAĆ metody Redirect, tylko RedirectToPage (lub w RazorView – RedirectToAction). Metoda Redirect pozwala na przekierowanie do zewnętrznego serwisu, co w tym przypadku daje podatność na atak „Open Redirect”. Dlatego też stosuj RedirectToPage -> ta metoda nie pozwoli na przekierowanie zewnętrzne.
Wylogowanie
Kiedyś użytkownik być może będzie się chciał wylogować. Na czym polega wylogowanie? Na usunięciu ciastka logowania. Robi się to jedną metodą:
await HttpContext.SignOutAsync();
Ta metoda usunie ciastko logowania i w kolejnych żądaniach obiekt HttpContext.User będzie pusty.
To właściwie tyle jeśli chodzi o mechanizm uwierzytelniania. Jeśli czegoś nie rozumiesz lub znalazłeś błąd w artykule, daj znać w komentarzu. Jeśli uważasz ten artykuł za przydatny, również daj znać. Będzie mi miło 🙂 I koniecznie zapisz się na newsletter, żeby nic Cię nie ominęło.
W 2018 roku weszło RODO. Wszystkie strony działające na terenie Unii Europejskiej (to dotyczy też np. sklepów w USA, na których można kupować mieszkając w UE) muszą mieć odpowiednie mechanizmy zabezpieczające politykę prywatności i dane. O tych mechanizmach jest ten artykuł.
Jeśli masz małe pojęcie o ciasteczkach lub nie znasz ich do końca (nie znasz ich parametrów), przeczytaj ten artykuł.
Co z tym RODO?
Jakiś czas temu na terenie Unii Europejskiej weszło GDPR (po polsku RODO). W skrócie, jeśli chodzi o ciasteczka, użytkownik musi zostać poinformowany o polityce prywatności, a także musi zaakceptować niektóre ciasteczka. Poza tym RODO nakłada obowiązek odpowiedniego przetwarzania danych osobowych, co wiąże się z bezpieczeństwem tych danych, administracją itd. Ale nie o tym nie o tym.
.NET ma już gotowe mechanizmy, które wystarczy podpiąć. Pytanie tylko – czy tego potrzebujesz?
Zaznaczam, że nie jestem prawnikiem. Generalnie jeśli zbierasz jakiekolwiek informacje o użytkowniku za pomocą ciasteczek (chociażby listę rzeczy, które kupił w Twoim sklepie lub ostatnio zakupiony produkt albo też śledzisz jego ruchy na Twojej witrynie), to prawnie powinieneś go o tym poinformować, a on musi na to wyrazić zgodę. Jeśli tego nie zrobisz, to Ty możesz mieć później problemy prawne i płacić kary. Także nie lekceważ tego obowiązku. Większość użytkowników i tak zawsze klika „OK”, nie czytając nawet polityki prywatności. A gotowy mechanizm załatwia wszystko.
Google Analytics i inne aplikacje śledzące
Pamiętaj też, że jeśli używasz google analytics, czy też Smartlook (pokazuje dokładnie co użytkownik robi na Twojej stronie – jak na filmie – polecam), to też musisz o tym poinformować.
Polityka prywatności
Na pierwszy ogień idzie polityka prywatności, którą musisz mieć na swojej stronie. Na szczęście domyślny szablon WebApplication z VisualStudio ma już taką stronę – Privacy.cshtml. Powinieneś tam właśnie wpisać swoją politykę. Pewnie teraz pytanie – skąd to wziąć? Odpowiedź prawilna – skontaktuj się z prawnikiem; odpowiedź nieprawilna – skopiuj z podobnej strony. Ale na BOGA! Przeczytaj ją, zrozum i zmodyfikuj pod swoje potrzeby. I najlepiej daj ją na koniec do przeczytania prawnikowi, niech się wypowie. To Ty jesteś za to odpowiedzialny…
Teraz skonfigurujemy mechanizm wyrażania zgody na ciasteczka. Ta informacja (czy user wyraził zgodę, czy nie) jest zapisywana w… ciasteczku 😉 Ale to specjalne „ciasteczko zgody”, które na stronie MUSI być i jest niezbędne do prawidłowego działania aplikacji (esencjonalne).
W pliku Startup.cs w metodzie ConfigureServices dodaj taki kod:
CookiePolicyOptions ma jeszcze kilka ciekawych elementów:
OnDeleteCookie – akcja wywoływana podczas usuwania ciasteczka
ConsentCookie – parametry ciasteczka, które zapamiętuje zgodę użytkownika na ciasteczka 🙂
OnAppendCookie – akcja wywoływana podczas dodawania ciasteczka
Secure – czy ciasteczka muszą być bezpieczne (CookieOptions.Secure = true)
HttpOnly – czy ciasteczka muszą mieć atrybut HttpOnly
Dodanie polityki do middleware
Następnie w metodzie Configure musisz dodać tę politykę do middleware:
app.UseStaticFiles();
app.UseCookiePolicy();
Dodaj to za UseStaticFiles i przed UseRouting. Właściwie przed jakimkolwiek użyciem ciasteczek śledzących.
Konfiguracja w .NET6
Jeśli używasz .NET6, możesz nie mieć pliku Startup.cs i metod ConfigureServices i Configure. W takim przypadku dodajesz te elementy normalnie w pliku Program.cs analogicznie do innych, np:
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddControllersWithViews();
builder.Services.Configure<CookiePolicyOptions>(options =>
{
options.CheckConsentNeeded = context => true;
options.MinimumSameSitePolicy = SameSiteMode.None;
});
var app = builder.Build();
// Configure the HTTP request pipeline.
if (!app.Environment.IsDevelopment())
{
app.UseExceptionHandler("/Home/Error");
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseCookiePolicy();
UWAGA!
Pamiętaj, że mechanizm polityki zablokuje tworzenie ciasteczek, jeśli użytkownik nie wyrazi na nie zgody. Podczas tworzenia takiego ciastka, które nie jest oznaczone jako IsEssential zostanie wywołany cichy wyjątek i ciasteczko nie zostanie dołączone do odpowiedzi idącej do przeglądarki. Jeśli jednak masz na stronie ciastka, które niczego nie śledzą, ale są konieczne do poprawnego działania serwisu, oznacz je jako essential: CookieOptions.IsEssential = true. Takie ciastko zostanie zapisane nawet jeśli użytkownik nie wyrazi zgody na śledzenie. Pamiętaj tylko, że te ciastka nie mogą śledzić jego ruchów.
Dodanie informacji do widoku/strony
Teraz musisz dodać informację o ciasteczkach do swoich widoków. Po prostu zmodyfikuj _Layout.cshtml. Odszukaj div z klasą container i dodaj w nim partialview:
Teraz dodaj plik _CookieConsentPartial.cshtml do folderu Views/Shared lub Pages:
@using Microsoft.AspNetCore.Http.Features
@{
var consentFeature = Context.Features.Get<ITrackingConsentFeature>();
var showBanner = !consentFeature?.CanTrack ?? false;
var cookieString = consentFeature?.CreateConsentCookie();
}
@if (showBanner)
{
<div id="cookieConsent" class="alert alert-dark alert-dismissible fade show" role="alert">
Strona używa ciasteczek. <a asp-controller="Home" asp-action="Privacy">Przeczytaj naszą politykę prywatności</a>.
<button type="button" class="accept-policy close" data-dismiss="alert" aria-label="Close" data-cookie-string="@cookieString">
<span aria-hidden="true">Akceptuję</span>
</button>
</div>
<script>
(function () {
var button = document.querySelector("#cookieConsent button[data-cookie-string]");
button.addEventListener("click", function (event) {
document.cookie = button.dataset.cookieString;
}, false);
})();
</script>
}
W tym kodzie nie ma niczego dziwnego (pochodzi z oficjalnej dokumentacji Microsoftu i korzysta z Bootstrapa). Po prostu dopisz tutaj swój komunikat albo skonstruuj własnego diva. Ważne jest to, żeby pokazać tego diva jeśli użytkownik nie wyraził zgody na ciasteczka i nie pokazywać go, gdy wyraził.
Po wciśnięciu przycisku, JavaScript zapisze cookie przesłane w danych tego przycisku (atrybut data-cookie-string). Zauważ, że cały string tworzący cookie otrzymałeś z metody CreateConsentCookie().
Po wyrażeniu zgody w taki sposób (zapisaniu ciasteczka z CreateConsentCookie()), framework już normalnie obsłuży wszystkie Twoje ciastka.
I to właściwie tyle. Jeśli czegoś nie rozumiesz albo znalazłeś błąd w tekście, daj znać w komentarzu
Skoro tu jesteś to pewnie używałeś ciasteczek, być może nie do końca świadomie albo nie wiedząc o pewnych niuansach. W tym artykule wyjaśnię czym dokładnie są te ciasteczka i opiszę wszystkie zawiłości, na jakie kiedykolwiek trafiłem. Więc nawet jeśli używasz ciasteczek, ten artykuł może Ci trochę rozjaśnić i odpowiedzieć na kilka pytań, które bałeś się zadać.
Czym są ciasteczka
Ciasteczko to nic innego jak dane przechowywane na komputerze użytkownika. To string składający się z pary klucz=wartość i kilku atrybutów. Ciasteczko zazwyczaj (w zależności od przeglądarki) jest fizycznie reprezentowane jako plik. Każde ciasteczko ma swoją nazwę (klucz). Powoduje to, że do jego zawartości możemy się dobrać właśnie przez nazwę w taki sposób (pseudokod):
string dane = GetCookieByName("moje_ciastko");
SetCookieByName("moje_ciastko", "całkiem nowe dane");
Ciasteczko ma też kilka właściwości jak np. data ważności (expire date). Ale o tym później.
Ma też ograniczenie co do ilości danych – w zależności od przeglądarki, ale załóż, że maks to 4 kB.
Ciasteczka są przesyłane z klienta do serwera i na odwrót za pomocą nagłówków HTTP. Więc staraj się, żeby jednak były małe. I staraj się, żeby nie było ich zbyt dużo.
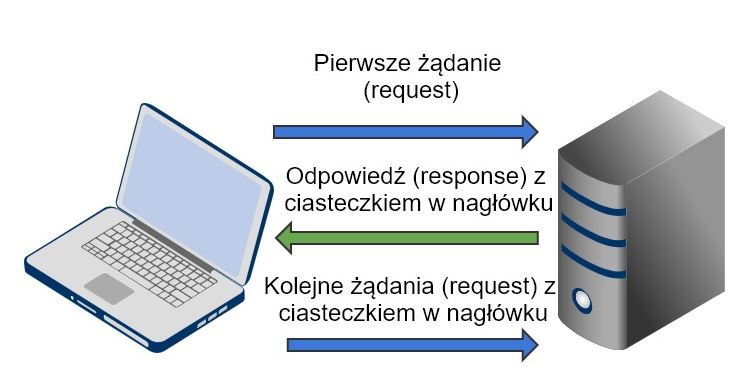
Teraz możesz zadać pytanie – „ale jak to przesyłane w nagłówku, skoro są na komputerze użytkownika?”
No tak, ale z każdym żądaniem (np. żądanie wyświetlenia strony) przeglądarka wysyła do serwera wszystkie ciastka dla danej strony. Serwer też może wysłać w odpowiedzi na żądanie specjalny nagłówek, który spowoduje, że przeglądarka zapisze ciastko. O tym wszystkim już za chwilę.
Po co ciasteczka?
Wszystko rozbija się o to, że HTTP jest protokołem bezstanowym. Oznacza to, że pomiędzy dwoma wyświetleniami strony nie zachowuje się żaden stan – nie można przechować zmiennych. One są niszczone za każdym razem. Nie można nawet sprawdzić, kto jest zalogowany. Trzeba było ogarnąć jakiś sposób na zarządzanie stanem w aplikacjach internetowych. Jednym z tych sposobów są ciasteczka.
Czym się różni sesja od ciasteczka?
W dużym skrócie sesje też są zbiorem danych. Działają podobnie do ciasteczek, tylko są zapisywane na serwerze. Ciasteczka natomiast zapisują się na komputerze użytkownika. Sesje mogą zależeć od ciasteczek (np. ciasteczko może przechowywać id sesji), ale nie na odwrót. Co więcej sesja kończy się w momencie wylogowania, natomiast ciasteczko – gdy skończy mu się okres ważności (może to być tak długie jak kilka lat albo tak krótkie jak otwarcie przeglądarki). Sesje nie mają też żadnego narzuconego ograniczenia co do ilości danych.
Ciasteczka trwałe i nietrwałe
Ciasteczka mogą być trwałe (persistent) lub nietrwałe (non-persistent). Trwałe ciasteczko jest zapisywane w pliku na dysku użytkownika lub w bazie przeglądarki. Nietrwałe ciasteczka istnieją tylko w pamięci przeglądarki. Nazywa się je również „ciasteczkami sesyjnymi”. Takie ciasteczka tworzy się nie nadając im daty ważności. Czyli ich życie kończy się wraz z zamknięciem przeglądarki.
Tworzenie ciasteczka
Ciasteczko może zostać utworzone przez klienta, jak również przez serwer (to pewien skrót myślowy). W tym drugim przypadku serwer w odpowiedzi na żądanie wysyła nagłówek (Set-Cookie) z ciasteczkiem, który jest odczytywany przez przeglądarkę i ona piecze takie ciasteczko.
W pierwszym przypadku ciasteczko jest zapisywane przez… ehhh… JavaScript.
Teraz będziemy robić kody. Stwórz sobie jakiś projekt testowy, niech to będzie domyślne Asp NetCore WebApp (MVC lub RazorPages) z VisualStudio.
Ciasteczko w JavaScript
Otwórz plik Index.cshtml. Dodaj tam przycisk, który zapisze ciasteczko:
Kod jest bardzo prosty – wciśnięcie przycisku odpala funkcję w JavaScript, która ustawia ciasteczko. Nazwa tego ciasteczka (klucz) to username, a wartość „Adam”. Równie dobrze mógłby tam być cały obiekt zapisany w JSON.
Uruchom teraz ten przykład, ale nie wciskaj jeszcze guzika. Uruchom narzędzia dla developerów w swojej przeglądarce. Ja używam FireFoxa i do tego jest skrót Ctrl + Shift + I. Jeśli nie używasz FireFoxa, w innych przeglądarkach te narzędzia są podobne, więc nie będziesz miał raczej problemu. Tutaj ciasteczka są na karcie DANE.
Spójrz na zawartość ciasteczek w tym oknie:
Widzisz tutaj jakieś 4 ciasteczka na „dzień dobry”. Pochodzą z .NET, nie zajmujmy się nimi teraz.
Wciśnij teraz przycisk, który dodałeś na stronie i zobacz, co się stanie. Powstało nowe ciasteczko o nazwie username:
To ciasteczko będzie żyło aż do zamknięcia przeglądarki. Możesz mu podać też expire date, który usunie konkretne ciasteczko (jeśli data będzie w przeszłości) lub nada mu konkretny czas życia. Wszystko to jest dokładnie opisane na w3schools więc nie będę się rozwodził na temat JavaScriptu więcej 😉
Ciasteczko w .NET
JavaScript jest o tyle miłe, że działa na kliencie. To znaczy, że może utworzyć ciasteczko bezpośrednio na Twoim komputerze. .NET jednak działa na serwerze, co nam daje trochę więcej komunikacji między klientem a serwerem. Czasem też nie da się inaczej:
klient musi wysłać żądanie do serwera (np. GET http://moja-strona.pl)
serwer musi odebrać to żądanie, przetworzyć je i odpowiedzieć na nie, wysyłając ciasteczko
przeglądarka odbierze ciasteczko i zapisze je na dysku lub w swojej bazie.
Zróbmy teraz te wszystkie kroki za pomocą małego formularza. W pliku index.cshtml stwórz prostą formatkę:
Następnie stwórz odpowiednią akcję w kontrolerze (analogicznie to będzie w Razor Pages). W pliku HomeController.cs dopisz metodę Index z metodą POST – to tutaj zostanie wysłany formularz:
Spójrz jak to teraz wygląda. Po kliknięciu przycisku, wysyłane jest żądanie z formularzem na serwer. Na serwerze odczytujemy wartość formularza i do response’a (czyli odpowiedzi, którą generujemy dla klienta) dodajemy nowe ciasteczko. Przeglądarka po otrzymaniu takiej odpowiedzi (z ciasteczkiem) tworzy je fizycznie.
Odczyt ciasteczka
Ciasteczko możemy odczytać też za pomocą JavaScript lub .NET. Jednak JavaScript dostaje wszystkie ciastka dla danej strony, więc sami sobie je musimy parsować. W .NET już to jest zrobione normalnie. Musimy tylko odczytać je na serwerze podczas żądania.
Pamiętaj, że otrzymujesz tylko swoje ciasteczka. Tzn. przeglądarka zwróci ciasteczka tylko dla konkretnej domeny – dla tej, która je utworzyła (z małym wyjątkiem – o tym później). Czyli jeśli wysyłasz żądanie do strony example.com, przeglądarka doda do nagłówków ciasteczka utworzone przez example.com.
Zmień zatem metodę Index (tę domyślną) w taki sposób, aby odczytać to ciasteczko:
public IActionResult Index()
{
var userName = HttpContext.Request.Cookies["username_fromnet"];
ViewData["userName"] = userName;
return View();
}
Zwróć uwagę, że tym razem odczytujemy ciastko z HttpContext.Request – czyli z żądania, które idzie od klienta do serwera. Zapisujemy ciasteczko w odpowiedzi na to żądanie, czyli w HttpContext.Response.
Gdy użytkownik uruchamia aplikację, idzie żądanie do serwera (wraz z wszystkimi ciasteczkami odczytanymi przez przeglądarkę) i wchodzi do metody Index. Stąd odczytujemy sobie konkretne ciasteczko i przekazujemy jego wartość do danych widoku. Na koniec pokazujemy widok, który lekko się zmienił:
Pobieramy dane z ViewData do zmiennej userName. Jeśli teraz ta zmienna nie ma żadnej wartości, to wyświetlamy formularz. Jeśli ma – wyświetlamy powitanie.
Parametry ciasteczka
Jak pisałem wyżej, ciasteczko może mieć swoje parametry. Klasą, która je opisuje jest CookieOptions:
CookieOptions.Expires
Określa czas życia ciasteczka. Zazwyczaj po prostu dodaje się jakąś datę do aktualnej, np. DateTime.Now.AddDays(30). Ciasteczko zostanie usunięte po tej dacie. Co jednocześnie powoduje, że jeśli podasz datę wcześniejszą niż aktualna, ciasteczko zostanie usunięte natychmiast. Pamiętaj, że na serwerze możesz mieć inną datę niż na komputerze użytkownika. Więc ostrożnie z tym.
CookieOptions.MaxAge
Działa podobnie do Expires. Też określa czas życia ciasteczka z tą różnicą, że nie podajesz daty zakończenia życia, tylko jego czas, np: MaxAge = TimeSpan.FromDays(30) – takie ciasteczko po 30 dniach od utworzenia zostanie usunięte. Jest to nowsza, lepsza i bardziej wygodna opcja niż Expires.
CookieOptions.Domain
Domyślnie ciasteczko należy do domeny, która je utworzyła. Czyli jeśli utworzysz ciasteczko z domeny example.com, zostanie ono odczytane zarówno dla domeny example.com, jak i SUBDOMENY www – www.example.com. Jeśli jednak ciasteczko zostanie utworzone z subdomeny www – www.example.com, nie będzie widoczne z domeny example.com. Dlatego też powinieneś skonfigurować domenę na domenę główną, np: CookieOptions.Domain = ".example.com" (kropka na początku) To spowoduje, że ciasteczko będzie dostępne zarówno z domeny głównej jak i z wszystkich subdomen (w szczególności „www”). Jeśli więc masz problem, bo raz ciasteczko działa a raz nie, to pewnie dlatego, że raz Twoja strona jest uruchamiana z subdomeny (www.example.com), a raz nie. Przyjrzyj się temu.
Pamiętaj, że „www” jest subdomeną. Takich subdomen możesz mieć wiele, np: mail.example.com, dev.example.com, git.example.com… Ale chciałbyś, żeby ciasteczka działały tylko na subdomenie www i domenie głównej. Jak to zrobić?
Nie znalazłem na to odpowiedzi, a wszystkie moje testy się nie powiodły. Jeśli masz pomysł, koniecznie podziel się w komentarzu. Z mojej wiedzy wynika, że można mieć ciasteczko albo dla wszystkich subdomen i domeny głównej, albo dla jednej subdomeny, albo dla domeny głównej.
CookieOptions.Path
Podobnie do Domain. Z tą różnicą, że tutaj chodzi o ścieżkę w adresie. Domyślnie Path jest ustawiane na „/”, co oznacza, że ciasteczko będzie dostępne dla wszystkich podstron/routów z Twojego serwisu. Jeśli jednak ustawisz np. na "/login/" oznacza to, że ciasteczko będzie dostępne tylko ze ściezki "login" i dalszych, np: www.example.com/login, www.example.com/login/facebook
CookieOptions.HttpOnly
To specjalny rodzaj ciastka mający na celu zapobieganie pewnym atakom (np. XSS – Cross site scripting). Oczywiście nie polegaj na tym w 100%. Generalnie chodzi o to, że ciastka z takim atrybutem nie mogą (nie powinny) być odczytywane przez JavaScript. Po prostu document.cookies nie zwróci takiego ciastka. Możesz jedynie odczytać je na serwerze – HttpContext.Request.Cookies.
CookieOptions.Secure
Jeśli ustawione na true, ciasteczko zostanie wysłane z przeglądarki do serwera tylko wtedy, jeśli komunikacja odbywa się po HTTPS.
CookieOptions.SameSite
Ten parametr odpowiada za bezpieczeństwo ciasteczek. Ciastka są z natury podatne na pewne ataki. Atrybut SameSite ma tą podatność zmniejszyć. Jak?
Wyobraź sobie dwie strony. Twoja – www.example.com i jakaś inna – www.abc.com.
Na stronie www.abc.com znajduje się ramka (iframe), do której ładowana jest Twoja strona. A więc ze strony www.abc.com idzie żądanie do Twojej. W tym momencie przeglądarka odczytuje Twoje ciasteczka i wysyła je do strony www.abc.com.
Możesz teraz zrobić prosty test. Poniżej masz przycisk i ramkę. Otwórz narzędzia deweloperskie (Shift + Ctrl + I) i przejdź na zakładkę „Sieć” (Network). Teraz wciśnij poniższy przycisk (Załaduj Google do ramki) i zobacz, co się dzieje w „sieci”. Poszło żądanie do Google wraz z odpowiedziami – co więcej niektóre odpowiedzi zawierają ciasteczka (to nagłówki „Set-Cookie”)
Wyobraź sobie teraz taką sytuację, że masz stronę, na której ktoś jest zalogowany. Id sesji znajduje się w zwykłym ciasteczku. Teraz, jeśli taki zalogowany użytkownik otworzy tak spreparowaną stronę, ta strona dostanie to właśnie ciasteczko z id jego sesji. Dzięki temu strona www.abc.com będzie mogła dobrać się do sesji zalogowanego użytkownika w Twoim serwisie i w jego imieniu wykonywać operacje. To tak z grubsza. Taki atak nazywa się CSRF (Cross site request forgery).
Przeglądarki nie rozróżniają kto wysłał żądanie – użytkownik, czy inny skrypt. Teraz z pomocą przychodzi atrybut SameSite.
SameSite w .NET może przyjąć 4 wartości:
Unspecified
None
Lax
Strict
Wartość STRICT
Ustawienie SameSite na strict spowoduje, że jeśli żądanie przyjdzie z innej domeny niż ta ustawiona w ciasteczku, ciastko nie zostanie dołączone do odpowiedzi.
Wartość LAX
Jeśli żądanie idzie „bezpieczną” metodą (np. GET) i dodatkowo zmieni się adres w przeglądarce, to wtedy ciasteczka zostaną wysłane.
Wartość NONE
Pozwala na przekazywanie ciasteczek pomiędzy stronami bez żadnych restrykcji.
Wartość UNSPECIFIED
Atrybut w ogóle nie zostanie dołączony do ciasteczka, co spowoduje domyślne zachowanie przeglądarki.
Domyślnie wszystkie ciasteczka w .NET są ustawione na SameSite = Lax.
Oznacza dane ciastko jako niezbędne do funkcjonowania strony. Takie ciastko nie może śledzić poczynań użytkowników.
To właściwie tyle jeśli chodzi o ciastka. Będziesz ich jeszcze używał do automatycznego logowania użytkownika, ale to już temat na inny artykuł, który napiszę wkrótce. Także zapisz się na newsletter, żeby go nie pominąć 🙂
Jeśli trafiłeś tu tylko po to, żeby dowiedzieć się, jak walidować złożony obiekt, zobacz końcówkę artykułu.
Kiedyś napisałem co nieco o walidacji w .NetCore MVC. Możesz te artykuły przeczytać tu i tu. Powinieneś je przeczytać, ponieważ mówią również o podstawach walidacji jako takiej (w tym o data annotation validation, którym będziemy się tu posługiwać).
Wchodząc w świat Blazor, bardzo szybko będziesz chciał tworzyć formularze i je walidować. Na szczęście w Blazor jest to chyba jeszcze prostsze niż w Razor.
Pierwszy formularz
Blazor ma wbudowany komponent, który nazywa się EditForm. Jak można się domyślić, jest to po prostu formularz. Ma on kilka ciekawych możliwości, w tym artykule skupimy się jednak tylko na walidacji.
Na początek stwórzmy bardzo prosty model – Customer. Tę klasę utworzymy oczywiście w osobnym pliku Customer.cs.
public class Customer
{
[Required]
[StringLength(50, MinimumLength = 5)]
public string Name { get; set; }
}
Jest klasa z jednym polem i dodanymi adnotacjami:
Pole jest wymagane
Musi mieć długość minimum 5 znaków i maksimum 50.
Teraz utwórzmy w pliku .razor stronę z formularzem:
Spójrz, co mamy w sekcji code. Tworzymy nowy obiekt dla naszego modelu. To jest ważne, ponieważ ten obiekt powiążesz z formularzem.
Teraz spójrz wyżej na komponent EditForm. To jest właściwie najbardziej podstawowa konstrukcja formularza. Mamy właściwość Model, która określa OBIEKT powiązany (zbindowany) z formularzem. Pamiętaj, że to jest obiekt utworzony w sekcji code, a nie nazwa klasy.
Dalej mamy zdarzenie OnValidSubmit. Przypisujemy tutaj metodę, która wykona się po wysłaniu formularza, gdy będzie on prawidłowy. Z tego wynika, że ta metoda nie zostanie wykonana, jeśli formularz będzie zawierał błędy (są inne zdarzenia, które do tego służą).
Dalej w formularzu masz komponent InputText, który określa powiązanie z odpowiednim polem modelu – za pomocą @bind-value – czyli typowy binding z Blazor.
No i na koniec mamy guzik do wysłania formularza – pamiętaj, że w formularzu możesz mieć TYLKO JEDEN guzik typu submit.
Dodajemy walidację do strony
Przede wszystkim trzeba powiedzieć formularzowi, żeby walidował model za pomocą DataAnnotations (można to zrobić inaczej, ale w tym artykule skupiamy się na prostych podstawach). W tym celu trzeba mu dorzucić komponent DataAnnotationsValidator:
Właściwie to załatwia sprawę, formularz może być już walidowany. Sprawdź to. Jeśli spróbujesz wysłać pusty formularz, wymagane pole zaświeci się na czerwono.
Komunikaty błędów
Pewnie chciałbyś uzyskać jakiś komunikat błędu? Można to zrobić na kilka sposobów. Najprościej – dodaj komponent ValidationSummary – czyli podsumowanie walidacji.
Możesz go dodać w dowolnym miejscu formularza – tutaj pojawią się po prostu komunikaty o błędach. Uruchom teraz i zobacz, co się stanie, gdy podasz nieprawidłowe dane:
Widzimy opis błędu i podświetlone konkretne pole. Przy czym zwróć uwagę, że opis błędu wskazuje konkretnie na pole o nazwie „Name” – to zostało wzięte z modelu. Można to zmienić. Wszystkie rodzaje inputów (a jest ich kilka) w EditForm mają właściwość DisplayName. Dodaj ją:
<InputText id="name" @bind-Value="Customer.Name" DisplayName="imię i nazwisko"/>
To jest po prostu przyjazna nazwa pola dla walidacji. Niestety w mojej wersji Blazor (wrzesień 2021) ta właściwość nie chce działać. Ale nic to. I tak w prawdziwym świecie posłużymy się odpowiednią adnotacją w modelu:
public class Customer
{
[Required(ErrorMessage = "Musisz wypełnić imię i nazwisko")]
[StringLength(50, MinimumLength = 5, ErrorMessage = "Imię i nazwisko musi być dłuższe niż 5 znaków i krótsze niż 50")]
public string Name { get; set; }
}
W artykule o własnej walidacji w .NetCore pisałem też o tym, jak zrobić wymagany checkbox. Np do akceptacji regulaminu. Wtedy trzeba było się nieźle nakombinować. Dzisiaj jest dużo prościej i zdecydowanie bardziej przyjaźnie. Spójrz na model:
public class Customer
{
[Required(ErrorMessage = "Musisz wypełnić imię i nazwisko")]
[StringLength(50, MinimumLength = 5, ErrorMessage = "Imię i nazwisko musi być dłuższe niż 5 znaków i krótsze niż 50")]
public string Name { get; set; }
[Required]
[Range(typeof(bool), "true", "true", ErrorMessage = "Musisz zaakceptować plitykę prywatności")]
public bool PrivacyAgreed { get; set; }
}
Nie wiem jak Ty, ale ja nie lubię widzieć całej listy rzeczy, które zostały źle wprowadzone. Lubię, jak każdy błąd jest wyświetlony przy konkretnym polu. Można to zrobić bardzo prosto.
Błędy przy konkretnych polach
W tym momencie możesz pozbyć się komponentu ValidationSummary. To on właśnie pokazuje pełną listę błędów. Pamiętaj jednak, żeby zostawić DataAnnotasionsValidator, który odpowiada za walidację.
Teraz do każdego walidowanego pola możesz dodać komponent ValidationMessage:
Oczywiście te komponenty możesz umieścić gdziekolwiek w formularzu. Za pomocą właściwości For określasz, do którego pola się odnoszą. Zwróć uwagę, że przekazujesz tam lambdę, a nie nazwę pola
Wszystko fajnie, tylko że brzydko. A co, jeśli chcielibyśmy trochę popracować nad wyglądem komunikatów? Można to zrobić. W standardowym projekcie znajduje się plik site.css (w katalogu wwwroot/css). Jak sobie popatrzysz do środka, zobaczysz taki styl:
.validation-message {
color: red;
}
To właśnie odpowiada za wygląd komunikatów. Możemy to zmienić, np:
Co ma każdy klient? Każdy klient ma swój adres. Stwórzmy teraz bardzo prosty model adresu:
public class Address
{
[Required(ErrorMessage = "Musisz podać nazwę ulicy")]
public string StreetName { get; set; }
[Required(ErrorMessage = "Musisz podać numer ulicy")]
public string StreetNumber { get; set; }
[Required(ErrorMessage = "Musisz podać miasto")]
public string City { get; set; }
}
I dodajmy go do modelu klienta, a także do formularza:
public class Customer
{
[Required(ErrorMessage = "Musisz wypełnić imię i nazwisko")]
[StringLength(50, MinimumLength = 5, ErrorMessage = "Imię i nazwisko musi być dłuższe niż 5 znaków i krótsze niż 50")]
public string Name { get; set; }
[Required]
[Range(typeof(bool), "true", "true", ErrorMessage = "Musisz zaakceptować plitykę prywatności")]
public bool PrivacyAgreed { get; set; }
public Address Address { get; set; } = new Address();
}
Okazuje się, że Blazor ma pewne problemy z takimi polami, chociaż być może jest to celowe działanie. Jeszcze dosłownie niedawno trzeba było tworzyć obejścia. Jednak teraz mamy to PRAWIE w standardzie:
Pobierz NuGet: Microsoft.AspNetCore.Components.DataAnnotations.Validation. UWAGA! Na wrzesień 2021 ten pakiet nie jest jeszcze oficjalnie wydany. Jest to prerelease. A więc możliwe, że będziesz musiał zaznaczyć opcję Include Prerelase w NuGet managerze:
W swoim modelu Customer oznacz pole Address atrybutem: ValidateComplexType. Pamiętaj, że jest to składnik pobranego właśnie NuGeta. Jeśli więc masz modele w innym projekcie, musisz tam też pobrać ten pakiet.
W razor zmień DataAnnotationsValidator na ObjectGraphDataAnnotationsValidator
I to na tyle. Teraz wszystko już działa. ObjectGraphAnnotationsValidator sprawdzi walidacje wszystkich zwykłych pól, jak i tych „kompleksowych”.
Wbudowane kontrolki
Powiem jeszcze na koniec o kontrolkach formularzy wbudowanych w Blazor. Oczywiście możemy tworzyć własne jeśli będzie taka potrzeba (czasami jest), jednak do dyspozycji na starcie mamy:
InputText
InputCheckbox
InputDate
InputFile
InputNumber
InputRadio
InputRadioGroup
InputSelect
InputTextArea
To tyle, jeśli chodzi o podstawy walidacji w Blazor. Jeśli masz jakieś pytania lub znalazłeś błąd w artykule, podziel się w komentarzu.
Hej, w pierwszej części artykułu pisałem o podstawach Tag Helpers w Razor. Jeśli nie czytałeś tego, to koniecznie nadrób zaległości, bo inaczej ten artykuł może być niezrozumiały.
Dzisiaj polecimy dalej i wyżej. Opowiem Ci o bardziej zaawansowanych rzeczach, które możemy zrobić z tag helperami i stworzymy coś miłego dla oka. Dlatego, na Boga, przeczytaj pierwszą część artykułu.
Co robimy?
Chcemy stworzyć tag helper, który ułatwi nam korzystanie z bootstrapowych kart. Jeśli nie wiesz, czym jest bootstrap, to w dużym skrócie można powiedzieć, że jest to zestaw styli css (framework css) gotowych do użycia na Twojej stronie, które bardzo przyspieszają zarówno tworzenie layoutu, jak i samej strony. Ponadto bootstrap posiada kilka ciekawych komponentów w JS takich jak np. karuzela, czy też okno modalne.
My zajmiemy się dzisiaj kartami. Chcemy uzyskać taki efekt:
Nie jest to nic wybitnego, po prostu korzystamy z kart. Ten Bootstrapowy komponent jest dokładnie opisany tutaj.
Szybki opis karty
Pojedyncza karta wygląda tak:
Na górze mamy nagłówek, pod nim obrazek, dalej tytuł (Pieseł), podtytuł (Hau hau) i zawartość. Na dole jest stopka, a cała karta jest w ramce. Wyłaniają nam się już poszczególne elementy, więc zacznijmy pisanie właśnie od tagu helper’a dla pojedynczej karty.
Zaczynamy pisanie tag helper’a
Pojedyncza karta
Jak już wiesz, karta składa się z kilku elementów. W tym momencie pominiemy ramkę, bo będzie za nią odpowiadało coś innego. A więc mamy:
tekst nagłówka
obrazek
tytuł i podtytuł
treść
tekst stopki
Przygotujmy taki szkielet tag helper’a:
public class CardTagHelper: TagHelper
{
public string Header { get; set; } = string.Empty;
public string ImgSrc { get; set; } = string.Empty;
public string Title { get; set; } = string.Empty;
public string SubTitle { get; set; } = string.Empty;
public string Footer { get; set; } = string.Empty;
public override void Process(TagHelperContext context, TagHelperOutput output)
{
base.Process(context, output);
}
}
Póki co, nie ma tutaj niczego nadzwyczajnego. Zupełny szkielet tag helper’a z wymaganymi właściwościami. Zobaczmy, jak powinna wyglądać taka karta w HTML:
Jak widzisz, najpierw jest główny div, trzymający w ryzach całą kartę. Następnie jest div z nagłówkiem, obrazek, div z ciałem i na końcu stopka. Zacznijmy od tego pierwszego – głównego:
Nie ma tu niczego nowego, może poza metodą AddClass. To jest metoda helperowa, aby ją zobaczyć i użyć, musisz dodać using: Microsoft.AspNetCore.Mvc.TagHelpers. To jest po prostu pewne ułatwienie. Równie dobrze można by dodać klasy za pomocą atrybutów.
Teraz w razor (cshtml) użyjemy naszego helper’a. Wpisz po prostu:
<card></card>
Zobacz, jaki HTML został wyrenderowany:
<div class="card mb-3"></div>
Czyli można powiedzieć, że mamy już początek. Zanim pójdziemy dalej, muszę opowiedzieć Ci o 4 właściwościach z klasy TagHelperOutput, o których wcześniej nie mówiliśmy. Dla ułatwienia opowiem to łopatologicznie, niekoniecznie zgodnie z poprawnym nazewnictwem:
PreElement – to jest treść HTML, która będzie umieszczona zaraz przed Twoim tagiem
PreContent – to jest treść HTML, która będzie umieszczona w Twoim tagu, ale zaraz przed jego zawartością
PostContent – to jest treść HTML, która będzie umieszczona w Twoim tagu, po jego zawartości
PostElement – to jest treść HTML, która będzie umieszczona zaraz po Twoim tagu.
Aby to lepiej zobrazować, napiszmy sobie krótki kod. Najpierw tag helper (możesz użyć tego, nad którym aktualnie pracujemy):
Jak widzisz, możemy dowolnie sterować tym, co znajduje się zarówno przed tagiem, po nim, jak i w środku. Możemy tam dać dowolny i dowolnie długi kod HTML. I to właśnie wykorzystamy.
Nagłówek
Przypomnijmy sobie zatem na szybko kod bootstrap’a:
Mamy zrobionego pierwszego diva. Zróbmy teraz nagłówek i obrazek:
public class CardTagHelper: TagHelper
{
public string Header { get; set; } = string.Empty;
public string ImgSrc { get; set; } = string.Empty;
public string Title { get; set; } = string.Empty;
public string SubTitle { get; set; } = string.Empty;
public string Footer { get; set; } = string.Empty;
public override void Process(TagHelperContext context, TagHelperOutput output)
{
base.Process(context, output);
output.TagName = "div";
output.AddClass("card", HtmlEncoder.Default);
output.AddClass("mb-3", HtmlEncoder.Default);
output.PreContent.AppendHtml(RenderHeader());
output.PreContent.AppendHtml(RenderImg());
}
string RenderHeader()
{
return $"<div class=\"card-header\">{Header}</div>";
}
string RenderImg()
{
return $"<img class=\"card-img-top\" src=\"{ImgSrc}\" />";
}
}
Zobacz, zrobiłem przy okazji dwie metody renderujące odpowiedni kod HTML. Teraz lekko zmieńmy wywołanie tego tag helper’a w Razor. Trzeba po prostu dodać brakujące treści:
Super, powoli do przodu. Jeśli uruchomisz teraz program, zobaczysz wielką mordkę uśmiechniętego pieseła. Dodajmy teraz resztę – czyli treść karty i jej stopkę:
Metody RenderFooter nie ma co omawiać, natomiast zatrzymajmy się przy RenderBody. Jak widzisz wyprodukowaliśmy tu diva, a także tytuł i podtytuł karty. Czyli wszystko zgodnie z wzorcowym HTMLem. I teraz powinna pokazać się cała treść. A gdzie ona jest?
Spójrz jeszcze raz na metodę Process. Dodajemy kod „body” w PreContent. Następnie dodajemy diva zamykającego „body” w PostContent. Coś już świta? Spójrz teraz jak zmieniło się wywołanie tag helper’a w Razor:
<card header="Nagłówek" img-src="imgs/dog.jpg" footer="Stopka" title="Pieseł" sub-title="Hau hau">
<p class="card-text">Pieseł jaki jest, każdy widzi</p>
<a href="#" class="btn btn-primary">Guzik</a>
</card>
Co się okazuje? Że to, co damy między znacznikami początku i końca jest zawartością (Content) tag helpera! Nieźle. Uruchom teraz aplikację i zobacz kod wynikowy:
<div class="card mb-3">
<div class="card-header">Nagłówek</div>
<img class="card-img-top" src="imgs/dog.jpg">
<div class="card-body">
<h5 class="card-title">Pieseł</h5>
<h6 class="card-subtitle">Hau hau</h6>
<p class="card-text">Pieseł jaki jest, każdy widzi</p>
<a href="#" class="btn btn-primary">Guzik</a>
</div>
<div class="card-footer text-muted">Stopka</div>
</div>
Podświetlone linijki to właśnie te, które stanowią zawartość tag helper’a. Te 11 linijek kodu zamieniliśmy w 4 zdecydowanie prostsze! Hurra ja! Ale ale… Jeszcze nie pora na piwo. To dopiero pierwszy etap zadania.
Grupa kart
Skoro mamy już opracowaną kartę, zajmiemy się teraz grupą kart. Na początek zróbmy najprościej jak się da. Przypominam, jak w HTML wygląda taka grupa:
<div class="card-deck">
...
</div>
Klasa będzie na tyle prosta, że sam już powinieneś to napisać:
I to właściwie tyle. Zaskoczony? Popatrz teraz na Razor:
<card-group>
<card header="Nagłówek" img-src="imgs/cat.jpg" footer="Stopka" title="Koteł" sub-title="Miauuu">
<p class="card-text">Koteł jaki jest, każdy widzi</p>
<a href="#" class="btn btn-primary">Guzik</a>
</card>
<card header="Nagłówek" img-src="imgs/dog.jpg" footer="Stopka" title="Pieseł" sub-title="Hau hau">
<p class="card-text">Pieseł jaki jest, każdy widzi</p>
<a href="#" class="btn btn-primary">Guzik</a>
</card>
<card header="Nagłówek" img-src="imgs/pig.jpg" footer="Stopka" title="Świnieł" sub-title="Chrum chrum">
<p class="card-text">Chrumcia jaka jest, każdy widzi</p>
<a href="#" class="btn btn-primary">Guzik</a>
</card>
</card-group>
Dodajemy ramki
Czego jeszcze brakuje? Brakuje ramek. Ale ja chcę, żeby o istnieniu lub nieistnieniu ramki decydował card-group, a nie card. Jak to uzyskać? Z pomocą przychodzi pierwszy parametr metody Process – TagHelperContext.
TagHelperContext
To kontekst, który może być przekazywany między tag helperami. Ten kontekst będzie przekazany do metody Process (lub ProcessAsync) wszystkim tag helperom, które są w środku głównego TagHelpera.
Nie jest to wybitna klasa, ale ma jedną bardzo cenną właściwość: Items. Items to słownik, w którym zarówno kluczem i wartością jest object. Co znaczy, że możesz tam wrzucić dosłownie wszystko. Ten słownik posłuży do przekazywania danych między tag helperami. Stwórzmy sobie klasę o nazwie CardData:
class CardData
{
public bool ShowBorder { get; set; } = false;
}
Ta klasa przechowuje wartość, czy obramowanie ma być widoczne, czy nie. Uzupełnijmy teraz card-group o ten border:
public class CardGroupTagHelper: TagHelper
{
public bool ShowBorder { get; set; }
public override void Process(TagHelperContext context, TagHelperOutput output)
{
base.Process(context, output);
output.TagName = "div";
output.AddClass("card-deck", HtmlEncoder.Default);
CardData data = new CardData();
data.ShowBorder = ShowBorder;
context.Items[nameof(CardData)] = data;
}
}
Utworzyliśmy tu klasę CardData i przypisaliśmy jej właściwość ShowBorder. Następnie umieściliśmy utworzony obiekt w słowniku. Widziałem też kody, w których zamiast nameof(CardData) jako klucz, było typeof(CardData). Możesz sobie tam nawet wpisać „Słoń”. Dopóki wiesz jak odczytać te dane, nie ma to żadnego znaczenia. Jednak użycie nameof lub typeof wydaje się najbardziej racjonalne. Więc teraz dokończymy kod karty:
public override void Process(TagHelperContext context, TagHelperOutput output)
{
base.Process(context, output);
output.TagName = "div";
output.AddClass("card", HtmlEncoder.Default);
output.AddClass("mb-3", HtmlEncoder.Default);
CardData data = context.Items[nameof(CardData)] as CardData;
if (data.ShowBorder)
output.AddClass("border-primary", HtmlEncoder.Default);
output.PreContent.AppendHtml(RenderHeader());
output.PreContent.AppendHtml(RenderImg());
output.PreContent.AppendHtml(RenderBody());
output.PostContent.AppendHtml("</div>");
output.PostContent.AppendHtml(RenderFooter());
}
Pobraliśmy tutaj obiekt CardData stworzony w rodzicu tego tag helpera (card-group) i reszta jest już oczywista. To na tyle… Prawie…
Ograniczenia
Co się stanie, jeśli do card-group nie dodamy card, tylko coś innego? Np. jakiś obrazek? Być może nic złego, ale na pewno coś dziwnego. Nie chcemy takiej sytuacji. Chcemy się upewnić, że dziećmi card-group mogą być tylko elementy card. Z pomocą przychodzi…
RestrictChildren
To jest atrybut nakładany na głównego tag helpera. Powoduje, że jego dziećmi mogą być jedynie konkretne klasy, np:
[RestrictChildren("card")]
public class CardGroupTagHelper: TagHelper
{
//...
}
Spowoduje to, że dziećmi taga card-group mogą być jedynie tagi o nazwie card. Jeśli teraz w razor umieścisz taki kod:
<card-group show-border="true">
<mail>Mail</mail>
<card header="Nagłówek" img-src="imgs/cat.jpg" footer="Stopka" title="Koteł" sub-title="Miauuu">
<p class="card-text">Koteł jaki jest, każdy widzi</p>
<a href="#" class="btn btn-primary">Guzik</a>
</card>
</card-group>
to program się nie skompiluje i dostaniesz błąd: error RZ2010: The tag is not allowed by parent tag helper. Only child tags with name(s) 'card' are allowed.
Oczywiście ograniczenie nie dotyczy tylko tag helperów. Jeśli dasz tam jakiegoś diva (zamiast mail), img, czy cokolwiek innego, to program też się nie skompiluje.
Nie musimy się ograniczać do jednego typu dziecka. W końcu „wszystkie dzieci nasze są”. Możemy podać ich kilka, używając drugiego parametru atrybutu RestrictChildren:
[RestrictChildren("card", "img", "mail")]
public class CardGroupTagHelper: TagHelper
{
//...
}
Możemy podać tyle tagów, ile tylko chcemy.
Nic nie renderuj – czyli SupressOutput
Istnieje pewna metoda, która niejako niweczy całą pracę wykonaną przez TagHelpera. W klasie TagHelperOutput znajduje się SupressOutput. Ona po prostu powoduje brak wyświetlenia czegokolwiek w tym tagu. I tu pewnie zapytasz się – po co to komu? Czasem się to przydaje. Weźmy pod uwagę taki prosty kod:
class Data
{
public List<string> Children { get; set; } = new List<string>();
}
public class ParentTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
output.TagName = "div";
Data data = new Data();
context.Items[nameof(Data)] = data;
await output.GetChildContentAsync();
output.Attributes.SetAttribute("count", data.Children.Count);
string content = "";
foreach (var child in data.Children)
content += child + "<br />";
output.Content.SetHtmlContent(content);
}
}
public class ChildTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
TagHelperContent content = await output.GetChildContentAsync();
Data data = context.Items[nameof(Data)] as Data;
data.Children.Add(content.GetContent());
output.SuppressOutput();
}
}
Przeanalizujmy go. Najpierw deklarujemy klasę Data, która będzie przechowywać jakieś dane tagów. Następnie mamy tag helper’a – Parent. Spójrzmy co on robi:
zmienia swój tag na div
tworzy obiekt klasy Data
dodaje ten obiekt do kotekstu
i wreszcie wywołuje metodę GetChildContentAsync.
Metoda GetChildContentAsync() powoduje, że ruszają wszystkie tagi (metoda ProcessAsync()), będące dziećmi tego. Spójrzmy teraz na kod w ChildTagHelper, który właśnie w tym momencie zostanie wywołany:
tag helper pobiera swoją zawartość
pobiera obiekt data
na koniec dodaje swoją zawartość do listy
Wywołanie SupressOutput() spowoduje, że ten tag helper niczego nie wyświetli. Po prostu przekazał pewne dane do kontekstu i na tym zakończył swoją pracę.
Wróćmy teraz do ParentTagHelper. Gdy wszystkie dzieci wykonają swoją robotę, GetChildContentAsync się skończy i ParentTagHelper będzie kontynuował swoją pracę. W tym momencie odczyta z listy ilość dzieci i ustawi ją jako atrybut.
Następnie między wszystkie stringi (które pochodzą z dzieci) wstawi znacznik <br /> i wszystko to ustawi jako swoją zawartość.
Więc czasem ten SupressOutput jest przydatny. Nie tylko, żeby coś renderować warunkowo, ale też jeśli potrzebujesz mieć w Razor jakieś dzieci, ale tak naprawdę całą zawartością będzie z jakiegoś powodu sterował główny tag.
To na tyle, jeśli chodzi o TagHelpery w Razor. Mam nadzieję, że wszystko jest jasne. Jeśli jednak masz jakiś problem albo znalazłeś w artykule błąd, podziel się w komentarzu.
Pozwolisz, że w artykule będę posługiwał się anglojęzyczną nazwą „tag helper” zamiast „tag pomocniczy”, bo to po prostu brzmi jakby ktoś zajeżdżał tablicę paznokciem.
Czym jest tag helper?
Patrząc od strony Razor (niezależnie czy to RazorPages, czy RazorViews, robi się to identycznie), tag helper to nic innego jak tag w HTML. Ale nie byle jaki. Stworzony przez Ciebie. Kojarzysz z HTML tagi takie jak a, img, p, div itd? No więc tag helper od strony Razor to taki dokładnie tag, który sam napisałeś. Co więcej, tag helpery pozwalają na zmianę zachowania istniejących tagów (np. <a>). Innymi słowy, tag helpery pomagają w tworzeniu wyjściowego HTMLa po stronie serwera.
To jest nowsza i lepsza wersja HTML Helpers znanych jeszcze z czasów ASP.
Na co komu tag helper?
Porównaj te dwa kody z Razor:
<div>
@Html.Label("FirstName", "Imię:", new {@class="caption"})
</div>
Który Ci się bardziej podoba? caption-label to właśnie tag helper. Jego zadaniem jest właściwie to samo, co metody Label z klasy Html. Czyli odpowiednie wyrenderowanie kodu HTML. Jednak… no musisz się zgodzić, że kod z tag helperami wygląda duuuużo lepiej.
(tag helper caption-label nie istnieje; nazwa została zmyślona na potrzeby artykułu)
Tworzenie Tag Helper’ów
Tworzenie nowego projektu
Utwórz najpierw nowy projekt WebApplication w Visual Studio. Jeśli nie wiesz, jak to zrobić, przeczytaj ten artykuł.
Nowy Tag Helper
GitHub i NuGet są pełne customowych (kolejne nieprzetłumaczalne słowo) tag helperów. W samym .NetCore też jest ich całkiem sporo. Nic nie stoi na przeszkodzie, żebyś stworzył własny. Zacznijmy od bardzo prostego przykładu.
Stwórzmy tag helper, który wyśle maila po kliknięciu. Czyli wyrenderuje dokładnie taki kod HTML:
Przede wszystkim musisz zacząć od napisania klasy dziedziczącej po abstrakcyjnej klasie… TagHelper. Chociaż tak naprawdę mógłbyś po prostu napisać klasę implementującą interfejs ITagHelper. Jednak to Ci utrudni pewne rzeczy. Zatem dziedziczymy po klasie TagHelper:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
}
UWAGA! Nazwa Twojej klasy nie musi zawierać sufiksu TagHelper. Jednak jest to dobrą praktyką (tak samo jak tworzenie tag helperów w osobnym folderze TagHelpers lub projekcie). Stąd klasa nazywa się MailTagHelper, ale w kodzie HTML będziemy używać już tagu mail. Takie połączenie zachodzi automagicznie.
Super, teraz musimy zrobić coś, żeby nasz tag helper <mail> zamienił się na HTMLowy tag <a>. Służą do tego dwie metody:
Process – metoda, która zostanie wywołana SYNCHRONICZNIE, gdy serwer napotka na Twój tag helper
ProcessAsync – dokładnie tak jak wyżej, z tą różnicą, że to jest jej ASYNCHRONICZNA wersja
Wynika z tego, że musimy przesłonić albo jedną, albo drugą. Przesłanianie obu nie miałoby raczej sensu. Oczywiście będziemy posługiwać się asynchroniczną wersją, zatem przesłońmy tę metodę najprościej jak się da:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
}
}
Teraz zastanówmy się, jakie parametry chcemy przekazać do helpera. Ja tu widzę dwa:
adres e-mail odbiorcy
tytuł maila
Dodajmy więc te parametry do naszej klasy w formie właściwości:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public string Address { get; set; }
public string Subject { get; set; }
}
Rejestracja Tag Helper’ów
Rejestracja to w tym wypadku to bardzo duże słowo. Niemniej jednak, żeby nasz tag helper był w ogóle widoczny, musimy zrobić jeszcze jedną małą rzecz.
Odnajdź w projekcie plik _ViewImports.cshtml i zmień go tak:
Jeśli Twój tag helper znajduje się w innym namespace (np. umieściłeś go w katalogu TagHelpers), „zaimportuj” ten namespace na początku (moja aplikacja nazywa się WebApplication1): @using WebApplication1.TagHelpers
Następnie „zarejestruj” swoje tag helpery w projekcie, dodając na końcu pliku linijkę: @addTagHelper *, WebApplication1
Ostatecznie mój plik _ViewImports.cshtml wygląda tak:
A teraz małe wyjaśnienie. Nie musisz tego czytać, ale powinieneś.
Plik _ViewImports jest specjalnym plikiem w .NetCore. Wszystkie „usingi” tutaj umieszczone mają wpływ na cały Twój projekt. To znaczy, że usingi z tego pliku będą w pewien sposób „automatycznie” dodawane do każdego Twojego pliku cshtml.
To znaczy, że jeśli tu je umieścisz, to nie musisz już tego robić w innych plikach cshtml. Oczywiście nigdy nie rób tego „na pałę”, bo posiadanie 100 nieużywanych usingów w jakimś pliku jeszcze nigdy nikomu niczego dobrego nie przyniosło 🙂
Zatem w tej linijce @using WebApplication1.TagHelpers powiedziałeś: „Chcę używać namespace’a WebApplication1.TagHelpers na wszystkich stronach w tym projekcie”.
A co do @addTagHelper. To jest właśnie ta „rejestracja” tag helpera. Zwróć najpierw uwagę na to, co dostałeś domyślnie od kreatora projektu: @addTagHelper *, Microsoft.AspNetCore.Mvc.TagHelpers. Zarejestrował on wszystkie domyślne tag helpery.
A teraz spójrz na tę linijkę, którą napisaliśmy: @addTagHelper *, WebApplication1. Jeśli coś Ci tu nie pasuje, to gratuluję spostrzegawczości. A jeśli masz pewność, że to jest ok, to gratuluję wiedzy 🙂
Można łatwo odnieść wrażenie, że rejestrujesz tutaj wszystkie (*) tag helpery z namespace WebApplication1. Jednak @addTagHelper wymaga podania nazwy projektu, a nie namespace’a. Akurat Bill tak chciał, że domyślne tag helpery znajdują się w projekcie o nazwie Microsoft.AspNetCore.Mvc.TagHelpers. Nasz projekt (a przynajmniej mój) nazywa się WebApplication1.
Przypominam i postaraj się zapamiętać:
Klauzula @addTagHelper wymaga podania nazwy projektu, w którym znajdują się tag helpery, a nie namespace’a.
Pierwsze użycie tag helper’a
OK, skoro już tyle popisaliśmy, to teraz użyjemy naszego tag helpera. On jeszcze w zasadzie niczego nie robi, ale jest piękny, czyż nie?
Przejdź do pliku Index.cshtml i dodaj tam naszego tag helpera. Zanim to jednak zrobisz, zbuduj projekt. Może to być konieczne, żeby VisualStudio wszystko zobaczył i zaktualizował Intellisense.
Specjalnie użyłem obrazka zamiast kodu, żeby Ci pokazać, jak Visual Studio rozpoznaje tag helpery. Pokazuje je na zielono (to zielony, prawda?) i lekko pogrubia. Jeśli u siebie też to widzisz, to znaczy, że wszystko zrobiłeś dobrze.
OK, to teraz możesz postawić breakpointa w metodzie ProcessAsync i uruchomić projekt.
Jeśli breakpoint zadziałał, to wszystko jest ok. Jeśli nie, coś musiało pójść nie tak. Upewnij się, że używasz odpowiedniego namespace i nazwy projektu w pliku _ViewImports.cshtml.
Niech się stanie anchor!
OK, mamy taki kod w tag helperze:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public string Address { get; set; }
public string Subject { get; set; }
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
}
}
Teraz trzeba coś zrobić, żeby zadziałała magia.
Popatrz co masz w parametrze metody ProcessAsync. Masz tam jakiś output. Jak już mówiłem wcześniej, tag helper RENDERUJE odpowiedni kod HTML. Za ten rendering jest odpowiedzialny właśnie parametr output. Spróbujmy go wreszcie wykorzystać. Spójrz na kod metody poniżej:
TagHelperOutput ma taką właściwość jak TagName. Ta właściwość mówi dokładnie: „Jaki tag html ma mieć Twój tag helper?”. Uruchom teraz aplikację i podejrzyj wygenerowany kod html:
<a>Test</a>
Twój tag <mail> zmienił się na <a>.
I o to mniej więcej chodzi w tych helperach. Ale teraz dodajmy resztę rzeczy. Musimy jakoś dodać atrybut href. Robi się to bardzo prosto:
Jak widzisz wszystko załatwiliśmy outputem. Myślę, że ta linijka sama się tłumaczy. Po prostu dodajesz atrybut o nazwie href i wartości mailto:.... itd. Uruchom teraz aplikację i popatrz na magię.
Wszystko byłoby ok, gdybyśmy gdzieś przekazali te parametry Address i Subject. Przekażemy je oczywiście w pliku cshtml:
Zwróć tylko uwagę, że wg konwencji klasy w C# nazywamy tzw. PascalCase. Natomiast w tag helperach używasz już tylko małych liter. Tak to zostało zrobione. Jeśli masz kilka wyrazów w nazwie klasy, np. ContentLabelTagHelper, w pliku cshtml te wyrazy oddzielasz myślnikiem: <content-label>. Dotyczy to również atrybutów.
Oczywiście możesz z takim tag helperem zrobić wszystko. Np. zapisać na sztywno mail i temat, np:
Przeanalizuj ten kod. Po prostu, jeśli nie podasz adresu e-mail lub tematu wiadomości, zostaną one wzięte z wartości domyślnych. Oczywiście te wartości domyślne mogą być wszędzie. W stałych – jak tutaj – w bazie danych, w pliku… I teraz wystarczy, że w pliku cshtml napiszesz:
<mail>Test</mail>
Fajnie? Dla mnie bomba!
Atrybuty dla Tag Helper
Tag helpery mogą zawierać pewne atrybuty, które nieco zmieniają ich działanie:
HtmlTargetElement
Możemy tu określić nazwę taga, jaką będziemy używać w cshtml, rodzica dla tego taga, a także jego strukturę, np:
[HtmlTargetElement("email")]
public class MailTagHelper: TagHelper
{
}
Od tej pory w kodzie cshtml nie będziemy się już posługiwać tagiem <mail>, tylko <email>. Możemy też podać nazwę tagu rodzica, ale o tym w drugiej części artykułu. Możemy też określić strukturę tagu. Może on wymagać tagu zamknięcia (domyślnie) lub być bez niego, np:
[HtmlTargetElement("email", TagStructure = TagStructure.NormalOrSelfClosing)]
public class MailTagHelper: TagHelper
{
}
W przypadku tak skonstruowanego tagu email nie ma to sensu, ale moglibyśmy to przeprojektować i wtedy tag można zapisać tak: <email text="Napisz do mnie" /> lub tak: <email text="Napisz do mnie"></email>
TagStructure może mieć takie wartości:
TagStructure.NormalOrSelfClosing – tag z tagiem zamknięcia, bądź samozamykający się – jak widziałeś wyżej. Czyli możesz napisać zarówno tak: <mail address="a@b.c"></mail> jak i tak: <mail address="a@b.c" />
TagStructure.Unspecified – jeśli żaden inny tag helper nie odnosi się do tego elementu, używana jest wartość NormalOrSelfClosing
TagStructure.WithoutEndTag – niekonieczny jest tag zamknięcia. Możesz napisać tak: <mail address="a@b.c"> jak i tak: <mail address="a@b.c" />
HtmlTargetElement ma jeszcze jeden ciekawy parametr służący do ustalenia dodatkowych kryteriów. Spójrz na ten kod:
[HtmlTargetElement("email", Attributes = "send")]
public class MailTagHelper: TagHelper
{
//tutaj bez zmian
}
Aby teraz taki tag helper został dobrze dopasowany, musi być wywołany z atrybutem send:
<email send>Napisz do mnie</email>
Ten kod zadziała i tag zostanie uruchomiony. Ale taki kod już nie zadziała:
<email>Napisz do mnie</email>
Ponieważ ten tag nie ma atrybutu send.
Przy pisaniu własnych tagów raczej nie ma to zbyt wiele sensu, ale popatrz na coś takiego:
<p red>UWAGA! Oni nadchodzą!</p>
I tag helper do tego:
[HtmlTargetElement("p", Attributes = "red")]
public class PRedTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
output.Attributes.Add("style", "color: red");
}
}
Teraz każdy tekst w paragrafie z atrybutem red będzie napisany czerwonym kolorem. To daje nam naprawdę ogromne możliwości.
HtmlAttributeNotBound
Do tej pory widziałeś, że wszystkie właściwości publiczne tag helpera mogą być używane w plikach cshtml. No więc nadchodzi atrybut, który to zmienia. HtmlAttributeNotBound niejako ukrywa publiczną właściwość dla cshtml.
Stosujemy to, gdy jakaś właściwość (atrybut) nie ma sensu od strony HTML lub jest niepożądana, ale z jakiegoś powodu musi być publiczna. Spójrz na ten kod:
public class MailTagHelper: TagHelper
{
[HtmlAttributeNotBound]
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Teraz właściwość Address nie będzie widoczna w cshtml. Oczywiście tego atrybutu używamy na właściwościach, a nie na klasie.
HtmlAttributeName
Ten atrybut z kolei umożliwia zmianę nazwy właściwości tag helpera w cshtml. Nadpisuje nazwę atrybutu:
public class MailTagHelper: TagHelper
{
[HtmlAttributeName("Tralala")]
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Teraz w pliku cshtml możesz napisać tak:
<email tralala="a@b.c" />
Ale ten atrybut ma jeszcze jedno przeciążenie i potrafi ostro zagrać. Może zwali Cię to z nóg. Dzięki niemu możesz w pliku cshtml napisać co Ci się podoba, a Twój tag helper to ogarnie. Możesz popisać atrybuty, które nie są właściwościami Twojego tag helpera! Spójrz na ten przykład:
public class MailTagHelper: TagHelper
{
[HtmlAttributeName(DictionaryAttributePrefix = "mb_")]
public Dictionary<string, string> Prompts { get; set; } = new Dictionary<string, string>();
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Co tu zaszło? Spójrz, co podałeś w parametrze atrybutu HtmlAttributeName. Jest to jakiś prefix. A teraz zauważ, że w kodzie html użyłeś tego prefixu do określenia nowych atrybutów.
Po takiej zabawie, słownik Prompts będzie wyglądał tak:
adr: „a@b.c”
subject: „Temat”
Zauważ, że prefix został w słowniku automatycznie obcięty i trafiły do niego już konkretne atrybuty.
Oczywiście to przeciążenie może być użyte tylko na właściwości, która implementuje IDictionary. Kluczem musi być string, natomiast wartością może być string, int itd.
To tyle, jeśli chodzi o podstawy tworzenia tag helperów. O bardziej zaawansowanych możliwościach mówię w drugiej części artykułu. Najpierw upewnij się, że dobrze zrozumiałeś wszystko co tu zawarte.
Jeśli masz jakiś problem albo znalazłeś w artykule błąd, podziel się w komentarzu.
Hej, w tym artykule pokażę Ci, czym jest szablon potomny w WordPress (child theme), jak i po co go stosować. Rozsiądź się wygodnie i zaczynamy.
Po co szablon potomny?
Prędzej, czy później dojdzie do tego, że będziesz chciał zrobić jakąś zmianę w szablonie – czy to w pliku php, czy css, a może jeszcze gdzieś indziej. To może być mała, ale kluczowa zmiana. Jeśli nie zastosowałbyś szablonu potomnego, to mogłoby się okazać, że po aktualizacji szablonu, który używasz, straciłeś swoje zmiany. No i klops, no i cześć.
Dlatego istotne jest, aby stosować szablony potomne. Dzięki nim, raczej nigdy nie powinieneś stracić swoich zmian (pomijając jakieś duże lub źle zrobione aktualizacje).
Czym jest szablon potomny?
W WordPress są dwa rodzaje szablonów – szablon rodzic (parent theme) i szablon potomny (child theme). Instalując szablon na swoim WordPressie, instalujesz szablon typu rodzic – czyli główny szablon. On może być całkowicie zmieniony podczas aktualizacji.
Szablon potomny to szablon, który tworzysz niejako na podstawie szablonu rodzica. I to właśnie szablonów potomnych powinieneś używać. NIGDY nie używaj szablonu, który instalujesz, za każdym razem utwórz szablon potomny i ten właśnie używaj.
Jak stworzyć szablon potomny?
Na szczęście jest to niesamowicie proste.
Zainstaluj szablon, który chcesz używać, ale nie wybieraj go w ustawieniach WordPress. U mnie to Divi, który szczególnie polecam.
Teraz musisz uruchomić jakąś przeglądarkę plików. Może to być Windows Explorer (jeśli Twoja strona istnieje tylko lokalnie), Total Commander lub jakakolwiek inna przeglądarka (klient FTP)
W katalogu głównym bloga masz katalog wp-content. Przejdź do niego
W nim masz katalog themes. Przejdź tam.
W katalogu themes masz katalogi zainstalowanych szablonów. Utwórz tutaj nowy katalog z nazwą istniejącego szablonu i dopiskiem -child. Tzn. jeśli np. chcesz używać szablonu TwentyTwenty, utwórz katalog TwentyTwenty-child (oczywiście katalog TwentyTwenty musi tutaj istnieć – ponieważ zainstalowałeś ten szablon)
W nowo utworzonym katalogu (z sufiksem -child) utwórz plik style.css. To jest główna część Twojego szablonu potomnego. Do tego pliku dodaj taką zawartość:
/*
Theme Name: Nazwa szablonu (np. TwentyTwenty Child)
Theme URI: strona szablonu (np. http://twenty-twenty.com)
Description: Opis Twojego szablonu (np: Szablon potomny TwentyTwenty)
Author: Ja
Author URI: strona autora
Template: TwentyTwenty (wpisz tutaj nazwę szablonu rodzica)
Version: 1.0.0
*/
Mimo, że powyższy kod jest w komentarzu, to jednak jest on istotny. Krótkie wyjaśnienie:
Theme Name – nazwa szablonu, który będzie wyświetlony w menu WordPressa. Nazwa musi być unikalna. Ta wartość jest wymagana
Theme URI – strona szablonu, możesz pominąć
Description – opis szablonu, możesz pominąć
Author – autor szablonu – możesz pominąć
Author URI – strona autora szablonu – możesz pominąć
Template – szablon rodzic dla tego szablonu. Ta wartość jest wymagana
Version – wersja, możesz pominąć.
Jest jeszcze kilka samoopisujących się elementów, które możesz tutaj zawrzeć, ale raczej nie będziesz ich stosował (License – nazwa licencji (np. GNU); License URI – strona z licencją; Tags – tagi szablonu; Text Domain – szczerze, nie mam pojęcia co to. Jeśli wiesz, podziel się w komentarzu)
Kolejkowanie styli szablonów
To właściwie tyle. Utworzyłeś szablon potomny. W pliku style.css możesz dalej robić modyfikacje swojego szablonu. Jest jednak jeszcze jedna rzecz, którą powinieneś zrobić. Powinieneś skolejkować style.css szablonu rodzica i potomnego. Kiedyś robiło się to inaczej (dyrektywa @import w pliku style.css). Ale dzisiaj zalecany jest sposób z wykorzystaniem php.
W świecie idealnym szablon rodzica powinien zaczytać zarówno swoje style, jak i style szablonu potomnego. Jednak nie zawsze to się dzieje. Dlatego powinieneś zrobić to ręcznie:
Utwórz w katalogu szablonu potomnego jeszcze jeden plik: functions.php
Ten kod po prostu rejestruje i kolejkuje arkusze styli. Teraz jest ważne kilka rzeczy:
szablon potomny jest wczytywany przed szablonem rodzicem
jeśli nie podasz numeru wersji w pliku style.css, odwiedzający zobaczą to, co zostało zapisane w cache, a nie aktualną wersję. Dlatego po każdej zmianie zmień też numer wersji
funkcje get_stylesheet* szukają najpierw elementów w szablonach potomnych
Teraz już możesz aktywować ten styl potomny w opcjach wyglądu WordPressa.
Jeśli znalazłeś błąd w artykule, masz jakieś pytania lub chcesz coś dodać, podziel się w komentarzu
Obsługujemy pliki cookies. Jeśli uważasz, że to jest ok, po prostu kliknij "Akceptuj wszystko". Możesz też wybrać, jakie chcesz ciasteczka, klikając "Ustawienia".
Przeczytaj naszą politykę cookie