W pewnym momencie powstał (a właściwie „został odkryty”) typ Span<T>. Nagle Microsoft zaczął go wszędzie używać, twierdząc że jest zajebisty. No dobra, ale czym tak naprawdę jest ten Span? I czy faktycznie jest taki zajebisty? Zobaczmy.
Jedno jest pewne. Używasz go, być może nawet o tym nie wiedząc (jest rozlany wszędzie we Frameworku).
Czym jest Span<T>?
Żeby była jasność. Span to NIE JEST kontener.
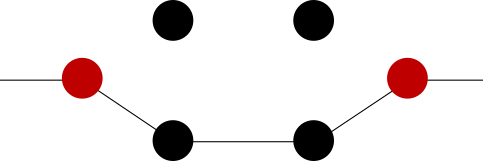
W zasadzie Span<T> to takie oczko, które gapi się na przekazany fragment pamięci:
I właściwie mógłbym na tym artykuł skończyć, bo obrazek powyżej idealnie oddaje sens i działanie Spanu. Ale ok, jeśli chcesz więcej, to czytaj dalej 🙂
Przede wszystkim musisz zrozumieć różnice między stosem i stertą. Jeśli nie jesteś pewien, koniecznie przeczytaj ten artykuł, w którym nieco nakreślam sytuację.
Span jako wskaźnik
Span<T> jest w pewnym sensie wskaźnikiem w świecie zarządzanym. Wskazuje na pewien obszar pamięci na stercie (zarządzanej i niezarządzanej). Ale może też wskazywać na pamięć na stosie. Pamiętaj, że jako wskaźnik, sam Span jest alokowany na stosie i zasadniczo składa się z dwóch elementów:
adresu miejsca, na który wskazuje
wielkości tego miejsca
Można by powiedzieć, że Span<T> wygląda mniej więcej tak:
public readonly ref struct Span<T>
{
private readonly ref T _pointer;
private readonly int _length;
}
Tak, mniej więcej taka jest zawartość spanu (+ do tego kilka prostych metod i rozszerzeń). Z tego wynika pierwsza rzecz:
Span jest niemutowalny (immutable) – raz utworzonego Spanu nie można zmienić. Tzn., że raz utworzony Span zawsze będzie wskazywał na to samo miejsce w pamięci.
W pamięci może to wyglądać mniej więcej tak:
Na stosie mamy dwie wartości, które składają się na Span. Pointer, jak to pointer, wskazuje na jakiś obszar w pamięci na stercie, natomiast length posiada wielkość tego obszaru. A co to za obszar? Ten, który wskażesz przy tworzeniu Spana.
Uniwersalność tworzenia
Utworzyć Spana możemy właściwie ze wszystkiego. Z tablicy, z listy, z Enumerable, a nawet ze zwykłego niskopoziomowego wskaźnika. To jest jego główna moc i jeden z powodów jego powstania.
I, powtarzam – Span to NIE JEST żadna kolekcja. To NIE JEST tablica. Span nie służy do przechowywania danych, tylko pokazuje Ci fragment pamięci z tymi danymi, które zostały zaalokowane gdzieś wcześniej.
A po co to?
Wyobraź sobie teraz, że masz listę intów, której elementy chcesz zsumować. Możesz przecież zrobić coś takiego:
static void Main(string[] args)
{
List<int> list = [1, 2, 3];
var value = Sum(list);
}
private static int Sum(List<int> source)
{
var sum = 0;
foreach (var item in source)
{
sum += item;
}
return sum;
}
I to zadziała super. Masz metodę, która sumuje jakieś dane.
Ok, a teraz załóżmy, że w pewnym momencie ktoś zamiast listy chce dać Ci tablicę. I czym to się kończy? Czymś takim:
static void Main(string[] args)
{
int[] arr = [1, 2, 3];
var value = Sum(arr.ToList());
}
private static int Sum(List<int> source)
{
var sum = 0;
foreach (var item in source)
{
sum += item;
}
return sum;
}
Czy to jest w porządku?
Spójrz co się dzieje w linii 4. TWORZYSZ listę. W sensie dosłownym – tworzysz zupełnie nowy obiekt (wywołując ToList()). Wszystkie wartości tablicy są kopiowane i jest tworzona nowa lista, która będzie obserwowana przez Garbage Collector na stercie zarządzanej.
Czyli masz już dwa obiekty obserwowane na tej stercie – tablicę i listę. Pamiętaj, że tworzenie obiektów na stercie jest stosunkowo kosztowne. Poza tym, gdy pracuje Garbage Collector, Twoja aplikacja NIE pracuje, tylko czeka.
I teraz z pomocą przychodzi Span:
static void Main(string[] args)
{
int[] arr = [1, 2, 3];
var span = new Span<int>(arr);
var value = Sum(span);
}
private static int Sum(Span<int> source)
{
var sum = 0;
foreach (var item in source)
{
sum += item;
}
return sum;
}
Co się dzieje w tym kodzie? Przede wszystkim zwróć uwagę, że metoda Sum w ogóle się nie zmieniła (poza typem argumentu, który przyjmuje). Span daje Ci możliwość iterowania bez żadnych przeszkód.
To, co zostało zmienione, to zamiast Listy na stercie, utworzony został Span. A gdzie? Na STOSIE! Ponieważ, jak pisałem na początku – Span to STRUKTURA i jako taka jest tworzona na stosie. Nie ma też narzutu związanego z kopiowaniem danych i tworzeniem obiektu na stercie.
Dlaczego nie ma narzutu związanego z kopiowaniem danych? Bo nic nie jest kopiowane – powtarzam – Span to wskaźnik – on wskazuje na obszar zajmowany przez dane w tablicy arr. I to jest też mega ważne – wskazuje na konkretne dane, a nie na cały obiekt. Innymi słowy, wskazuje na miejsce arr[0]. I to jest właśnie druga główna supermoc Spana (tak samo wskaże na początek danych listy itd).
Porównanie
Zróbmy sobie teraz małe porównanie. Span idealnie działa ze stringami, gdzie widać jego moc już na pierwszy rzut oka. Więc napiszmy sobie prostą apkę, która zwróci ze stringa jakieś obiekty. String będzie w tej postaci:
string data = "firstname=John;lastname=Smith";
Stwórzmy też wynikową klasę:
class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
Aby wykonać to zadanie bez użycia Spana, napisalibyśmy kod mniej więcej taki:
private static Person ProcessDataUsingString(string data)
{
var values = data.Split(";"); //alokacja dwóch nowych stringów i tablicy
var firstName = values[0].Substring(values[0].IndexOf('=') + 1); //alokacja nowego stringu
var lastName = values[1].Substring(values[1].IndexOf('=') + 1); //alokacja nowego stringu
return new Person
{
FirstName = firstName,
LastName = lastName
};
}
Natomiast ze Spanem mogłoby to wyglądać tak:
private static Person ProcessDataUsingSpan(string data)
{
var span = data.AsSpan();
var fNameValues = span.Slice(0, span.IndexOf(';'));
var lNameValues = span.Slice(span.IndexOf(';') + 1);
var firstName = fNameValues.Slice(fNameValues.IndexOf('=') + 1);
var lastName = lNameValues.Slice(lNameValues.IndexOf('=') + 1);
return new Person
{
FirstName = firstName.ToString(), //alokacja nowego stringu
LastName = lastName.ToString() //alokacja nowego stringu
};
}
Zrobiłem Benchmark dla jednego takiego rekordu:
Method
Mean
Error
StdDev
Ratio
Gen0
Allocated
Alloc Ratio
ProcessWithString
48.81 ns
0.231 ns
0.193 ns
1.00
0.0421
264 B
1.00
ProcessWithSpan
26.69 ns
0.534 ns
0.525 ns
0.55
0.0179
112 B
0.42
Jak widać Span jest zdecydowanie bardziej wydajny. Nie tylko pod względem czasu wykonania, ale i alokacji pamięci. Właściwie jedyne alokacje, jakie się tu odbyły są już podczas tworzenia nowego obiektu Person – gdy przypisywane są konkretne nowe stringi do obiektu.
Span tylko do odczytu
Zwykły Span pozwala na zmianę konkretnych danych w pamięci. A jeśli jednak chciałbyś użyć jego bezpieczniejszej wersji, to możesz ReadOnlySpan. Działa dokładnie tak samo, tylko nie umożliwia zmiany danych.
I ta właśnie wersja jest zwracana przez stringa – czyli wciąż nie możesz zmienić raz utworzonego stringa (bez użycia kodu unsafe i niskopoziomowych wskaźników).
Możesz mieć tu teraz mały mindfuck – jak to span jest niemutowalny, ale można zmienić mu dane?
Span jest niemutowalny pod tym względem, że raz utworzony zawsze będzie wskazywał na ten sam fragment pamięci. Ale to, co jest w tej pamięci możesz zmienić (chyba że masz ReadOnlySpan). Zobaczysz to dalej w artykule.
Na co nie pozwala?
Nie można zmienić stringu
Jak już pisałem, Span nie pozwala na zmianę elementów stringu. String jest zawsze niemutowalny i nic na to nie poradzisz (poza niskopoziomowymi wskaźnikami).
Nie może być częścią klasy
Z tego powodu, że Span MUSI BYĆ alokowany na stosie, nie może być elementem klasy. W sensie właściwością, czy polem. Elementy klasy mogą być alokowane na stercie, a Span nie może, bo ma to zabronione. Za to Span może być częścią ref struct. Ale w takiej sytuacji musisz uważać.
Musisz używać go mądrze
Pamiętasz jak pisałem, że raz utworzony Span zawsze będzie wskazywał dokładnie to samo miejce w pamięci? Musisz wiedzieć, co masz w tym miejscu, żeby nie doszło do wykrzaczenia:
byte[] arr = [1, 2, 3];
var span = new Span<byte>(arr);
arr = null!;
GC.Collect();
span[0] = 10;
Spójrz, najpierw alokujemy pamięć na tablicę. Na stosie znajduje się adres do elementów tej tablicy (czyli zmienna arr). Tworzymy sobie Span dla tej tablicy – Span teraz wskazuje na elementy tablicy na stercie.
Następnie usuwamy naszą tablicę – w efekcie nic tego miejsca już nie używa. Garbage Collector w pewnym momencie może je wyczyścić albo mogą zostać tam zaalokowane inne rzeczy. Natomiast Span cały czas wskazuje na tę pamięć. I przypisując jakąś wartość możesz doprowadzić do Access Violation.
Więc pod tym względem musisz być uważny.
Nie możesz go używać w asynchronicznych operacjach
Jako, że każdy wątek ma swój oddzielny stos, a Stack jest alokowany na stosie, to nie może być używany w operacjach asynchronicznych. Jeśli potrzebujesz czegoś takiego, użyj Memory<T>. O tym może też coś napiszę.
Czy Span jest zajebisty?
To w sumie tylko narzędzie. Odpowiednio użyte może sprawdzić, że aplikacje w C# będą naprawdę wydajne. Niemniej jednak cieszę się, że coś takiego powstało, ponieważ to jest jedna z rzeczy, których brakowało mi trochę, a które używałem w innych językach. Czyli wskaźniki. I to bez użycia kodu unsafe 🙂
Dzięki za przeczytanie artykułu. Jeśli czegoś nie rozumiesz lub znalazłeś jakiś błąd, koniecznie daj znać w komentarzu 🙂
W tym artykule wyjaśnię Ci, kiedy używać klasy, a kiedy struktury w C#. Granica czasem wydaje się bardzo rozmyta, ale są pewne zasady, które pomagają wybrać tę „lepszą” w danej sytuacji drogę. Zazwyczaj jednak jest to klasa.
Żeby lepiej zrozumieć różnice między nimi, muszę Cię zapoznać z takimi pojęciami jak stos, sterta, typ referencyjny i typ wartościowy. Jeśli znasz dobrze te zagadnienia, możesz przejść od razu na koniec artykułu.
Obszary w pamięci – stos i sterta
Pamięć programu jest zazwyczaj dzielona na stos i stertę. Wyobraź sobie to dokładnie w taki sposób. Możesz mieć w kuchni stos talerzy (jeden na drugim), a w pokoju stertę pierdół (rzeczy rozsypane w nieładzie wszędzie). Każdy z tych obszarów jest przeznaczony do różnych zastosowań.
Stos
Stos (ang. stack) przechowuje zmienne lokalne, parametry metody i wartości zwracane – generalnie dane krótko żyjące. To jest pewne uproszczenie, ale na potrzeby tego artykułu przyjmijmy to za pewnik.
Pamięć na stosie jest zarządzana automatycznie przez system operacyjny. Jest też mocno ograniczona (w zależności od tego systemu). Dlatego też, jeśli próbujesz na stosie umieścić zbyt wiele danych, dostaniesz błąd „przepełnienie stosu” (stack overflow). Z tego wynika, że możesz mieć ograniczoną ilość zmiennych lokalnych, czy też parametrów metody. Jednak w dzisiejszych czasach ten błąd sugeruje problem z rekurencją (czego wynikiem jest właśnie przepełnienie stosu).
Dane ze stosu są ściągane po wyjściu z jakiegoś zakresu – np. po wyjściu z metody lub jakiegoś bloku. No i wkładane są na stos podczas wchodzenia do bloku (metody).
Sterta
Sterta (ang. heap) jest dynamicznym obszarem pamięci. Nie ma takich limitów jak stos. Sam możesz decydować ile chcesz pamięci zarezerwować na stercie i co tam przechowywać. W językach bez pamięci zarządzalnej (C, C++, Delphi) sam musisz też troszczyć się o to, żeby usuwać dane ze sterty w odpowiednim momencie. W C# troszczy się o to zazwyczaj Garbage Collector (w specyficznych rozwiązaniach też programista musi się tym zająć).
Sterta jest przeznaczona do przechowywania danych długożyjących. A także takich, których rozmiar nie jest znany w momencie kompilacji programu.
Typ referencyjny i wartościowy
W C# mamy dwa rodzaje typów – referencyjne i wartościowe. Wszystkie typy proste (int, double, float, bool itd.) oraz struktury są typami wartościowymi. Typy referencyjne to klasy lub… referencje. Ale o tych drugich nie będziemy za bardzo tutaj mówić 🙂
Czyli podsumowując: klasy – typy referencyjne; struktury i typy proste – typy wartościowe (pamiętaj, że string nie jest typem prostym. Jego wartość jest przechowywana na stercie).
To rozróżnienie sprowadza się do kilku rzeczy.:
Struktury (typy wartościowe)
Przechowywane są w pamięci na stosie (to pewne uproszczenie, ale na razie potraktuj je za pewnik)
Automatycznie tworzone i zwalniane przez system operacyjny
Klasy (typy referencyjne)
Przechowywane w pamięci na stercie
Programista sam musi utworzyć obiekt takiego typu
Typ referencyjny jest zwalniany przez Garbage Collector (w C# programista bardzo rzadko musi taki typ sam zwolnić)
Ubrudźmy sobie ręce
Teraz z użyciem debuggera pokażę Ci dokładnie jak to wygląda od praktycznej strony w pamięci.
Spójrz na poniższy kod:
static void Main(string[] args)
{
int number = 5;
}
Na początku tworzymy zmienną typu int. A właściwie robi to za nas system operacyjny. To jest zmienna lokalna, a więc jest tworzona automatycznie na stosie. Co to oznacza? Że w momencie wejścia do metody Main system tworzy stos dla tego bloku* i dodaje do niego wszystkie zmienne lokalne i parametry metody. Stos w tym momencie wygląda tak:
A tak to widać w debugerze:
*Dla czepialskich, dociekliwych i maruderów
Stos nie jest tak naprawdę tworzony za każdym razem – to skrót myślowy. Istnieje pojęcie ramki stosu (stack frame). Ramka stosu to fragment pamięci wydzielony jako… „stos” dla danej metody, czy zakresu. Po wejściu/wyjściu z tej metody zmienia się aktualna ramka stosu na inną (a konkretnie rejestr procesora *SP wskazuje na inny obszar w pamięci jako początek stosu). Na stosie jest oczywiście więcej informacji niż te tutaj pokazane (m.in. parametr args), ale zostały pominięte ze względu na czytelność i nie mają związku z artykułem.
Jeśli nie wiesz, co tu widzisz, to już tłumaczę.
W górnym okienku jest uruchomiony program w trybie debugowania. W dolnym widzimy podgląd fragmentu pamięci programu. Zmienna number dostała konkretny adres w pamięci: 0x000000C4F657E52C. Jak widzisz, pod tym adresem znajdują się jakieś dane: 05 00 00 00. Te 4 bajty mają wartość 5. Widzimy też, że żeby zapisać zmienną typu int, potrzebujemy do tego 4 bajtów.
A teraz co się stanie, jeśli będziemy mieć dwie zmienne lokalne?
static void Main(string[] args)
{
int number = 5;
int score = 1;
}
Stos będzie wyglądał tak:
A w debugerze zobaczymy:
Jak widać z rysunku i debugera, stos rośnie „w górę”. Są na nim odkładane poszczególne wartości.
A jeśli teraz dodamy do tego strukturę?
struct Point3d
{
public int x;
public int y;
public int z;
}
internal class Program
{
static void Main(string[] args)
{
int number = 5;
int score = 1;
Point3d point;
point.x = 2;
point.y = 3;
point.z = 4;
}
}
Teraz stos wygląda tak:
Robi się gęsto. Na wierzchu stosu mamy wszystkie składowe struktury – x, y i z. Potem jakiś pusty element – tutaj oznaczony na niebiesko, a potem to co już było – zmienne score i number.
Z tego obrazka wynika kilka rzeczy:
Nie musisz tworzyć struktury przez new, bo skoro jest ona tworzona na stosie, to tworzy ją tam system operacyjny automatycznie – a o tym pisałem wcześniej – dane na stosie są tworzone automatycznie przez system operacyjny.
Struktura jest niczym innym jak workiem na dane.
Czym jest ten pusty, niebieski element? Padding – tylko dla dociekliwych
Spójrz na cztery ostatnie „niebieskie” bajty struktury: 00 00 00 00. Co reprezentują? Zupełnie nic. To jest tzw. padding. Padding to mechanizm, który polega na dopełnieniu wielkości struktury do „naturalnej” wielkości adresowej. Czyli wielokrotności 4 (32 bitowy system) lub 8 (64 bitowy system) bajtów. To znaczy, że domyślnie wielkość wszystkich struktur jest podzielna przez 4 lub 8. Padding niekoniecznie występuje na końcu struktury. Będzie raczej występował po konkretnych jej elementach. Np. strukturę:
struct MyStruct
{
public bool b;
public int i;
}
gdzieś tam na niskim pozimie zapisalibyśmy tak:
struct MyStruct
{
public bool b;
byte[3] _padding_b;
public int i;
}
To nie jest domena C#, to jest domena wszystkich znanych mi języków programowania.
Po co ten padding? Dzięki niemu pewne rzeczy mogą działać szybciej. Nie będę zagłębiał się w szczegóły, ale uwierz mi na słowo, że procesorowi łatwiej przenieść w inne miejsce 4 bajty niż 3.
Istnieje też w pewnym sensie nieco odwrotna operacja – pack. Powoduje ona usunięcie tego paddingu. To się przydaje gdy np. Twoja struktura lata pomiędzy bibliotekami dll pisanymi w różnych językach. Wtedy „pakowanie” ich znaaaaacznie ułatwia życie programiście.
Czym jest typ wartościowy?
Skoro już wiesz, że struktura i typy proste są typami wartościowymi, to teraz zadajmy sobie pytanie – czym do cholery są te typy wartościowe?
Typ wartościowy jest domyślnie przekazywany do metody przez wartość. Co to oznacza? Powinieneś już wiedzieć, jednak jeśli masz zaległości w temacie, już tłumaczę. Spójrz na poniższy kod:
static void Main(string[] args)
{
int number = 5;
Foo(number);
Console.WriteLine($"number: {number}");
}
static void Foo(int data)
{
data = 1;
}
Co tu się dzieje? Najpierw tworzymy zmienną lokalną number. Jak już wiesz, zmienna lokalna jest tworzona na stosie. Przed wejściem do metody Foo pamięć wygląda tak:
Teraz wchodzimy do metody Foo. I komputer widzi, że przekazujemy zmienną przez wartość, a więc najpierw przydziela miejsce dla parametru data, następnie KOPIUJE zawartość zmiennej number do zmiennej data. I tutaj „kopiuje” jest słowem kluczem. Po przypisaniu wartości data = 1 pamięć wygląda tak (patrzymy na większą część pamięci niż stos dla metody):
I teraz widzisz dokładnie, że w metodzie Foo pracujemy na kopii zmiennej number, a nie na zmiennej number. A właściwie na kopii jej wartości. Zmienna number cały czas „wskazuje” na zupełnie inny obszar w pamięci. Dlatego też po wyjściu z metody Foo zmienna number cały czas będzie miała warość 5.
Tak działa przekazywanie zmiennych przez wartość. I tak też są przekazywane struktury. Jaka jest tego konsekwencja? Jeśli masz strukturę składającą się z 10 zmiennych typu int (załóżmy 40 bajtów), to podczas wchodzenia do funkcji (lub wychodzenia z niej – jeśli dane zwracasz) te 40 bajtów jest kopiowane. W pewnych sytuacjach może się to odbić na szybkości działania programu.
Czym jest typ referencyjny?
Przekazywanie wartości przez referencję
Zacznę od tego, że w C# (i w innych językach też) możesz przekazać typ wartościowy za pomocą referencji. W C# robi się to za pomocą słowa ref lub out. Spójrz na ten przykład:
static void Main(string[] args)
{
int number = 5;
Foo(ref number);
Console.WriteLine($"number: {number}");
}
static void Foo(ref int data)
{
data = 1;
}
Dodałem tu jedynie słowa kluczowe ref, które mówią kompilatorowi, że tę wartość trzeba przekazać przez referencję. Co to znaczy? Że nie zostanie utworzona nowa zmienna w pamięci i nie zostaną skopiowane do niej dane. Po prostu komputer tak uruchomi metodę Foo:
Hej Foo, mam dla Ciebie dane w pamięci o adresie 0xblabla. Pracuj bezpośrednio na tych danych. Uruchom się.
I metoda Foo będzie pracować bezpośrednio na tych danych:
W konsekwencji pracujemy na tej samej pamięci, na którą wskazuje zmienna number. A więc zmienna number po wyjściu z metody Foo będzie miała już inną wartość.
Strukturę też możesz przekazać przez referencję dokładnie w taki sam sposób.
Typ referencyjny
No dobrze, dochodzimy wreszcie do tego, czym jest typ referencyjny. W C# każda klasa jest typem referencyjnym. Spójrz na ten kod:
class MyClass
{
public int Data { get; set; }
}
internal class Program
{
static void Main(string[] args)
{
MyClass obj;
}
}
Stos dla tego kodu będzie wyglądał tak:
Co widać w debugerze:
Obiekt tej klasy nie został utworzony. Klasa jest typem referencyjnym, a typy referencyjne nie są tworzone przez system operacyjny. Dlaczego? Ponieważ są to elementy „dynamiczne” – są tworzone w „dynamicznej” części pamięci – na stercie. Jak pisałem na początku, to programista odpowiada za tworzenie obiektów na stercie. I to programista musi przydzielić pamięć takiemu obiektowi. W C# robimy to za pomocą słowa new. Stwórzmy więc taki obiekt i zobaczmy co się stanie:
internal class Program
{
static void Main(string[] args)
{
MyClass obj = new MyClass();
obj.Data = 5;
}
}
Tworząc nowy obiekt najpierw musimy przydzielić mu miejsce na stercie. Takimi szczegółami zajmuje się już system operacyjny. Najpierw szuka odpowiedniego miejsca na stercie, które będzie na tyle duże, żeby pomieścić nasz obiekt, następnie rezerwuje tam pamięć dla niego, a na koniec adres do tej pamięci zwraca do zmiennej obj:
W debugerze stos teraz wygląda tak:
Tutaj zmienna obj jest na stosie i wskazuje na adres: 0x000001af16552cc0. A teraz spójrzmy, co pod tym adresem się znajduje:
Pod tym adresem znajdują się jakieś dane należące do tego konkretnego obiektu. Jest ich więcej niż tylko nasza zmienna int, ale nie jest istotne teraz co zawierają, istotne jest, że znajdują się na stercie.
Potem, gdy zmienna obj nie będzie już nigdzie używana, Garbage Collector zwolni to miejsce na stercie, które zajmuje ten obiekt.
Przekazanie obiektu do metody
Skoro klasy są typami referencyjnymi, to pewnie już się domyślasz, że obiekty są domyślnie przekazywane przez referencję. I dokładnie tak jest. Skoro zmienna obj posiada tylko adres, to ten adres zostanie przekazany do metody Foo:
Metoda Foo teraz wie, że dane ma pod konkretnym adresem. I na tych danych pracuje. Po wyjściu z metody Foo obj.Data będzie teraz miało wartość 1.
Dla dociekliwych – kopiowanie…
To nie jest tak, że w momencie wejścia do metody Foo nie jest robiona żadna kopia. Jest. Bo musi być. Bo metoda Foo ma własny stos i własne dane na tym stosie. A jedną z tych danych jest parametr data. Tyle, że ten parametr jest referencją, a więc przechowuje adres to obszaru na stercie. Zatem kopiowany jest tylko ten adres – te kilka bajtów. Niezależnie od tego jak wielka jest klasa i co w niej masz, jest tylko kopiowane te 8 bajtów (lub 4 w zależności od bitowości systemu operacyjngeo).
Użycie pamięci
Jak już wiesz, klasy są tworzone na stercie, a struktury na stosie.
Alokacja pamięci na stercie jest „droższa” od alokacji pamięci na stosie. Przede wszystkim trzeba znaleźć odpowiednio duży obszar. A na koniec Garbage Collector musi posprzątać. Jednak nie myśl o tym przy normalnym tworzeniu aplikacji – to zazwyczaj nie jest problemem. Chyba, że pracujesz nad naprawdę jakimś hiper krytycznym systemem. Ale wtedy nie czytałbyś tego artykułu 😉
Jednak pojawia się pewien mały szczegół podczas przekazywania typów wartościowych przez referencje. Ten szczegół to boxing i unboxing i jest pomysłem na inny artykuł. Generalnie chodzi o to, że typ wartościowy jest „opakowywany” w jakąś klasę, której obiekt jest tworzony na stercie. Później ten obiekt jest sprzątany przez Garbage Collector.
Jednak jeśli robisz dużo takich operacji (przekazywanie przez referencję), wtedy dużo dzieje się boxingów i unboxingów. To może mieć już wpływ na ogólną szybkość działania aplikacji.
Ogólnie przyjęte zasady
Z powyższych wynikają pewne ogólnie przyjęte zasady:
ZAWSZE STOSUJ KLASY – to jest obywatel lepszego sortu. Są jednak pewne wytyczne co do tego, kiedy bardziej opłaca stosować się struktury.
Rozważ (czytaj „możesz rozważyć) użycie struktury, gdy
struktura jest mała (poniżej 16 bajtów)
dane są niezmienne (przypisujesz tylko w konstruktorze i już ich nie zmieniasz)
nie będziesz przekazywał jej przez referencję
zawiera tylko typy proste
żyje krótko
reprezentuje „jedną fizyczną daną”, np. liczbę zespoloną, datę, punkt.
Ufff, ze trzy razy podchodziłem do tego artykułu. Mam nadzieję, że rozwiałem wątpliwości raz na zawsze, kiedy w C# stosować struktury, a kiedy klasy. Jeśli czegoś nie zrozumiałeś lub znalazłeś błąd w tekście, koniecznie daj znać w komentarzu.
Aha, no i udostępnij artykuł osobom, które ciągle się zastanawiają nad tematem 🙂
Obsługujemy pliki cookies. Jeśli uważasz, że to jest ok, po prostu kliknij "Akceptuj wszystko". Możesz też wybrać, jakie chcesz ciasteczka, klikając "Ustawienia".
Przeczytaj naszą politykę cookie