Pozwolisz, że w artykule będę posługiwał się anglojęzyczną nazwą „tag helper” zamiast „tag pomocniczy”, bo to po prostu brzmi jakby ktoś zajeżdżał tablicę paznokciem.
Czym jest tag helper?
Patrząc od strony Razor (niezależnie czy to RazorPages, czy RazorViews, robi się to identycznie), tag helper to nic innego jak tag w HTML. Ale nie byle jaki. Stworzony przez Ciebie. Kojarzysz z HTML tagi takie jak a, img, p, div itd? No więc tag helper od strony Razor to taki dokładnie tag, który sam napisałeś. Co więcej, tag helpery pozwalają na zmianę zachowania istniejących tagów (np. <a>). Innymi słowy, tag helpery pomagają w tworzeniu wyjściowego HTMLa po stronie serwera.
To jest nowsza i lepsza wersja HTML Helpers znanych jeszcze z czasów ASP.
Na co komu tag helper?
Porównaj te dwa kody z Razor:
<div>
@Html.Label("FirstName", "Imię:", new {@class="caption"})
</div>
Który Ci się bardziej podoba? caption-label to właśnie tag helper. Jego zadaniem jest właściwie to samo, co metody Label z klasy Html. Czyli odpowiednie wyrenderowanie kodu HTML. Jednak… no musisz się zgodzić, że kod z tag helperami wygląda duuuużo lepiej.
(tag helper caption-label nie istnieje; nazwa została zmyślona na potrzeby artykułu)
Tworzenie Tag Helper’ów
Tworzenie nowego projektu
Utwórz najpierw nowy projekt WebApplication w Visual Studio. Jeśli nie wiesz, jak to zrobić, przeczytaj ten artykuł.
Nowy Tag Helper
GitHub i NuGet są pełne customowych (kolejne nieprzetłumaczalne słowo) tag helperów. W samym .NetCore też jest ich całkiem sporo. Nic nie stoi na przeszkodzie, żebyś stworzył własny. Zacznijmy od bardzo prostego przykładu.
Stwórzmy tag helper, który wyśle maila po kliknięciu. Czyli wyrenderuje dokładnie taki kod HTML:
Przede wszystkim musisz zacząć od napisania klasy dziedziczącej po abstrakcyjnej klasie… TagHelper. Chociaż tak naprawdę mógłbyś po prostu napisać klasę implementującą interfejs ITagHelper. Jednak to Ci utrudni pewne rzeczy. Zatem dziedziczymy po klasie TagHelper:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
}
UWAGA! Nazwa Twojej klasy nie musi zawierać sufiksu TagHelper. Jednak jest to dobrą praktyką (tak samo jak tworzenie tag helperów w osobnym folderze TagHelpers lub projekcie). Stąd klasa nazywa się MailTagHelper, ale w kodzie HTML będziemy używać już tagu mail. Takie połączenie zachodzi automagicznie.
Super, teraz musimy zrobić coś, żeby nasz tag helper <mail> zamienił się na HTMLowy tag <a>. Służą do tego dwie metody:
Process – metoda, która zostanie wywołana SYNCHRONICZNIE, gdy serwer napotka na Twój tag helper
ProcessAsync – dokładnie tak jak wyżej, z tą różnicą, że to jest jej ASYNCHRONICZNA wersja
Wynika z tego, że musimy przesłonić albo jedną, albo drugą. Przesłanianie obu nie miałoby raczej sensu. Oczywiście będziemy posługiwać się asynchroniczną wersją, zatem przesłońmy tę metodę najprościej jak się da:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
}
}
Teraz zastanówmy się, jakie parametry chcemy przekazać do helpera. Ja tu widzę dwa:
adres e-mail odbiorcy
tytuł maila
Dodajmy więc te parametry do naszej klasy w formie właściwości:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public string Address { get; set; }
public string Subject { get; set; }
}
Rejestracja Tag Helper’ów
Rejestracja to w tym wypadku to bardzo duże słowo. Niemniej jednak, żeby nasz tag helper był w ogóle widoczny, musimy zrobić jeszcze jedną małą rzecz.
Odnajdź w projekcie plik _ViewImports.cshtml i zmień go tak:
Jeśli Twój tag helper znajduje się w innym namespace (np. umieściłeś go w katalogu TagHelpers), „zaimportuj” ten namespace na początku (moja aplikacja nazywa się WebApplication1): @using WebApplication1.TagHelpers
Następnie „zarejestruj” swoje tag helpery w projekcie, dodając na końcu pliku linijkę: @addTagHelper *, WebApplication1
Ostatecznie mój plik _ViewImports.cshtml wygląda tak:
A teraz małe wyjaśnienie. Nie musisz tego czytać, ale powinieneś.
Plik _ViewImports jest specjalnym plikiem w .NetCore. Wszystkie „usingi” tutaj umieszczone mają wpływ na cały Twój projekt. To znaczy, że usingi z tego pliku będą w pewien sposób „automatycznie” dodawane do każdego Twojego pliku cshtml.
To znaczy, że jeśli tu je umieścisz, to nie musisz już tego robić w innych plikach cshtml. Oczywiście nigdy nie rób tego „na pałę”, bo posiadanie 100 nieużywanych usingów w jakimś pliku jeszcze nigdy nikomu niczego dobrego nie przyniosło 🙂
Zatem w tej linijce @using WebApplication1.TagHelpers powiedziałeś: „Chcę używać namespace’a WebApplication1.TagHelpers na wszystkich stronach w tym projekcie”.
A co do @addTagHelper. To jest właśnie ta „rejestracja” tag helpera. Zwróć najpierw uwagę na to, co dostałeś domyślnie od kreatora projektu: @addTagHelper *, Microsoft.AspNetCore.Mvc.TagHelpers. Zarejestrował on wszystkie domyślne tag helpery.
A teraz spójrz na tę linijkę, którą napisaliśmy: @addTagHelper *, WebApplication1. Jeśli coś Ci tu nie pasuje, to gratuluję spostrzegawczości. A jeśli masz pewność, że to jest ok, to gratuluję wiedzy 🙂
Można łatwo odnieść wrażenie, że rejestrujesz tutaj wszystkie (*) tag helpery z namespace WebApplication1. Jednak @addTagHelper wymaga podania nazwy projektu, a nie namespace’a. Akurat Bill tak chciał, że domyślne tag helpery znajdują się w projekcie o nazwie Microsoft.AspNetCore.Mvc.TagHelpers. Nasz projekt (a przynajmniej mój) nazywa się WebApplication1.
Przypominam i postaraj się zapamiętać:
Klauzula @addTagHelper wymaga podania nazwy projektu, w którym znajdują się tag helpery, a nie namespace’a.
Pierwsze użycie tag helper’a
OK, skoro już tyle popisaliśmy, to teraz użyjemy naszego tag helpera. On jeszcze w zasadzie niczego nie robi, ale jest piękny, czyż nie?
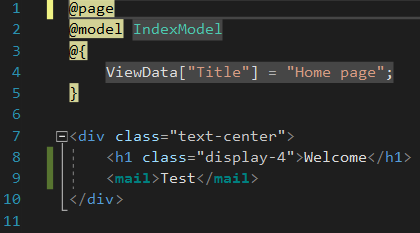
Przejdź do pliku Index.cshtml i dodaj tam naszego tag helpera. Zanim to jednak zrobisz, zbuduj projekt. Może to być konieczne, żeby VisualStudio wszystko zobaczył i zaktualizował Intellisense.
Specjalnie użyłem obrazka zamiast kodu, żeby Ci pokazać, jak Visual Studio rozpoznaje tag helpery. Pokazuje je na zielono (to zielony, prawda?) i lekko pogrubia. Jeśli u siebie też to widzisz, to znaczy, że wszystko zrobiłeś dobrze.
OK, to teraz możesz postawić breakpointa w metodzie ProcessAsync i uruchomić projekt.
Jeśli breakpoint zadziałał, to wszystko jest ok. Jeśli nie, coś musiało pójść nie tak. Upewnij się, że używasz odpowiedniego namespace i nazwy projektu w pliku _ViewImports.cshtml.
Niech się stanie anchor!
OK, mamy taki kod w tag helperze:
//using Microsoft.AspNetCore.Razor.TagHelpers
public class MailTagHelper: TagHelper
{
public string Address { get; set; }
public string Subject { get; set; }
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
}
}
Teraz trzeba coś zrobić, żeby zadziałała magia.
Popatrz co masz w parametrze metody ProcessAsync. Masz tam jakiś output. Jak już mówiłem wcześniej, tag helper RENDERUJE odpowiedni kod HTML. Za ten rendering jest odpowiedzialny właśnie parametr output. Spróbujmy go wreszcie wykorzystać. Spójrz na kod metody poniżej:
TagHelperOutput ma taką właściwość jak TagName. Ta właściwość mówi dokładnie: „Jaki tag html ma mieć Twój tag helper?”. Uruchom teraz aplikację i podejrzyj wygenerowany kod html:
<a>Test</a>
Twój tag <mail> zmienił się na <a>.
I o to mniej więcej chodzi w tych helperach. Ale teraz dodajmy resztę rzeczy. Musimy jakoś dodać atrybut href. Robi się to bardzo prosto:
Jak widzisz wszystko załatwiliśmy outputem. Myślę, że ta linijka sama się tłumaczy. Po prostu dodajesz atrybut o nazwie href i wartości mailto:.... itd. Uruchom teraz aplikację i popatrz na magię.
Wszystko byłoby ok, gdybyśmy gdzieś przekazali te parametry Address i Subject. Przekażemy je oczywiście w pliku cshtml:
Zwróć tylko uwagę, że wg konwencji klasy w C# nazywamy tzw. PascalCase. Natomiast w tag helperach używasz już tylko małych liter. Tak to zostało zrobione. Jeśli masz kilka wyrazów w nazwie klasy, np. ContentLabelTagHelper, w pliku cshtml te wyrazy oddzielasz myślnikiem: <content-label>. Dotyczy to również atrybutów.
Oczywiście możesz z takim tag helperem zrobić wszystko. Np. zapisać na sztywno mail i temat, np:
Przeanalizuj ten kod. Po prostu, jeśli nie podasz adresu e-mail lub tematu wiadomości, zostaną one wzięte z wartości domyślnych. Oczywiście te wartości domyślne mogą być wszędzie. W stałych – jak tutaj – w bazie danych, w pliku… I teraz wystarczy, że w pliku cshtml napiszesz:
<mail>Test</mail>
Fajnie? Dla mnie bomba!
Atrybuty dla Tag Helper
Tag helpery mogą zawierać pewne atrybuty, które nieco zmieniają ich działanie:
HtmlTargetElement
Możemy tu określić nazwę taga, jaką będziemy używać w cshtml, rodzica dla tego taga, a także jego strukturę, np:
[HtmlTargetElement("email")]
public class MailTagHelper: TagHelper
{
}
Od tej pory w kodzie cshtml nie będziemy się już posługiwać tagiem <mail>, tylko <email>. Możemy też podać nazwę tagu rodzica, ale o tym w drugiej części artykułu. Możemy też określić strukturę tagu. Może on wymagać tagu zamknięcia (domyślnie) lub być bez niego, np:
[HtmlTargetElement("email", TagStructure = TagStructure.NormalOrSelfClosing)]
public class MailTagHelper: TagHelper
{
}
W przypadku tak skonstruowanego tagu email nie ma to sensu, ale moglibyśmy to przeprojektować i wtedy tag można zapisać tak: <email text="Napisz do mnie" /> lub tak: <email text="Napisz do mnie"></email>
TagStructure może mieć takie wartości:
TagStructure.NormalOrSelfClosing – tag z tagiem zamknięcia, bądź samozamykający się – jak widziałeś wyżej. Czyli możesz napisać zarówno tak: <mail address="a@b.c"></mail> jak i tak: <mail address="a@b.c" />
TagStructure.Unspecified – jeśli żaden inny tag helper nie odnosi się do tego elementu, używana jest wartość NormalOrSelfClosing
TagStructure.WithoutEndTag – niekonieczny jest tag zamknięcia. Możesz napisać tak: <mail address="a@b.c"> jak i tak: <mail address="a@b.c" />
HtmlTargetElement ma jeszcze jeden ciekawy parametr służący do ustalenia dodatkowych kryteriów. Spójrz na ten kod:
[HtmlTargetElement("email", Attributes = "send")]
public class MailTagHelper: TagHelper
{
//tutaj bez zmian
}
Aby teraz taki tag helper został dobrze dopasowany, musi być wywołany z atrybutem send:
<email send>Napisz do mnie</email>
Ten kod zadziała i tag zostanie uruchomiony. Ale taki kod już nie zadziała:
<email>Napisz do mnie</email>
Ponieważ ten tag nie ma atrybutu send.
Przy pisaniu własnych tagów raczej nie ma to zbyt wiele sensu, ale popatrz na coś takiego:
<p red>UWAGA! Oni nadchodzą!</p>
I tag helper do tego:
[HtmlTargetElement("p", Attributes = "red")]
public class PRedTagHelper: TagHelper
{
public override async Task ProcessAsync(TagHelperContext context, TagHelperOutput output)
{
await base.ProcessAsync(context, output);
output.Attributes.Add("style", "color: red");
}
}
Teraz każdy tekst w paragrafie z atrybutem red będzie napisany czerwonym kolorem. To daje nam naprawdę ogromne możliwości.
HtmlAttributeNotBound
Do tej pory widziałeś, że wszystkie właściwości publiczne tag helpera mogą być używane w plikach cshtml. No więc nadchodzi atrybut, który to zmienia. HtmlAttributeNotBound niejako ukrywa publiczną właściwość dla cshtml.
Stosujemy to, gdy jakaś właściwość (atrybut) nie ma sensu od strony HTML lub jest niepożądana, ale z jakiegoś powodu musi być publiczna. Spójrz na ten kod:
public class MailTagHelper: TagHelper
{
[HtmlAttributeNotBound]
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Teraz właściwość Address nie będzie widoczna w cshtml. Oczywiście tego atrybutu używamy na właściwościach, a nie na klasie.
HtmlAttributeName
Ten atrybut z kolei umożliwia zmianę nazwy właściwości tag helpera w cshtml. Nadpisuje nazwę atrybutu:
public class MailTagHelper: TagHelper
{
[HtmlAttributeName("Tralala")]
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Teraz w pliku cshtml możesz napisać tak:
<email tralala="a@b.c" />
Ale ten atrybut ma jeszcze jedno przeciążenie i potrafi ostro zagrać. Może zwali Cię to z nóg. Dzięki niemu możesz w pliku cshtml napisać co Ci się podoba, a Twój tag helper to ogarnie. Możesz popisać atrybuty, które nie są właściwościami Twojego tag helpera! Spójrz na ten przykład:
public class MailTagHelper: TagHelper
{
[HtmlAttributeName(DictionaryAttributePrefix = "mb_")]
public Dictionary<string, string> Prompts { get; set; } = new Dictionary<string, string>();
public string Address { get; set; }
public string Subject { get; set; }
public string Text { get; set; }
}
Co tu zaszło? Spójrz, co podałeś w parametrze atrybutu HtmlAttributeName. Jest to jakiś prefix. A teraz zauważ, że w kodzie html użyłeś tego prefixu do określenia nowych atrybutów.
Po takiej zabawie, słownik Prompts będzie wyglądał tak:
adr: „a@b.c”
subject: „Temat”
Zauważ, że prefix został w słowniku automatycznie obcięty i trafiły do niego już konkretne atrybuty.
Oczywiście to przeciążenie może być użyte tylko na właściwości, która implementuje IDictionary. Kluczem musi być string, natomiast wartością może być string, int itd.
To tyle, jeśli chodzi o podstawy tworzenia tag helperów. O bardziej zaawansowanych możliwościach mówię w drugiej części artykułu. Najpierw upewnij się, że dobrze zrozumiałeś wszystko co tu zawarte.
Jeśli masz jakiś problem albo znalazłeś w artykule błąd, podziel się w komentarzu.
Gdy tworzysz i uruchamiasz webową aplikację (czy to WebApp, czy WebApi) w .NetCore, to domyślnie startuje ona pod adresem: http://localhost:port. Zazwyczaj to wystarcza do tworzenia, debugowania i późniejszej publikacji aplikacji. I super.
Jednak czasem potrzebujesz uruchomić aplikację pod konkretną domeną – np. gdy w grę wchodzą dodatkowe API – przykładem może być api facebooka lub różnego rodzaju captche (reCaptcha, hCaptcha itd.). Te API potrzebują być wywołane spod konkretnego adresu lub wywołać coś na konkretnym adresie. I wtedy localhost może być problemem.
Niektóre API w ogóle nie chcą współpracować z localhost. I co wtedy? No, zawsze można opublikować aplikację na serwerze i próbować ją debugować. Więcej z tym problemów, niż co warte – nie tędy droga. Na szczęście istnieje sposób, żeby twój localhost stał się prawilną domeną. I o tym będzie w tym poście.
UWAGA!
Pamiętaj, że jeśli to robisz, nie twórz domen istniejących w sieci. Jeśli masz zarejestrowaną domenę, np. xmoney-app.pl, to wtedy Twoim lokalnym odpowiednikiem powinna być subdomena istniejąca jedynie lokalnie, np: local.xmoney-app.pl, czy też dev.xmoney-app.pl albo moja-super-subdomena-lokalna.xmoney-app.pl
Rozwiązanie
Posługując się taką subdomeną, zazwyczaj pozwalasz zewnętrznym API na uznanie jej jako subdomeny Twojej prawdziwej domeny i nie ma tu problemów.
Jak to osiągnąć (mowa o Windowsie):
Znajdź swój plik hosts. Domyślnie znajduje się w lokalizacji: C:\Windows\System32\drivers\etc. Plik hosts to takie coś w rodzaju „lokalnego DNSa”.
Wyedytuj go (w trybie administratora) i wskaż swojej pętli zwrotnej swoją subdomenę. Na ludzki, dodaj do 127.0.0.1 – swoją subdomenę, np:
127.0.0.1 local.xmoney-app.pl
tutaj oczywiście zamiast xmoney, umieszczasz swoją subdomenę 🙂 Pamiętaj, żeby pozbyć się hasha '#’ jeśli znajduje się na początku (hash oznacza komentarz). A między adresem, a domeną koniecznie daj tabulator.
Teraz musisz swoją subdomenę powiązać ze swoją aplikacją. Wejdź do katalogu swojej solucji. Jeśli nie widzisz tam katalogu .vs, to pokaż ukryte pliki i foldery. Generalnie poszukaj pliku applicationhost.config, w VisualStudio powyżej 15 wersji powinien znajdować się w katalogu: [TwojaSolucja].vs[Nazwa]\config\
Skopiuj ten plik gdzieś obok i wyedytuj oryginał. Ten plik to są ustawienia IISExpress.
Odszukaj w nim sekcję "sites", a następnie konkretny projekt, którego domenę chcesz zmienić. Jeśli masz tylko jeden webowy projekt w solucji, to w sekcji sites powinieneś mieć tylko jeden wpis.
Odnajdź informację o bindowaniu. Generalnie szukasz tego:
oczywiście wpisując tutaj swoją subdomenę, którą umieściłeś w pliku hosts.
UWAGA! Wpis powinieneś dodać, a nie podmienić ten oryginalny
Zaktualizuj projekt w Visual Studio – kliknij na swój projekt webowy prawym klawiszem myszy i wybierz „Properties”.
Na karcie „Debug” w polu App URL wpisz adres swojej domeny, np: http://local.xmoney-app.pl:44313 – czyli zasadniczo to, co przed chwilą zrobiłeś w pliku applicationhost.config. Tylko teraz – dla projektu.
I to już.
UWAGA! Jest jeden haczyk. Żeby to zadziałało i strona się normalnie uruchomiła, musisz otworzyć VisualStudio w trybie Administratora. Niestety w tym momencie (początek roku 2021) uruchomienie IISExpress w innej domenie niż localhost, wymaga uprawnień administratora.
Możliwe problemy:
W rzeczywistości nie zawsze jest miło i przyjemnie. Czasem nawet wódka szkodzi. Tak i tutaj może dojść do kilku problemów.
Uruchamiasz aplikację, a tam komunikat "Website cannot be found", "Nie można odnaleźć strony" lub tego typu cuda. To może mieć związek z serwerem proxy. Musisz zatem pominąć ten adres (całą swoją subdomenę) w ustawieniach serwera proxy. W różnych przeglądarkach robi się to inaczej. Ja, używając Windowsa 10, robię to dla całego systemu, czyli:
otwórz „pasek start”
wpisz: „Zmień ustawienia serwera proxy”
na dole powinieneś zobaczyć okienko, w którym możesz dołożyć wyjątki do proxy – czyli adresy zaczynające się od tych wpisów, będą pomijane przez proxy. Tylko UWAGA! Musisz dodać całą swoją subdomenę, czyli w moim przypadku: local.xmoney-app.pl
Fragment okna konfiguracji serwera proxy w Windows 10
Problem z SSL. Teoretycznie wystarczy, że w ustawieniach projektu na karcie Debug zaznaczysz opcję „Enable SSL”. Automatycznie powinien się zrobić wpis w pliku applicationhost.config. Uruchamiając teraz aplikacje, dostaniesz komunikat, że jest niebezpieczna i opcję jej uruchomienia. I tyle. Jeśli debugujesz na Chromie, to będzie on Ci pokazywał brzydkie rzeczy na pasku. Ale nie przejmuj się tym, póki debugujesz.
Jeśli debugujesz na Firefoxie, nie zobaczysz takich strasznych rzeczy, bo FF pokazuje tylko małą uwagę, że certyfikat jest developerski na localhost.
Jeśli znalazłeś w tekście jakiś błąd lub masz inny problem, podziel się w komentarzu
Jeśli próbujesz użyć TypeScript w NetCore i coś Ci nie idzie – to jest artykuł dla Ciebie.
Wstęp
Hej, jakiś czas temu tworzyłem pewien kod na frontendzie, w którym musiałem użyć JavaScriptu. Dużo JavaScriptu i Ajaxa. Jak już pewnie zdążyłeś się przekonać – nie lubię JavaScriptu 🙂 Przypomniałem sobie, że przecież istnieje coś takiego jak Typescript! Super! Mogę wreszcie pisać w normalnym języku. Więc zacząłem ogarniać, jak używać TypeScript w NetCore. Okazało się, że mimo że dokładnie robię wszystko to, co opisuje Microsoft i milion innych artykułów, to nic u mnie nie chce działać tak jak powinno. Po kilku dniach szamotaniny, przeczytaniu i przeanalizowaniu całego Internetu, w końcu wygrałem! Okazało się, że są pewne kruczki, o których nikt wtedy nie mówił. Zatem w tym artykule przedstawię Ci te kruczki.
(uwaga, dotyczy to raczej sytuacji, w której nie używasz CAŁEGO node.js, ale generalnie nawet w tym przypadku artykuł może Ci się przydać)
Jak działa TypeScript
Generalnie przeglądarki jeszcze (2021 rok) nie są w stanie obsłużyć TypeScriptu jako takiego. Możesz o TS pomyśleć jak o języku wysokiego poziomu. Jeśli piszesz program np. w C++, komputer nie wie, co ma z nim zrobić. Taki program musi być skompilowany. Ostatecznie uruchamiany jest kod assemblera, z którym komputer już wie co zrobić. Analogiczna sytuacja jest tutaj. Przeglądarka nie wie, co ma zrobić z TypeScriptem. Więc jest on najpierw przerabiany do postaci JavaScriptu i dopiero ten JS jest uruchamiany przez przeglądarkę. Tą „kompilacją” w pewnym sensie steruje plik konfiguracyjny TypeScriptu – tscongif.json
Upewnij się, że masz zainstalowany node.js w VisualStudio. Po prostu uruchom VisualStudioInstaller i sprawdź, czy masz ten moduł. Jeśli nie – zainstaluj go.
Pobierz pakiet NuGet: Microsoft.TypeScript.MSBuild – dzięki temu będziesz mógł w ogóle pisać w TypeScript w NetCore.
Kliknij prawym klawiszem myszy na swój projekt i wybierz Add -> New File -> TypeScript JSON configuration file. W Twoim projekcie pojawi się nowy plik: tsconfig.json. Jest to plik konfiguracyjny dla TypeScriptu, który steruje kompilacją do JS. tsconfig.json na dzień dobry powinien wyglądać tak:
noImplicitAny – jesli true, wtedy wszędzie tam, gdzie używasz „typu” any, będzie rzucany wyjątek
noEmitOnError – jeśli true, wtedy nie będą wyświetlane żadne outputy, gdy pojawi się błąd. Możesz sobie tutaj ustawić false w środowisku testowym/developerskim, ale pamiętaj żeby na produkcji lepiej nie pokazywać takich błędów. Dla bezpieczeństwa
removeComments – jeśli true, wszystkie użyte przez Ciebie komentarze zostaną usunięte w wynikowym JavaScripcie. Ja to zostawiłem na false, chcę widzieć komentarze. Ale możesz to zmienić.
sourceMap – podczas kompilacji generowana jest tzw. mapa. Chodzi o zmapowanie kodu TS z JS. Dzięki temu możliwe jest debugowanie TypeScriptu. Więc zostaw to na TRUE
target – określa wersję docelową ECMAScript. To jest standard skryptowego języka programowania. Jak np. .NET Framework 4.5. To znaczy, że w starszych wersjach nie będziesz miał dostępu do CAŁEGO aktualnego standardu języka. Niestety, niektóre moduły nie chcą za bardzo współpracować z pewnymi standardami. W moim przypadku ES6 było ok. Ale możesz spróbować też ES5, jeśli coś nie będzie działać
outDir – katalog, do którego ma trafiać wynikowy kod JavaScript. Pamiętaj, że ten katalog musi być widoczny z poziomu HTML
esModuleInterop – ustawione na true pomaga importować typy i moduły. Nie będę wchodził w szczegóły, po prostu tak zostaw – to jest ważne
module – określa w jaki sposób będą ładowane moduły. AMD wskazuje na asynchroniczne ładowanie. Tutaj lepiej wypowiedzą się JavaScriptowcy (zapraszam do komentowania). Ten artykuł jest pisany pod „AMD” i tego się trzymajmy.
moduleResolution – określa w jaki sposób jest uzyskiwany dostęp do modułów. Tutaj posługujemy się node.js, więc zostawiamy na Node
compileOnSave – czy kompilować przy każdym zapisie pliku. Oznacza, że za każdym razem, gdy zapiszesz zmiany w pliku TS, będzie on kompilowany do JS. W przeciwnym razie kompilacja będzie tylko przy budowaniu projektu.
Utwórz w projekcie katalog Scripts. W nim będziesz tworzył pliki .ts
Zewnętrzne biblioteki (thirdparties)
Teraz zajmiemy się zewnętrznymi bibliotekami, których na pewno używasz w .NetCore. Sprawdź, czy masz w projekcie plik package.json. Jeśli nie, dodaj go w taki sposób:
prawym klawiszem na projekt
Add -> New item
wyszukaj i dodaj npm configuration file. Jeśli tego nie widzisz, to najpewniej nie zainstalowałeś node.js, o czym mówiliśmy w pierwszym kroku. Czym jest npm? NPM to taki manager pakietów. Coś jak NuGet. Tutaj masz pakiety do weba. I właściwie tyle. Są pewne alternatywny, np. yarn albo LibraryManager. Ale tutaj ogarniamy za pomocą npm.
Skoro masz już plik package.json – czyli konfigurację zewnętrznych modułów, upewnij się, że wygląda podobnie do tego:
Tutaj ważna jest zawartość devDependencies. Koniecznie musisz mieć bootstrap, jquery i jquery-validation-unobtrusive. Autonumeric zostawiam dla przykładu. Jest to jedna z bibliotek, której używam. Ogarnia rzeczy związane z numerami, walutami etc. Chcę tylko pokazać, że w devDependencies będziesz też trzymał inne moduły, których używasz. Niektóre moduły mogą wymagać, żebyś miał je w dependencies. Ale to tak naprawdę zależy od konkretnej biblioteki. Niestety niektóre biblioteki nie mają (jeszcze) odpowiedników w TypeScript.
Pamiętaj, że musisz mieć takie wersje jQuery i boostrap, których używasz w projekcie. Te 3 linijki (@types/…) umożliwiają Ci używanie typów z bootstrap i jquery w Twoich skryptach TypeScript. To cholernie pomaga. CHOLERNIE.
Eksporty
Podczas pisania kodu TypeScript, musisz eksportować klasy i funkcje, których używasz (dotyczy to tej właśnie konfiguracji, którą zrobiliśmy), tj.:
export class Person //definicja klasy
{
//reszta kodu
}
export function foo() //definicja funkcji
{
//reszta kodu
}
W plikach ts, w których chcesz używać tych klas i funkcji, musisz je zaimportować. Na przykład:
import { Person } from "./person";
export class ClassThatUsesPerson
{
_person: Person;
//i reszta kodu
}
Pamiętaj, że dyrektywy import powinny być na początku pliku. Tutaj są istotne dwa szczegóły:
importujesz plik BEZ rozszerzenia, czyli „./person” zamiast „./person.ts”
wskazujesz na bieżący katalog za pomocą „./”. Jeśli zaimportujesz w taki sposób: import { Person } from "person", to nie zadziała. Musi być "./person"
Inne biblioteki, których używasz importujesz w analogiczny sposób. Oczywiście musisz mieć wpisany pakiet w npm (package.json) i wtedy np: import AutoNumeric from 'autonumeric'
Teraz kolejna istotna rzecz – pobierz bibliotekę requireJS. To jest biblioteka JavaScript, która posiada pewne funkcje, występujące w pełnym node.js. Np. require. Pliki TypeScript są kompilowane w taki sposób, że kod JavaScript dołącza inne pliki za pomocą funkcji require. To nie jest standardowa funkcja JS. Jak już pisałem, występuje w pełnym node.js. Jeśli nie używasz pełnego frameworka node.js, to musisz pobrać tę bibliotekę.
Przygotowanie strony na TypeScript – entrypoint
Teraz kilka zmian w pliku _Layout.cshtml, żeby TypeScript w NetCore ruszył z miejsca Pozbądź się nagłówków związanych z jQuery i bootstrap. Dodaj jednak te:
(zakładam, że pobrałeś require.js i znajduje się ona w wwwroot/lib) (zakładam, że masz katalog: wwwroot/js i tam będziesz trzymał swoje skrypty js)
Teraz w katalogu wwwroot/js utwórz plik entrypoint.js (to ma być JavaScript, a nie TypeScript). To będzie punkt wejścia Twojej aplikacji. Niech on wygląda podobnie do tego:
Pamiętaj, żeby zgadzały się wersje bibliotek z tymi, wpisanymi w package.json. Zakładam, że w katalogu Scripts masz plik app.ts, który wygląda co najmniej tak:
export class App {
static init() {
}
}
Stworzyłem sobie taką główną klasę aplikacji. W metodzie init() inicjuję wszystko, czego używam na każdej lub większości stron. Np. bootstrap carousel:
Normalnie zakodowałbyś to w document.ready albo body.onload. A tak mamy metodę init() w klasie App, w której już tworzysz czysty TypeScript.
Wyjaśnienie entrypoint.js
Jeśli chodzi o resztę pliku entrypoint.js:
Na początku konfigurujemy bibliotekę require.js (możesz sprawdzić jej pełną konfigurację na stronie requireJS); w skrócie:
baseUrl – domyślna lokalizacja, w której requireJS będzie szukał plików JS (tych „czystych” jak i wykompilowanych z TypeScript)
shim – to jest wymagane, żeby bootstrap działał poprawnie, szczerze powiem że nie wiem co oznacza ponad to.
paths – tutaj możesz określić ścieżki do swoich modułów. Po prostu dodaj tu biblioteki, których nie masz w folderze js (libs) i chciałbyś pobierać je za pomocą CDN. Te 3 to wymagane minimum, jeśli używasz jQuery, jQuery-validation i bootstrap. A zapewne używasz, skoro używasz TypeScript w NetCore.
UWAGA! Upewnij się, że używasz tutaj bootstrap.bundle.min zamiast boostrap.min. Wersja „bundle” ma dodatkowe referencje (np. do popper.js), co czyni rzeczy duuuużo prostszymi.
UWAGA! Nazwy modułów są istotne. To MUSI być „jquery-validation” i „jquery.validate.unobtrusive” (zwróć uwagę na literówki, kropki i myślniki)
Na końcu pliku entrypoint jest instrukcja require. Ona mówi tyle:
Załaduj moduły: jquery, bootstrap i app pod takimi zmiennymi: js, bs, app. Ładowanie w tym miejscu jquery i bootstrap jest zasadniczo wymagane, żeby reszta strony mogła tego używać.
Używanie TypeScript w HTML
Upewnij się teraz, że w CAŁYM kodzie (poza _Layout.cshtml) nie masz żadnego <script src="..."></script> . Teraz skrypty będziesz dołączał inaczej – używając funkcji require. Przykładowo, jeśli masz gdzieś:
<script src="~/js/person.js"></script>
powinieneś zmienić na:
<script>
require(["person"]);
</script>
A jeśli chciałbyś utworzyć obiekt i używać go później na stronie (w pliku html), zrób tak:
<script>
var personObj;
require(["person"], function(personFile) {
personObj = new personFile.Person();
});
</script>
Pamiętaj, że na dzień dzisiejszy (maj 2021) nie możesz używać bezpośrednio TypeScript w kodzie HTML. Ale bardzo łatwo możesz to obejść – po prostu napisz sobie kod analogiczny do tego powyżej i będziesz mógł zrobić już wszystko -> ale bez Intellisense, np:
To wynika z tego, co pisałem wyżej. A jeśli używasz dodatkowych walidacji, jak np. opisanych w tym artykule, to powinno to wyglądać tak:
<script>
require(["jquery", "jquery-validation", "jquery.validate.unobtrusive"], function ($) {
$.validator.addMethod("chboxreq", function (value, element, param) {
if (element.type != "checkbox")
return false;
return element.checked;
});
$.validator.unobtrusive.adapters.addBool("chboxreq");
});
</script>
TypeScript w OnClick albo innych zdarzeniach
Teraz druga uwaga. Czasem bywa tak, że chcesz wykonać jakąś metodę w onclick buttona albo gdziekolwiek indziej. Od razu podpowiadam (choć to wynika już samo z siebie), przykład:
Załóżmy, że masz taki plik MyClass.ts
export class MyClass {
constructor() {
}
public onOkBtnClick(sender: object) {
alert("Siema");
}
}
I teraz chcesz metodę onOkBtnClick wywołać po kliknięciu przycisku. Więc Twój plik .cshtml powinien wyglądać tak:
<script>
var myObj;
requirejs(["MyClass"], function(myClassFile) {
myObj = new myClassFile.MyClass();
});
</script>
<button onclick="myObj.onOkBtnClick(this);">OK</button>
Teraz już możesz szaleć z TypeScript w NetCore i nawet go debugować! Pamiętaj tylko, że:
debugować TypeScript można tylko w przeglądarce Google Chrome
stan na maj 2021
Jeśli masz problem albo znalazłeś błąd w tekście, podziel się w komentarzu.
Pokażę Ci jak zrobić własną walidację na bardzo użytecznym przykładzie. Zrobimy mechanizm sprawdzenia, czy użytkownik wyraził zgodę na regulamin. Jeśli nie wiesz, jak działa walidacja w .NetCore, sprawdź najpierw ten artykuł.
Stworzenie własnej walidacji składa się z dwóch kroków.
utworzenie własnego atrybutu
dodanie sprawdzenia po stronie JavaScript.
Zasadniczo jest to dość proste, ale trzeba pamiętać o pewnej rzeczy… o tym później
Walidacja po stronie klienta
Required nie wystarczy
W .NET można tworzyć własne atrybuty. To wiadomo. Atrybut to po prostu klasa, która dziedziczy po specyficznej klasie i zawiera… konkretne atrybuty 🙂
Z jakiegoś powodu w .NetCore nie ma domyślnie możliwości sprawdzenia, czy checkbox został zaznaczony. Wydawać by się mogło, że wystarczy:
class RegisterUserViewModel
{
[Required]
public bool TermsAndConditions { get; set; }
}
Widziałem też takie przykłady:
class RegisterUserViewModel
{
[Range(typeof(bool), "true", "true")]
public bool TermsAndConditions { get; set; }
}
niestety z checkboxem i jego wartością jest nieco inaczej. I powinien zostać do tego stworzony nowy atrybut. Rozwiązanie, które tutaj podaję zaproponowałem do Microsoftu. Być może w kolejnych wersjach wdrożą coś analogicznego.
Dopisane: W Blazor można walidować checkbox za pomocą atrybutu Required
Tworzenie własnego atrybutu
Zatem stwórzmy własny atrybut walidacyjny. Takie atrybuty powinny dziedziczyć po klasie ValidationAttribute. Jest to klasa abstrakcyjna, która zawiera pewną wspólną logikę dla wszystkich walidacji.
ValidationAttribute zapewnia walidację po stronie serwera. Jeśli chcesz mieć zapewnioną dodatkowo walidację po stronie klienta, musisz zaimplementować interfejs IClientModelValidator.
IClientModelValidator
Tutaj na chwilę się zatrzymamy. Walidacja po stronie klienta zawsze odbywa się za pomocą JavaScript (lub podobnych). .NetCore to znacznie ułatwia, gdyż wprowadza własny prosty mechanizm. Spójrz na ten prosty formularz:
Widzisz tutaj pomocnicze tagi: asp-for i asp-validation-for. W wynikowym HTMLu będzie to wyglądało mniej-więcej tak:
<div class="form-group">
<label for="email">Podaj swój email:</label>
<input class="form-control" type="email" data-val="true" data-val-email="The Email field is not a valid e-mail address." data-val-required="The UserName field is required." id="UserName" name="UserName" value="">
<span class="text-danger field-validation-valid" data-valmsg-for="UserName" data-valmsg-replace="true"></span>
</div>
Jak widzisz, tagi pomocnicze trochę tutaj nagrzebały w kodzie. Nagrzebały pod kątem Microsoftowej biblioteki jQuery Unobtrusive Validation. Ta biblioteka, można powiedzieć, „szuka” atrybutów data-val (skrót od „data validation”), których wartość jest ustawiona na true. Oznacza to, że takie pole podlega walidacji. Następnie tworzone są odpowiednie komunikaty, gdy walidacja się nie powiedzie:
data-val-email – komunikat dla atrybutu [EmailAddress]
data-val-required – komunikat dla atrybutu [Required]
Te komunikaty są później umieszczane w elemencie, który ma data-valmsg-for i data-valmsg-replace (true).
To się dzieje automatycznie – Microsoft porobił takie mechanizmy. Tutaj wchodzi interfejs IClientModelValidator. Zajmijmy się najpierw nim:
Implementacja IClientModelValidator
[AttributeUsage(AttributeTargets.Property | AttributeTargets.Field, AllowMultiple = false)]
public class CheckBoxCheckedAttribute : ValidationAttribute, IClientModelValidator
{
public void AddValidation(ClientModelValidationContext context)
{
if (context == null)
{
throw new ArgumentNullException(nameof(context));
}
MergeAttribute(context.Attributes, "data-val", "true");
MergeAttribute(context.Attributes, "data-val-chboxreq", "Nie zaznaczyłeś checkboxa!");
}
private static void MergeAttribute(IDictionary<string, string> attributes, string key, string value)
{
if (!attributes.ContainsKey(key))
{
attributes.Add(key, value);
}
}
}
context.Attributes to słownik, który zawiera atrybuty dodane już do pola
Użycie atrybutu
Utworzyliśmy klasę CheckBoxCheckedAttribute, implementując interfejs IClientModelValidator. Teraz tak. Tag pomocniczy asp-for sprawdza wszystkie walidacje na danym polu, czyli jeśli mamy model:
class RegisterUserViewModel
{
[CheckBoxChecked]
public bool TermsAndConditions { get; set; }
}
wtedy asp-for weźmie wszystkie klasy atrybutów dla danego pola, które implementują interfejs IClientModelValidator i uruchomi metodę AddValidation.
To, co „zwróci” ta metoda, będzie dopisane do pola . Jak widzisz, zadaniem metody AddValidation jest właściwie tylko odpowiednie dodanie atrybutów do polainput, a więc:
data-val usatwione na true
data-val-chboxreq – którego wartością jest odpowiedni komunikat. Czyli teraz dopiszemy checkboxa w formularzu:
Zauważ, że klasa CheckBoxCheckedAttribute dodała w metodzie AddValidation te dwa atrybuty (data-val i data-val-chboxreq), które są wymagane do poprawnego działania walidacji po stronie klienta.
Oczywiście nie musisz pisać nazywać tego data-val-chboxreq. Ważne, żeby było data-val- i w miarę unikalna, jednoznaczna końcówka. Równie dobrze mógłbyś napisać: data-val-checkbox-zaznaczony i sprawdzać później wartość tego atrybutu.
Czyli podsumowując tę część:
Tag asp-for powoduje wywołanie metody AddValidationz interfejsu IClientModelValidator, która jest odpowiedzialna za dodanie atrybutów walidacyjnych do pola . Oczywiście nic nie stoi na przeszkodzie, żebyś dodał tam jeszcze inne atrybuty. Pamiętaj, że musisz atrybut implementujący IClientModelValidator dodać do odpowiedniego pola w swoim modelu (viewmodelu).
OK, skoro już wiesz do czego służy IClientModelValidator, to teraz polecimy dalej. Pierwsza część walidacji jest zrobiona. Teraz druga. JavaScript.
Walidacja w JavaScript
Jak już mówiłem, Microsoft ma tą swoją bibliotekę jQuery Unobtrusive Validation, która działa razem z jQuery Validation.
Ten fragment kodu możesz dodać albo tylko na stronie z formularzem, albo lepiej – w widoku _ValidationScriptsPartial. Wtedy będzie dostępny zawsze, gdy dodajesz jakąś walidację:
<script>
$.validator.addMethod("chboxreq", function (value, element, param) {
if (element.type != "checkbox")
return false;
return element.checked;
});
$.validator.unobtrusive.adapters.addBool("chboxreq");
</script>
najpierw dodajemy metodę do walidatora jQuery.
metoda ma zostać uruchomiona, gdy trafi na atrybut data-val-chboxreq. Zauważ, że w parametrze podajemy tylko tę ostatnią część – chboxreq.
funkcja przyjmuje 3 parametry – wartość (atrybut value elementu HTML), element – czyli element HTML i param – dodatkowy parametr.
Jak widzisz funkcja walidująca jest bardzo prosta – najpierw jest sprawdzenie, czy element jest checkboxem, potem funkcja sprawdza, czy checkbox jest zaznaczony.
Aby to wszystko zadziałało, trzeba jeszcze dodać ten „adapter”, używając $.validator.unobtrusive.adapters Nie będę tutaj opisywał walidatorów w jQuery, bo:
Mógłbym zaciemnić obraz
Nie znam się na nich
Możesz sam wyszukać w dokumentacjach, jeśli będziesz chciał robić jakieś dziwne rzeczy.
I teraz pewna uwaga, o której pisałem na początku. Ten cały kod nie chciał mi kiedyś zadziałać i męczyłem się chyba 2 godziny zanim wpadłem dlaczego (oczywiście nie byłbym sobą, gdybym nie zgłosił tego do Microsoftu :)). Ten kod nie zadziała z poziomu TypeScript. Nie wiem, czemu. Po prostu MUSI być bezpośrednio w JavaScript.
Walidacja po stronie serwera
Aby wszystko zadziałało poprawnie, musimy dodać jeszcze walidację po stronie serwera. Zauważ, że walidacja kliencka została zrobiona w JavaScript. Walidacja po stronie serwera odbywa się już bezpośrednio w klasie CheckBoxCheckedAttribute. Wystarczy przesłonić metodę IsValid:
public override bool IsValid(object value)
{
return (value is bool && (bool)value);
}
To tyle.
Komunikaty o błędach
Teraz mała uwaga na koniec. Klasa ValidationAttribute zawiera już pewne mechanizmy, które pomagają. Jak już wiesz, każdy atrybut walidacyjny z .NET ma pewne właściwości: ErrorMessage, ErrorMessageResourceName, ErrorMessageResourceType… Bierze się to właśnie z klasy ValidationAttribute. Zatem klasa CheckBoxCheckedAttribute też ma te właściwości. Więc możesz napisać:
class RegisterUserViewModel
{
[CheckBoxChecked(ErrorMessage = "Musisz zaakceptować warunki")]
public bool TermsAndConditions { get; set; }
}
lub (w aplikacji wielojęzycznej):
class RegisterUserViewModel
{
[CheckBoxChecked(ErrorMessageResourceName = nameof(LangRes.ValidationError_AcceptTerms), ErrorMessageResourceType = typeof(LangRes))]
public bool TermsAndConditions { get; set; }
}
Jeśli nie wiesz, jak zrobić lokalizację do swojego programu, sprawdź ten artykuł
wOczywiście musisz pamiętać, żeby w metodzie AddValidation zwrócić poprawny komunikat. I teraz uwaga. Niezależnie od tego, czy posłużysz się ErrorMessage, czy ErrorMessageResourceName i ErrorMessageResourceType, klasa ValidationAttribute przechowa już dla Ciebie konkretny komunikat. Trzyma to we właściwości ErrorMessageString, a więc zamiast komunikatu bezpośrednio w kodzie powinieneś się posłużyć tą właściwością:
public void AddValidation(ClientModelValidationContext context)
{
if (context == null)
{
throw new ArgumentNullException(nameof(context));
}
MergeAttribute(context.Attributes, "data-val", "true");
MergeAttribute(context.Attributes, "data-val-chboxreq", ErrorMessageString);
}
Przejdźmy na kolejny poziom
Jeśli nie do końca rozumiesz ten artykuł albo chcesz czegoś więcej, przy okazji napisałem jak zrobić walidator do sprawdzania rozmiaru przesyłanego pliku. Zachęcam do zapoznania się z tym artykułem o przesyłaniu plików w Razor, Blazor i WebApi.
To tyle. Jeśli masz jakieś wątpliwości lub znalazłeś błąd w artykule, podziel się w komentarzu.
Ten artykuł opisuje czym jest walidacja danych i jak ją zastosować poprawnie w .Net. Jeśli trafiłeś na ten artykuł, szukając, jak w razor zrobić wymaganego checkboxa, to sprawdź ten artykuł.
Na szybko
Atrybuty walidacyjne w modelu:
Porównanie dwóch pól – [Compare(„InnePole”)]
Maksymalna ilość znaków – [MaxLength(50)]
Minimalna ilość znaków – [MinLength(10)]
Sprawdzenie wieku – [Range(Minimum = 18)]
Pole wymagane – [Required]
Trochę teorii
Czym jest walidacja danych
Walidacja to po prostu sprawdzenie poprawności danych podanych przez użytkownika. Walidacja jest ściśle powiązana z jakimś formularzem, który użytkownik wypełnia. Może być to po prostu rejestracja nowego konta. Wtedy taka walidacja polega na sprawdzeniu, czy użytkownik wypełnił wszystkie wymagane pola, czy jego hasło i nazwa użytkownika spełniają nasze założenia (np. musi być wielka litera albo nazwa użytkownika musi być adresem e-mail) no i oczywiście, czy zaakceptował naszą politykę prywatności i regulamin 🙂
Walidacja danych jest potrzebna żeby nie dopuścić do sytuacji, w której w bazie danych znajdują się głupoty. Zapewnia też większą spójność danych, a także chroni przed pewnymi atakami.
Także każdy formularz wypełniany przez użytkownika powinien być zwalidowany. Pamiętaj, że użytkownik może wpisać wszystko, co mu się podoba. To na Tobie w pewnym sensie leży odpowiedzialność sprawdzenia, czy to co wpisał ma sens.
Są dwa „tryby” walidacji. Po stronie serwera i po stronie klienta.
Walidacja danych po stronie klienta
Walidacja po stronie klienta następuje przed wysłaniem danych do serwera. Czyli np. w przeglądarce internetowej lub aplikacji. Mamy formularz rejestracji, użytkownik wciska guzik „Rejestruj” i w tym momencie musimy sprawdzić poprawność danych. Jeśli dane nie są poprawne, wtedy pokazujemy komunikat. Jeśli uznamy, że są ok – wysyłamy je do serwera. W aplikacjach internetowych takim sprawdzeniem zajmuje się np. JavaScript. Czyli musimy napisać odpowiedni kod w tym… bleee… języku, który sprawdzi nam poprawność wpisanych danych.
Walidacja danych po stronie serwera
No i tutaj mamy to, co backendowcy lubią najbardziej. Czyli dostajemy dane od klienta i za chwilę wrzucimy je do bazy danych. Ale, ale… Jeden z moich profesorów na studiach mawiał:
„Kto szybko daje, ten dwa razy daje”
Zatem nie możemy do końca ufać danym, które otrzymaliśmy. Musimy sprawdzić je drugi raz. I tu wchodzi walidacja danych po stronie serwera – dopiero jeśli tutaj upewnimy się, że wszystko jest ok, możemy wbić dane do bazy lub zrobić z nimi coś innego.
Czyli krótko podsumowując, proces powinien wyglądać tak:
Użytkownik wklepuje dane i wciska guzik „OK”
Następuje walidacja po stronie klienta (JavaScript)
Jeśli walidacja jest ok, to wysyłamy dane do serwera, jeśli nie, to mówimy użytkownikowi, że coś zje… źle wprowadził
Po stronie serwera odbieramy dane i SPRAWDZAMY JE JESZCZE RAZ
Jeśli dane są ok, to wbijamy je do bazy danych i odpowiadamy klientowi: „Ok, wszystko się udało”. Jeśli dane są złe, odpowiadamy: „Hola hola, coś tu źle wprowadziłeś”.
Taka podwójna walidacja danych nie jest w prawdzie konieczna. Możesz tworzyć systemy jak Ci się podoba. Ale jeśli chcesz ograniczyć dziury, błędy i podatności na ataki w swoim systemie, podwójna walidacja jest obowiązkiem. Pamiętaj, że nie zawsze dostaniesz dane z własnej aplikacji. Czasem ktoś po prostu wyśle „na pałę”. Dlatego walidacja po stronie serwera jest konieczna. Nie opłaca się też nikomu wysyłać na serwer danych, które wiadomo, że są niepoprawne. Bardziej opłaca się sprawdzić je po stronie klienta przed wysłaniem.
Trochę praktyki
Walidacja danych w .NetCore
Na szczęście .NetCore ma pewne mechanizmy do walidacji danych, które teraz pokrótce Ci pokażę. Walidacja w .NetCore składa się z trzech etapów:
odpowiednie przygotowanie modelu
wywołanie walidacji po stronie klienta
wywołanie walidacji po stronie serwera
Przygotowanie modelu
Załóżmy, że mamy klasę, która przechowuje dane rejestracyjne użytkownika (model), możemy jej poszczególne właściwości ubrać w konkretne atrybuty. To jest tzw. „annotation validation„, czyli walidacja obsługiwana za pomocą „adnotacji”.
Spójrzmy na tę „gołą” klasę:
class RegisterUserViewModel
{
public string UserName { get; set; }
public string Password { get; set; }
public string RepeatedPassword { get; set; }
}
Musimy się upewnić, że:
wypełniona jest nazwa użytkownika
wypełnione jest hasło
podane hasła są identyczne
Za pierwsze 2 założenia odpowiada atrybut Required
//using System.ComponentModel.DataAnnotations;
class RegisterUserViewModel
{
[Required]
public string UserName { get; set; }
[Required]
public string Password { get; set; }
[Required]
public string RepeatedPassword { get; set; }
}
Teraz, gdy uruchomimy proces walidacji, sprawdzi on te pola. To wygląda mniej więcej tak:
Walidator: Cześć obiekcie, jakie masz pola? Obiekt: No hej, mam UserName, Password i PasswordRepeated Walidator: Ok, jakie masz atrybuty walidacyjne na polu UserName? Obiekt: Required Walidator: Hej wielki walidatorze Required! Czy pole UserName w danym obiekcie spełnia Twoje założenia?
Wtedy walidator Required sprawdza. Taki walidator mógłby wyglądać w taki sposób (zakładając, że byłby tylko dla stringa, ale jest dla innych typów też):
return !string.IsNullOrWhitespace(value);
Walidator zrobi analogiczne sprawdzenie przy pozostałych polach.
Ok, teraz w drugim kroku chcemy, żeby pole UserName było poprawnym adresem e-mail. Można się do tego posłużyć atrybutem…. EmailAddress:
class RegisterUserViewModel
{
[Required]
[EmailAddress]
public string UserName { get; set; }
[Required]
public string Password { get; set; }
[Required]
public string RepeatedPassword { get; set; }
}
(jak widzisz, jedno pole może mieć wiele atrybutów walidacyjnych)
Walidacja adresu e-mail
Poświęciłem na to osobny akapit (chociaż zastanawiam się nad artykułem). Zasadniczo wiemy, jakie są poprawne adresy e-mail:
a@b.c
jkowalski@gmail.com
user@serwer.poczta.pl
Natomiast niepoprawnymi mogą być:
@@@@
jkowalski(at)gmail.com
pitu-pitu@pl
Po staremu
Do wersji .NetFramework 4.7.2 atrybut EmailAddress działał tak, że sprawdzał adres e-mail za pomocą wyrażeń regularnych. Wyrażenia regularne mają jedną mała wadę – są stosunkowo drogie, jeśli chodzi o zasoby – wolne. To jest pewna furtka dla ataku DoS (denial of service). Atak ten polega na przeciążeniu serwera, żeby nie służył już innym użytkownikom.
Okazało się, że duża ilość stringów, a co gorsza dużych stringów, przepychana przez ten walidator, może właśnie mieć takie działanie. Wyrażenia regularne żrą sporo, więc duża ilość dużych stringów może zablokować serwer. Dlatego Microsoft zmienił trochę sposób działania tego walidatora.
Po nowemu
każdy string, który ma tylko jedną małpę i nie jest ona ani na końcu, ani na początku jest poprawnym adresem e-mail, czyli:
a@b – poprawny
ja@cie.krece – poprawny
@blbla – niepoprawny
abc@ – niepoprawny
No i tutaj właśnie zapala się lampka: „a@b” ma być poprawnym e-mailem? No właśnie nie do końca. Ale to sprawdzenie miało być szybkie. Jest szybkie. Ale skoro jest szybkie, to jest też proste. Zasadniczo sprawdza czy podany string MOŻE być poprawnym adresem e-mail.
Można to jednak zmienić. W pliku appsettings trzeba dodać taką linijkę:
Wtedy sprawdzenie adresu e-mail będzie po staremu za pomocą wyrażeń regularnych. Stosuj tylko wtedy, kiedy wiesz co robisz. W gruncie rzeczy to użytkownik powinien podać Ci swój właściwy adres e-mail.
Sprawdzenie hasła
Ok, skoro załatwiliśmy już e-mail, sprawdźmy teraz czy użytkownik podał dwa razy to samo hasło, czy może coś znowu schrzanił:
class RegisterUserViewModel
{
[Required]
[EmailAddress]
public string UserName { get; set; }
[Required]
public string Password { get; set; }
[Required]
[Compare("Password")]
public string RepeatedPassword { get; set; }
}
Jak widzisz odpowiada za to atrybut Compare. W parametrze (otherProperty) podajemy nazwę pola z tej klasy, z którą ma zostać to pole porównane. Tutaj „Password”. Czyli porównamy pole „RepeatedPassword” z polem „Password”. Tylko tutaj też uwaga. Jeśli chodzi o porównanie dwóch stringów, to wykorzystywana jest tu metoda Equals z klasy string. Ta metoda nie jest wrażliwa na ustawienia językowe. Tzn. że w pewnych językach i w pewnych warunkach może stwierdzić, że dwa różne stringi są takie same lub dwa takie same stringi są różne.
Sprawdzenie wieku
Teraz dodatkowo możemy upewnić się, czy użytkownik jest pełnoletni. Do tego może posłużyć atrybut Range, który oznacza, że wartość powinna być z konkretnego zakresu. A więc użytkownik może na przykład podać swój wiek:
class RegisterUserViewModel
{
[Required]
[EmailAddress]
public string UserName { get; set; }
[Required]
public string Password { get; set; }
[Required]
[Compare("Password")]
public string RepeatedPassword { get; set; }
[Required]
[Range(18, 50)]
public int Age { get; set; }
}
W powyższym przykładzie sprawdzamy, czy wiek użytkownika jest między 18 a 50 lat. Atrybut Range musi być zastosowany z typem int lub datą. Przy czym stosowanie go z datą nie ma raczej uzasadnienia, ponieważ musielibyśmy wklepać ją na sztywno, co może przysporzyć sporych problemów w przyszłości. Dlatego stosuj Range raczej do zmiennych int. Możesz podać też samo minimum lub maksimum:
class RegisterUserViewModel
{
[Required]
[EmailAddress]
public string UserName { get; set; }
[Required]
public string Password { get; set; }
[Required]
[Compare("Password")]
public string RepeatedPassword { get; set; }
[Required]
[Range(Minimum = 18)]
public int Age { get; set; }
}
(analogicznie istnieje właściwość Maximum)
Pewnie chciałoby się zapytać – jak atrybut range traktuje swoje minimum i maksimum. Czy od minimum, czy minimum jest wykluczone? Możesz sam to sprawdzić, pisząc odpowiedni kod, do czego Cię zachęcam 🙂 Jeśli jednak trafiłeś tutaj tylko po to, żeby dowiedzieć się tej konkretnie rzeczy, to już mówię – minimum i maksimum są dopuszczone. Czyli minimum jest pierwszą liczbą, która przechodzi sprawdzenie, a maksimum – ostatnią.
Jest jeszcze kilka atrybutów, które mogą Ci się przydać. Każdy z nich jest opisany na stronach Microsoftu:
Generalnie w .NetCore nie ma chyba nic prostszego. Robi się to w kontrolerze (to jedna z możliwości) – niezależnie od tego, czy pracujesz nad WebApi, czy nad stroną (Razor Views). Działa to tak:
//przykład dla RazorView, dla WebAPI jest to analogicznie
public class MyController: Controller
{
[HttpPost]
public async Task<IActionResult> RegisterUser(RegisterUserViewModel model)
{
if(!ModelState.IsValid)
return BadRequest();
}
}
I w zasadzie to wszystko. Kontroler ma taki obiekt ModelState, który przechowuje informacje na temat poprawności przekazanego modelu. Właściwość IsValid określa, czy model jest poprawnie wypełniony (true), czy nie (false). Możesz też poznać wszystkie błędy obecne w modelu, ale uwaga. Na tym etapie (tuż przed dodaniem na serwer) raczej nie informowałbym użytkownika o szczegółowych błędach (chociaż to zależy od Ciebie – Ty wiesz co klient usiłuje zrobić i jak istotne i tajne powinny być dane w każdym przypadku).
UWAGA! .NET8 automatycznie sprawdza poprawność modelu w klasie kontrolera dziedziczącej po ControllerBase.
Jesteśmy w końcu na serwerze, a ktoś te dane na serwer musiał wysłać. Więc albo zrobił to źle klient – wtedy musimy poprawić klienta (bo np. zabrakło walidacji po stronie klienta), albo ktoś próbuje nam w jakiś sposób zaszkodzić. Przy WebAPI jest jeszcze inna opcja – ktoś po prostu tworzy aplikację i nie poradził sobie z poprawnym wysłaniem danych… No cóż… Musi doczytać w dokumentacji.
Walidacja w RazorPages wygląda też analogicznie. Tutaj obiekt ModelState też istnieje z tym, że w klasie PageModel, np:
public class MyPage: PageModel
{
public async Task<IActionResult> OnPostAsync()
{
if (!ModelState.IsValid)
return BadRequest();
return Page();
}
}
Walidacja danych po stronie klienta
Tutaj kwestia jest też zasadniczo prosta, jeśli chodzi przynajmniej o walidację typową – dostępną w .NetCore. Gdzieś tam na początku mówiłem, że walidacja po stronie klienta wymaga JavaScriptu. I to niestety prawda. Na szczęście Microsoft stworzył taką bibliotekę jQuery unobtrusive validation. Ona jest stworzona w taki sposób, żeby współdziałać z widokami dzięki TagHelperom.
Pierwszy z nich masz raczej na „dzień dobry” w widoku _Layout.cshtml, pozostałe w _ValidationScriptsPartial.cshtml. Więc domyślnie wystarczyłoby, żebyś dodał na początku strony:
<partial name="_ValidationScriptsPartial" />
Walidacja formularza
Na początek przekazać do widoku konkretny model:
@model RegisterUserViewModel
Następnie musimy zwalidować konkretne pola w formularzu, np:
Powyżej masz fragment formularza rejestracyjnego. Jeśli nie znasz bootstrap, to tłumaczę pokrótce: pierwszy div – tworzy „grupę” kontrolek – w tym przypadku label, input i jakiś span (Etykietę, pole do wprowadzenia danych i jakiś span).
Etykieta to po prostu tekst zachęty: „Podaj swój email:”.
asp-for
Teraz pole do wprowadzenia danych – input. Tutaj pojawiła się nowa rzecz – tag pomocniczy „asp-for”. Jeśli wpiszesz sobie asp-for, to Intellisense pokaże Ci wszystkie pola w Twoim modelu. Skąd wie, co jest Twoim modelem? No przecież mu pokazałeś na początku widoku:
@model RegisterUserViewModel
asp-for tworzy pewnego rodzaju powiązanie między kontrolką HTML, a polem w Twoim modelu. Czyli to, co użytkownik wpisze do tej kontrolki, AUTOMAGICZNIE trafi do pola UserName w Twoim modelu. Niczego nie musisz przepisywać. No złoto…
Ale to nie wszytko. Zapewnia to też walidację. Czyli automagicznie zostanie sprawdzone Twoje pole pod kątem poprawności (w tym wypadku Required i EmailAddress).
Komunikaty o błędach
Jeśli walidacja przejdzie, to formularz zostanie wysłany, jeśli nie, no to jakoś użytkownikowi wypadałoby powiedzieć, że znowu coś schrzanił. I od tego mamy ten tajemniczy SPAN.
Zauważ na początek jedną rzecz – span ma tag otwarcia i zamknięcia. Nie możesz napisać tak:
<span asp-validation-for... />
bez tagu zamknięcia coś może nie zadziałać (może być różnie na różnych wersjach). Więc musi być tag zamknięcia.
Ten SPAN wyświetli informacje, jeśli pole zostanie błędnie wypełnione (nie przejdzie walidacji). Tag „asp-validation-for” mówi po prostu dla jakiego pola ma pokazać się informacja o błędzie. Żeby nie zrobić użytkownikowi mindfucka, podaliśmy tutaj pole UserName. Klasa text-danger to jest po prostu bootstrapowa klasa, która powoduje, że wyświetlony tekst będzie w kolorze czerwonym.
Czyli podsumowując:
label – etykieta dla pola, mówiąca użytkownikowi co ma wpisać
input z tagiem asp-for – pole do wpisania
span z tagiem asp-validation-for – informacja w przypadku błędu.
No właśnie, ale jaka informacja? .NetCore pokaże po prostu domyślne info takie, jakie zaprogramowali w Microsofcie. Ale MOŻESZ ustawić własne powiadomienia. Wróćmy do modelu:
class RegisterUserViewModel
{
[Required(ErrorMessage="Nie, nie, nie. To pole MUSISZ wypełnić")]
[EmailAddress(ErrorMessage="A takiego! Nie podałeś prawidłowego e-maila")]
public string UserName { get; set; }
[Required]
public string Password { get; set; }
[Required]
[Compare("Password")]
public string RepeatedPassword { get; set; }
[Required]
[Range(Minimum = 18)]
public int Age { get; set; }
}
WSZYSTKIE atrybuty walidacyjne mają właściwość ErrorMessage, do której możesz wpisać komunikat błędu. Komunikaty mogą być też lokalizowane, np:
I teraz tak. ErrorMessageResourceType to jest Twój typ z zasobami językowymi, który posiada klucz Validation_RequiredField – ten klucz, który używasz. Jeśli nie wiesz, jak tworzyć wersje językowe, przeczytaj ten artykuł.
Jest jeszcze jeden sposób na pokazanie błędów w widoku. Możesz pokazać wszystkie błędy jeden po drugim, zamiast konkretnych błędów pod konkretnymi kontrolkami. Wystarczy zrobić to:
Wtedy komunikaty o błędach pojawią się na tym dodatkowym divie w postaci listy.
To właściwie już tyle jeśli chodzi o podstawy walidacji w .NetCore. Gratulacje, dotarłeś do końca 🙂
Jeśli masz jakieś wątpliwości lub znalazłeś błąd w artykule, podziel się w komentarzu.
Akceptacja regulaminu – wymagany checkbox
W każdym portalu, wymagana jest akceptacja regulaminu. I sprawa wydaje się prosta, ale z jakiegoś powodu nie jest (osobiście zgłosiłem to do MS wraz z rozwiązaniem). Przeczytaj ten artykuł, żeby dowiedzieć się, jak wymusić zaznaczenie checkboxa przez użytkownika w .NetCore
Obsługujemy pliki cookies. Jeśli uważasz, że to jest ok, po prostu kliknij "Akceptuj wszystko". Możesz też wybrać, jakie chcesz ciasteczka, klikając "Ustawienia".
Przeczytaj naszą politykę cookie